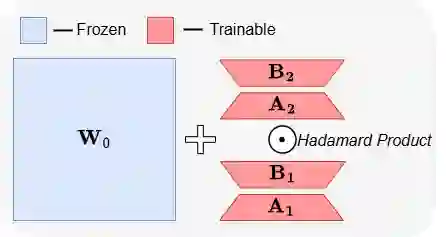
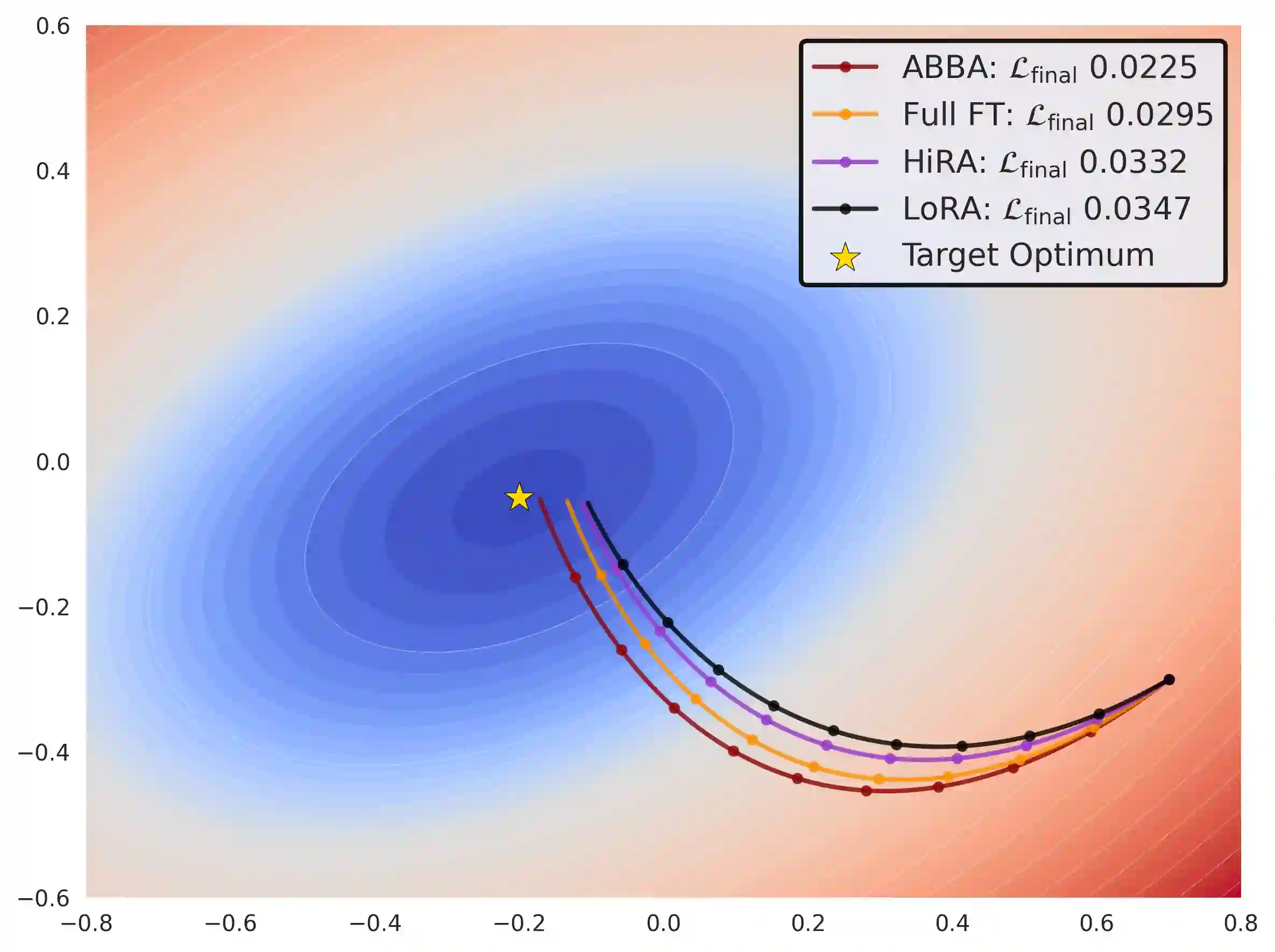
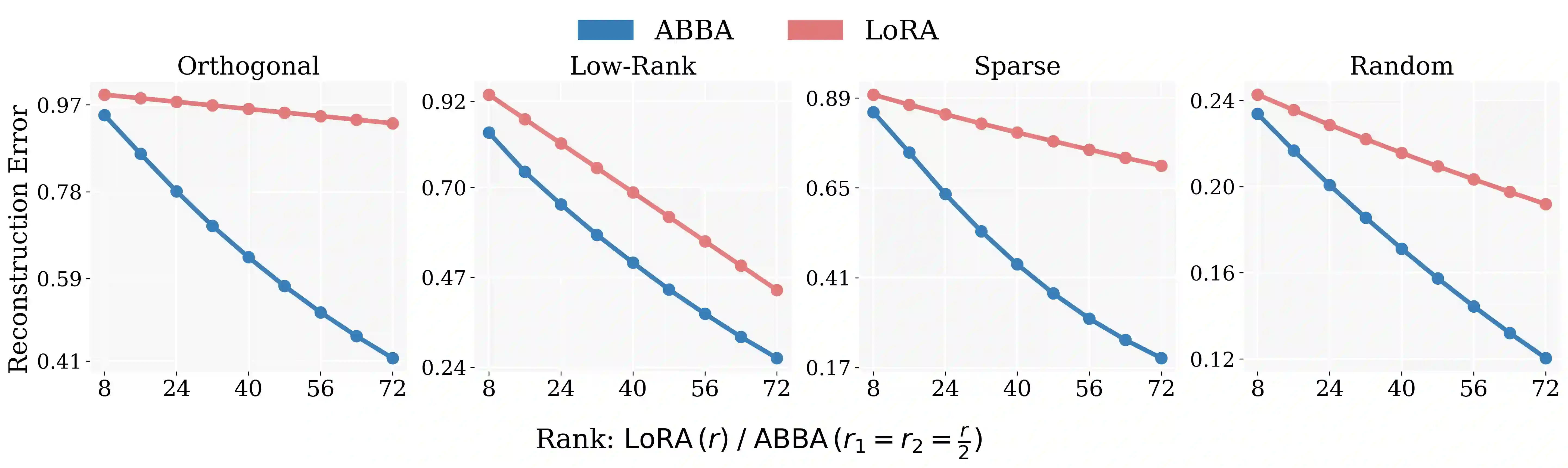
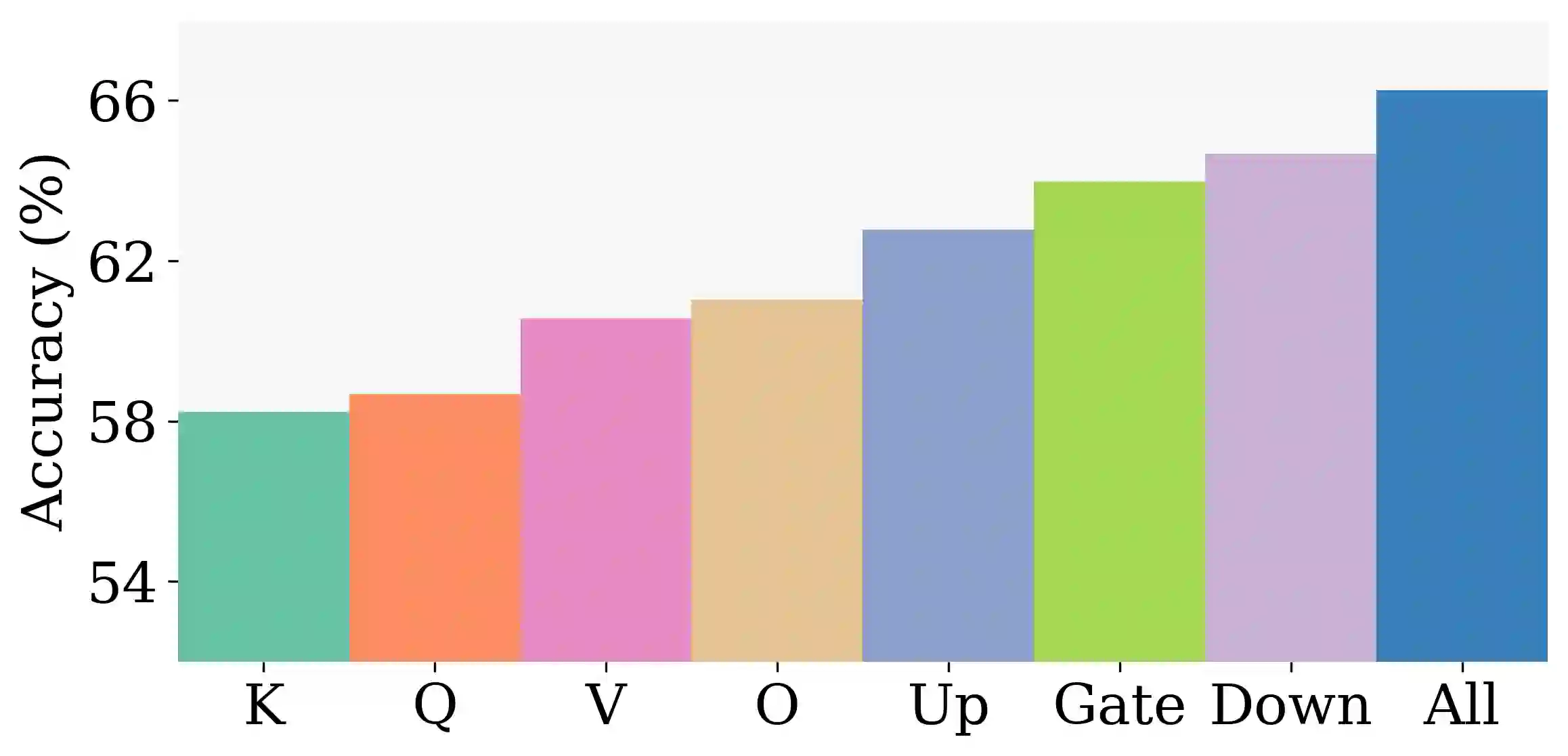
Large Language Models have demonstrated strong performance across a wide range of tasks, but adapting them efficiently to new domains remains a key challenge. Parameter-Efficient Fine-Tuning (PEFT) methods address this by introducing lightweight, trainable modules while keeping most pre-trained weights fixed. The prevailing approach, LoRA, models updates using a low-rank decomposition, but its expressivity is inherently constrained by the rank. Recent methods