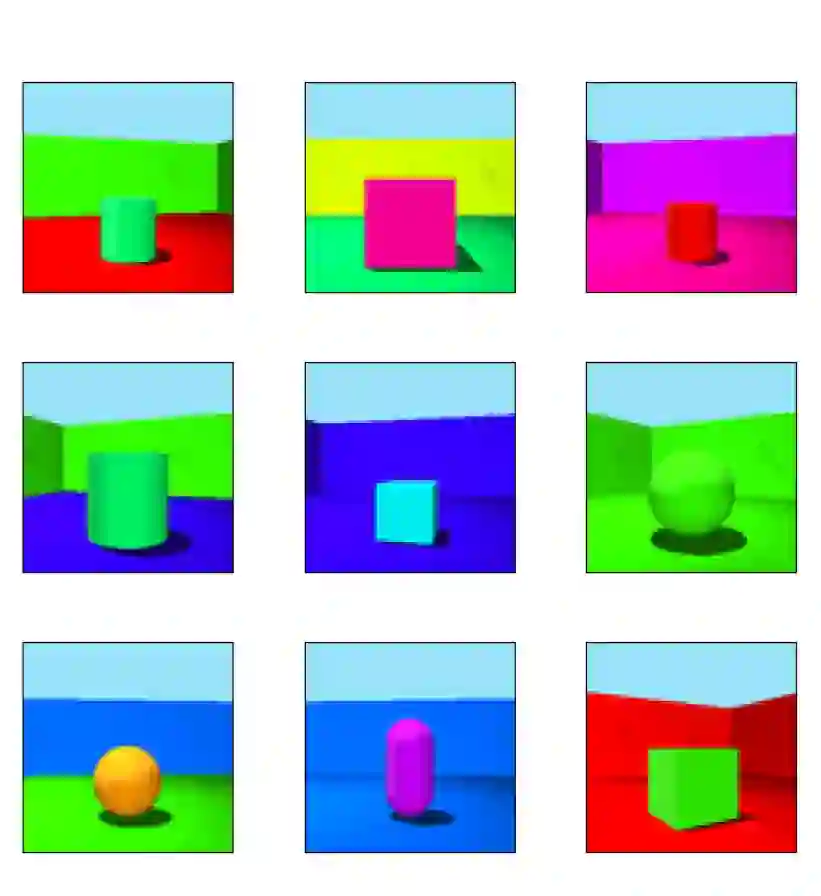
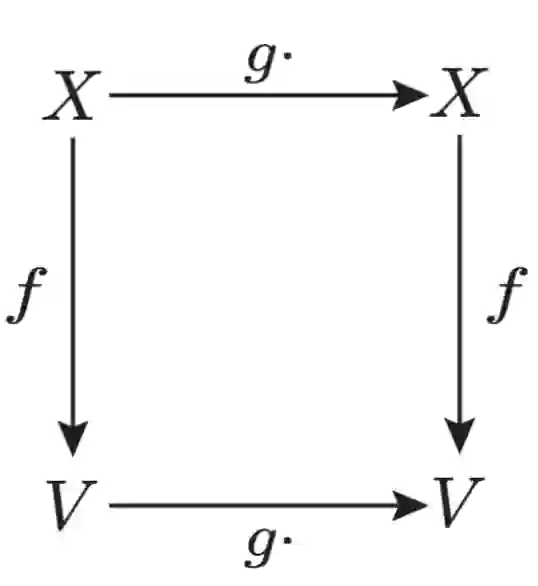
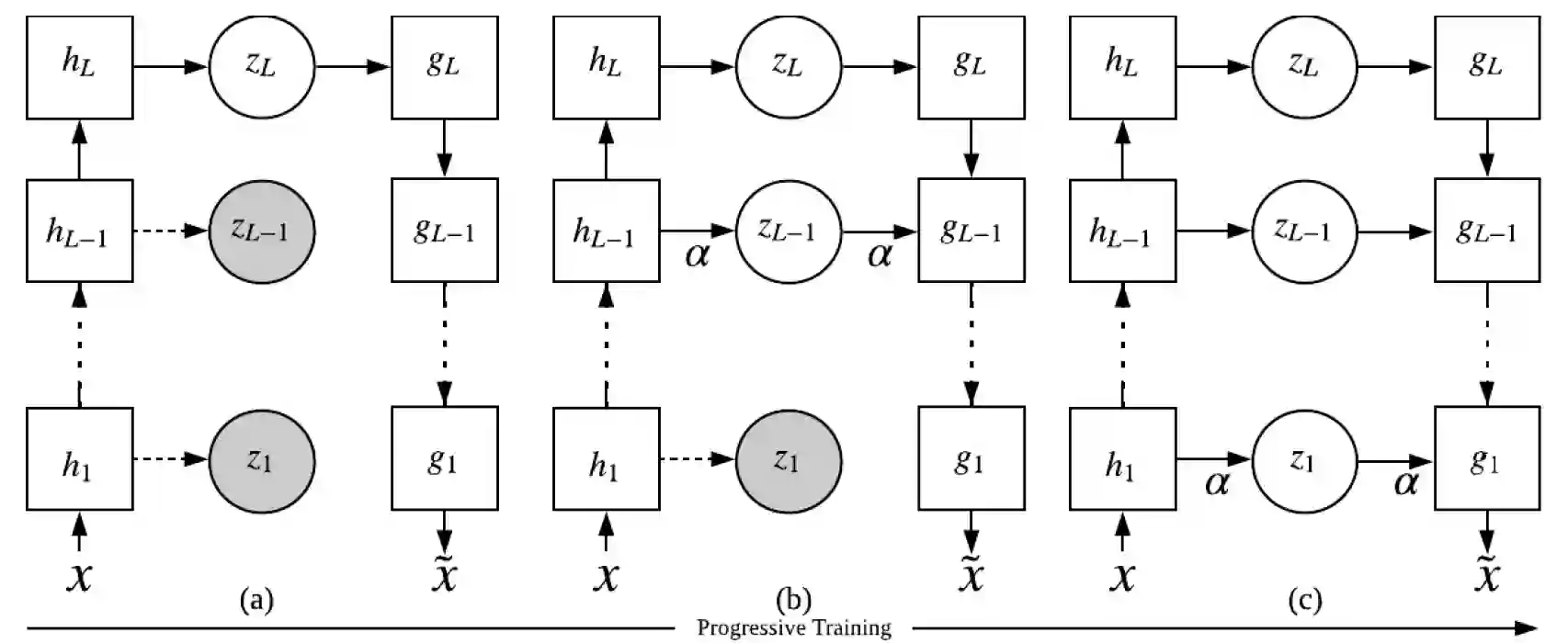
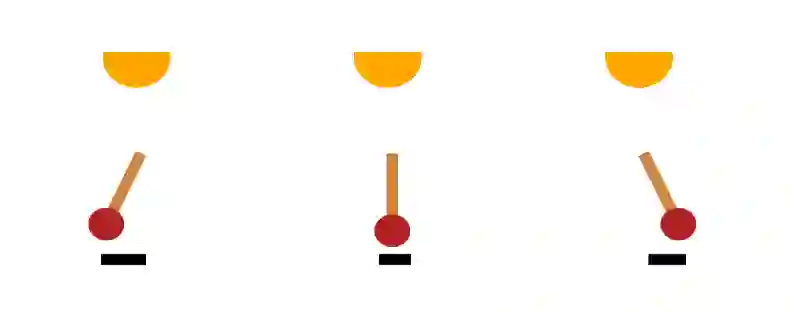Disentangled Representation Learning (DRL) aims to learn a model capable of identifying and disentangling the underlying factors hidden in the observable data in representation form. The process of separating underlying factors of variation into variables with semantic meaning benefits in learning explainable representations of data, which imitates the meaningful understanding process of humans when observing an object or relation. As a general learning strategy, DRL has demonstrated its power in improving the model explainability, controlability, robustness, as well as generalization capacity in a wide range of scenarios such as computer vision, natural language processing, data mining etc. In this article, we comprehensively review DRL from various aspects including motivations, definitions, methodologies, evaluations, applications and model designs. We discuss works on DRL based on two