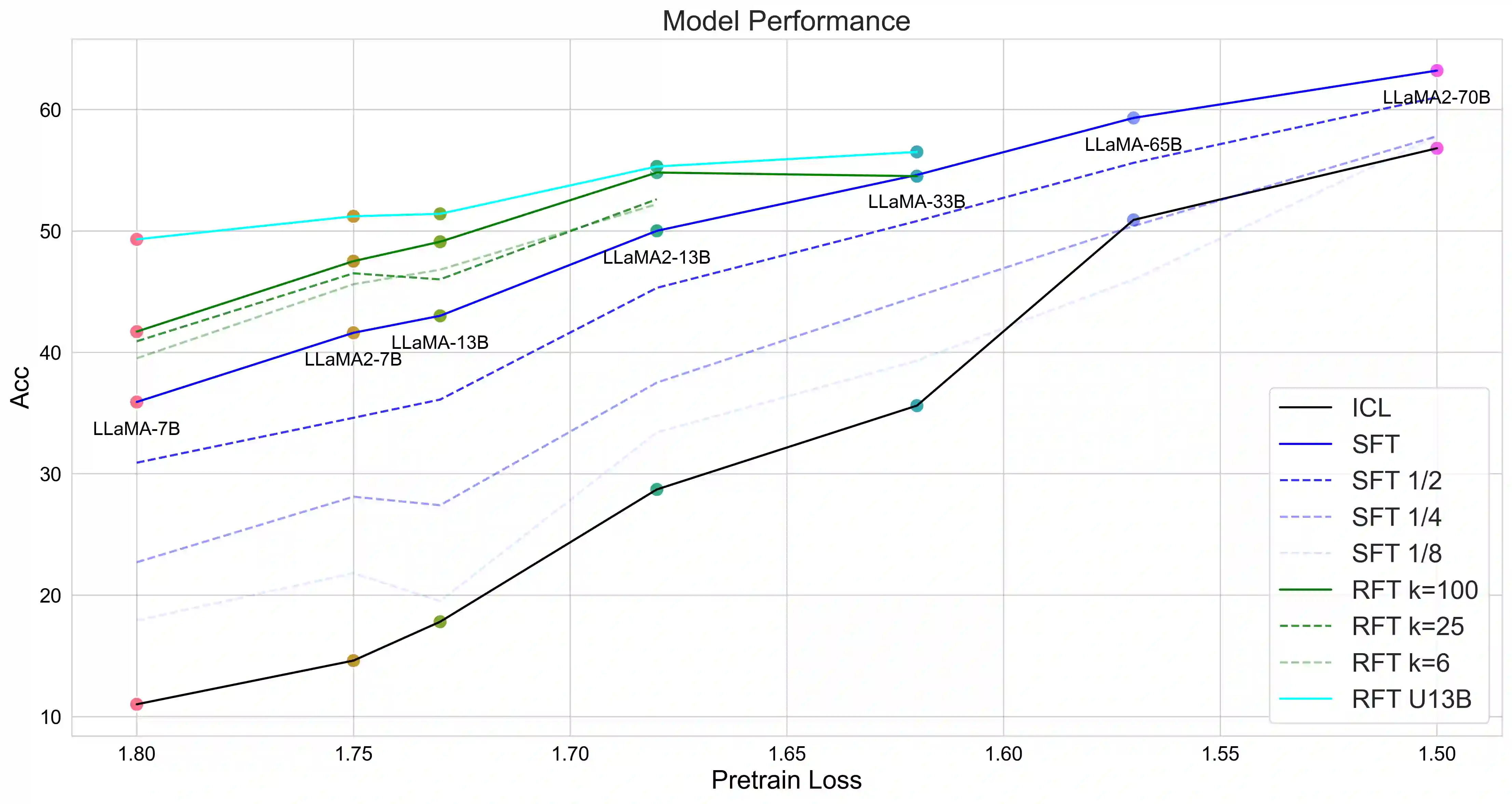
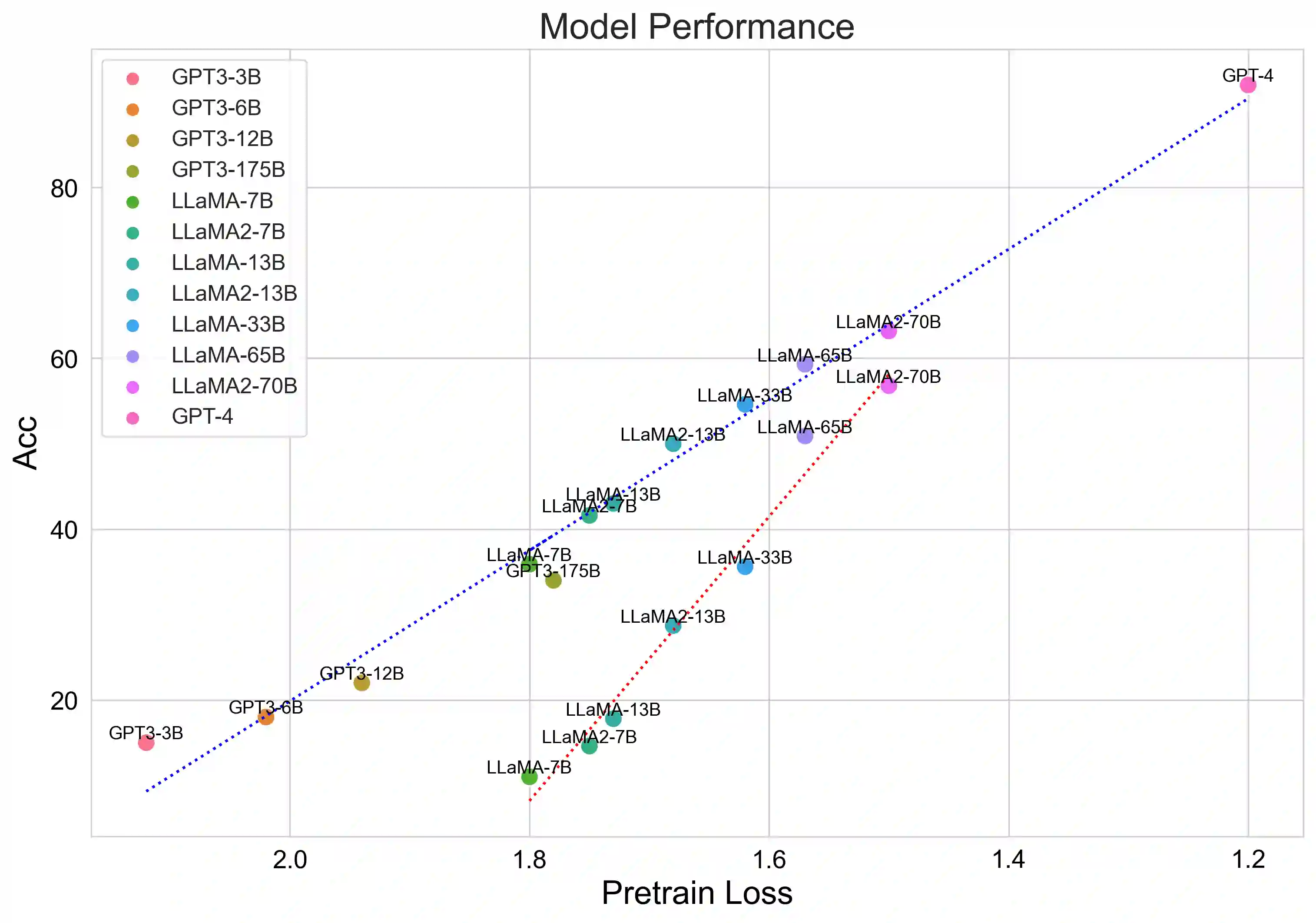