like HiRA aim to increase expressivity by incorporating a Hadamard product with the frozen weights, but still rely on the structure of the pre-trained model. We introduce ABBA, a new PEFT architecture that reparameterizes the update as a Hadamard product of two independently learnable low-rank matrices. In contrast to prior work, ABBA fully decouples the update from the pre-trained weights, enabling both components to be optimized freely. This leads to significantly higher expressivity under the same parameter budget, a property we validate through matrix reconstruction experiments. Empirically, ABBA achieves state-of-the-art results on arithmetic and commonsense reasoning benchmarks, consistently outperforming existing PEFT methods by a significant margin across multiple models. Our code is publicly available at: https://github.com/CERT-Lab/abba.
翻译:大型语言模型已在广泛任务中展现出强大性能,但如何高效地将其适配至新领域仍是关键挑战。参数高效微调方法通过引入轻量级可训练模块并保持大部分预训练权重固定来解决此问题。主流方法LoRA采用低秩分解建模更新,但其表达能力本质上受秩的约束。近期方法如HiRA试图通过引入与冻结权重的哈达玛积来提升表达能力,但仍依赖于预训练模型的结构。我们提出ABBA——一种新的参数高效微调架构,将更新重新参数化为两个独立可学习的低秩矩阵的哈达玛积。与先前工作不同,ABBA将更新与预训练权重完全解耦,使得两个组件均可自由优化。这能在相同参数预算下实现显著更高的表达能力,我们通过矩阵重构实验验证了该特性。实证结果表明,ABBA在算术与常识推理基准测试中取得了最先进的性能,在多个模型上均以显著优势持续超越现有参数高效微调方法。我们的代码已公开于:https://github.com/CERT-Lab/abba。