well-recognized definitions, i.e., Intuitive Definition and Group Theory Definition. We further categorize the methodologies for DRL into four groups, i.e., Traditional Statistical Approaches, Variational Auto-encoder Based Approaches, Generative Adversarial Networks Based Approaches, Hierarchical Approaches and Other Approaches. We also analyze principles to design different DRL models that may benefit different tasks in practical applications. Finally, we point out challenges in DRL as well as potential research directions deserving future investigations. We believe this work may provide insights for promoting the DRL research in the community.
翻译:解耦表示学习(DRL)旨在学习一种模型,能够以表示形式识别并分离可观测数据中隐藏的潜在因素。将变化的潜在因素分离为具有语义含义的变量,有助于学习可解释的数据表示,这模仿了人类在观察对象或关系时的有意义的理解过程。作为一种通用学习策略,DRL在提升模型可解释性、可控性、鲁棒性以及泛化能力方面展现出强大效能,广泛应用于计算机视觉、自然语言处理、数据挖掘等多个场景。本文从动机、定义、方法、评估、应用和模型设计等多个维度对DRL进行了全面综述。我们基于两种公认的定义(即直观定义和群论定义)讨论了DRL的相关工作,并将DRL的方法论进一步归纳为四类:传统统计方法、基于变分自编码器的方法、基于生成对抗网络的方法、层次化方法及其他方法。我们还分析了设计不同DRL模型的原则,这些模型可能在不同实际应用任务中发挥作用。最后,我们指出了DRL面临的挑战以及值得未来研究的潜在方向。我们相信,本工作将为推动DRL领域的研究提供启示。