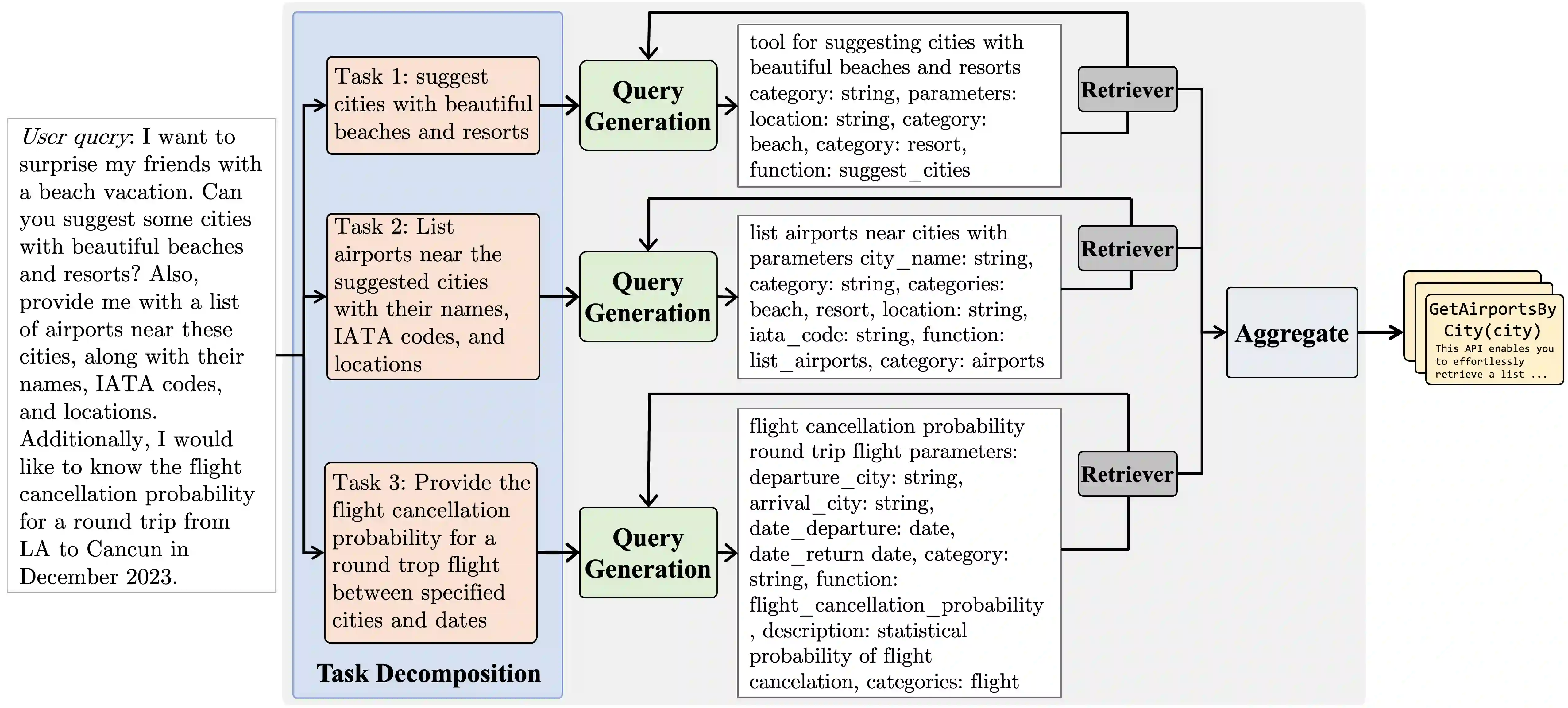
LLM agents operating over massive, dynamic tool libraries rely on effective retrieval, yet standard single-shot dense retrievers struggle with complex requests. These failures primarily stem from the disconnect between abstract user goals and technical documentation, and the limited capacity of fixed-size embeddings to model combinatorial tool compositions. To address these challenges, we propose TOOLQP, a lightweight framework that models retrieval as iterative query planning. Instead of single-shot matching, TOOLQP decomposes instructions into sub-tasks and dynamically generates queries to interact with the retriever, effectively bridging the semantic gap by targeting the specific sub-tasks required for composition. We train TOOLQP using synthetic query trajectories followed by optimization via Reinforcement Learning with Verifiable Rewards (RLVR). Experiments demonstrate that TOOLQP achieves state-of-the-art performance, exhibiting superior zero-shot generalization, robustness across diverse retrievers, and significant improvements in downstream agentic execution.
翻译:在大规模动态工具库上运行的大型语言模型(LLM)智能体依赖高效检索,然而标准的单次密集检索器在处理复杂请求时表现不佳。这些失败主要源于抽象用户目标与技术文档之间的语义鸿沟,以及固定维度嵌入在建模组合式工具构成时的有限表达能力。为解决这些挑战,我们提出了TOOLQP——一个将检索建模为迭代式查询规划的轻量级框架。与单次匹配不同,TOOLQP将指令分解为子任务,并动态生成查询与检索器交互,通过针对组合所需的具体子任务有效弥合语义差距。我们使用合成查询轨迹训练TOOLQP,并通过可验证奖励强化学习(RLVR)进行优化。实验表明,TOOLQP实现了最先进的性能,展现出卓越的零样本泛化能力、跨不同检索器的鲁棒性,以及在下游智能体执行任务中的显著提升。