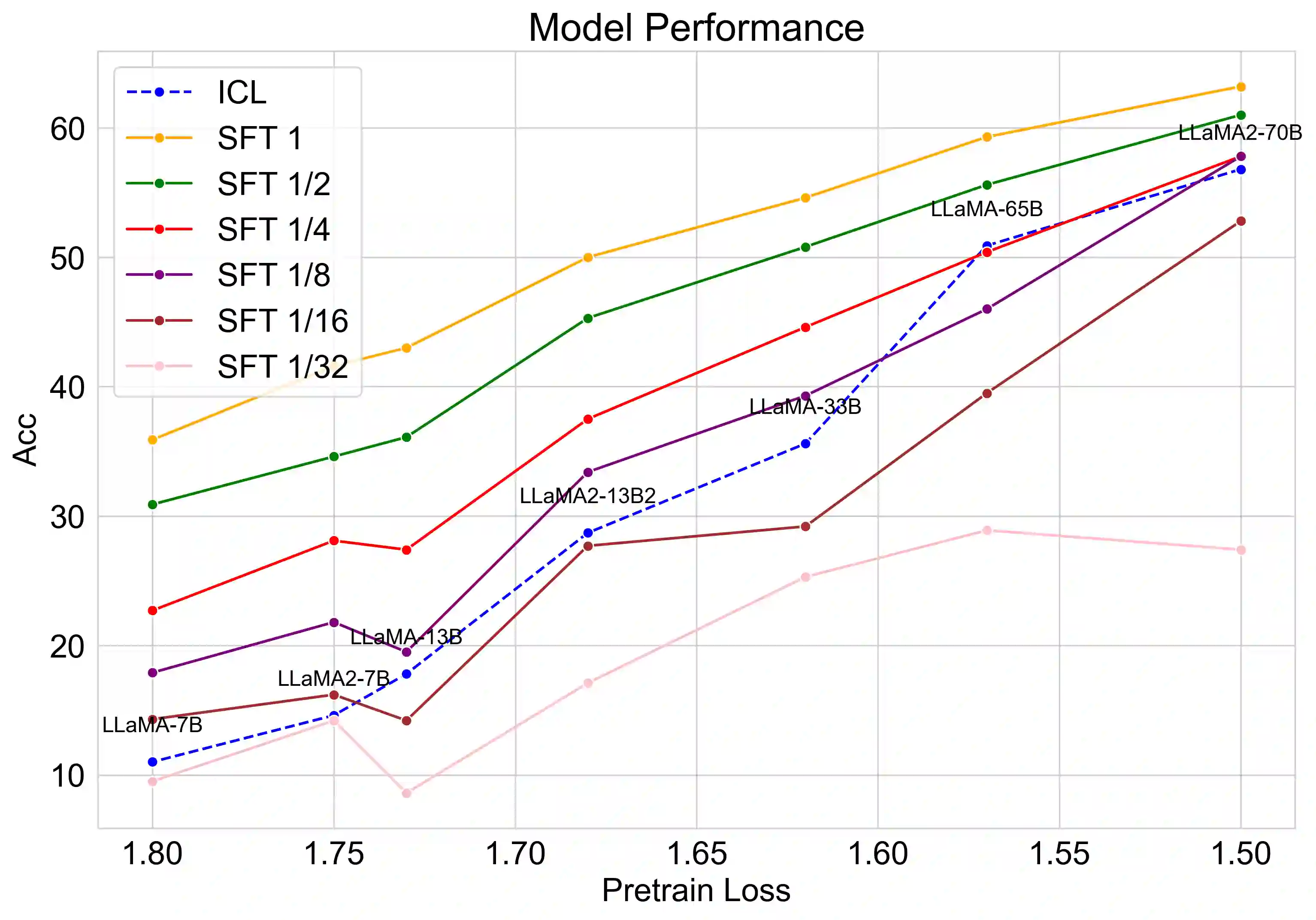
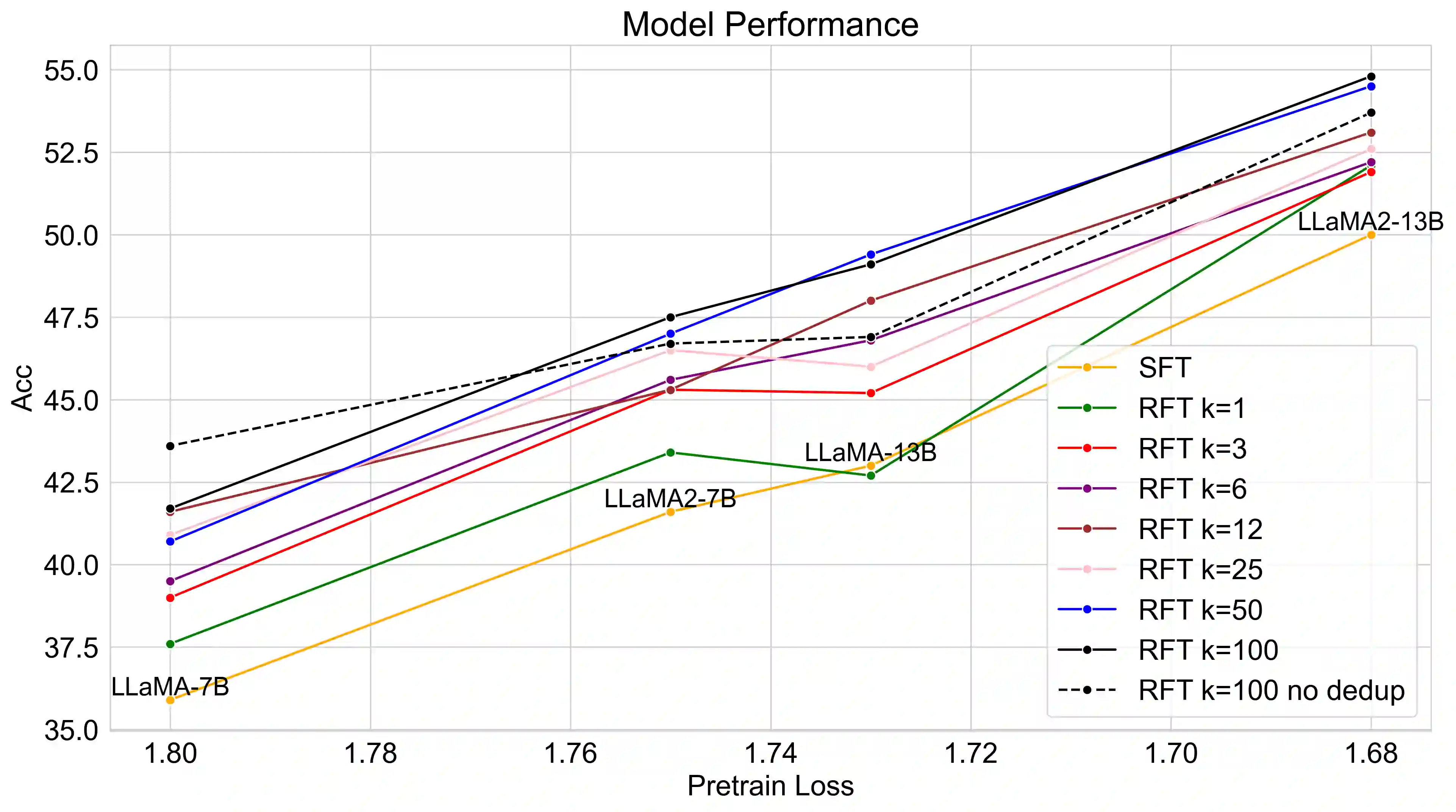
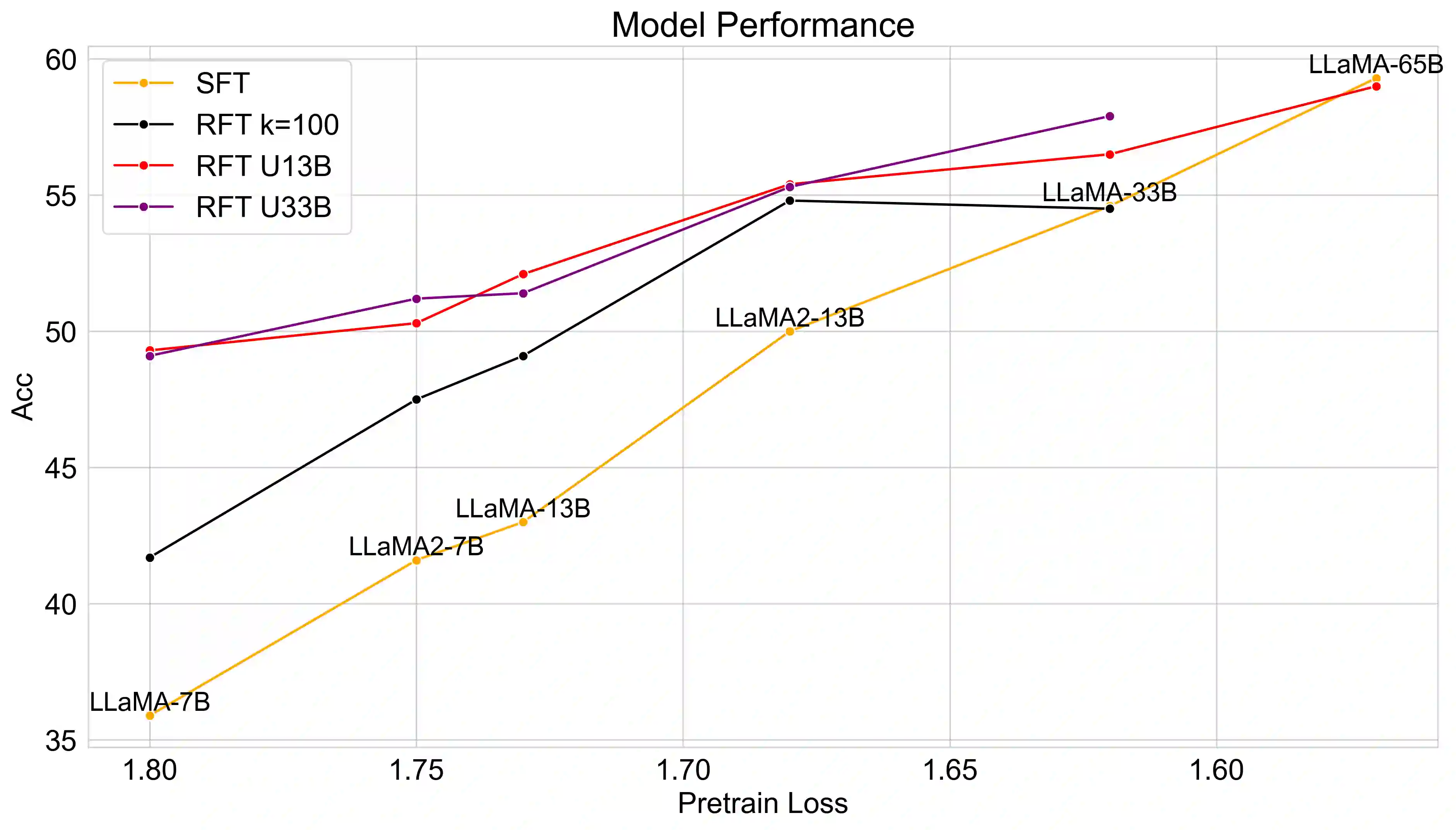
Mathematical reasoning is a challenging task for large language models (LLMs), while the scaling relationship of it with respect to LLM capacity is under-explored. In this paper, we investigate how the pre-training loss, supervised data amount, and augmented data amount influence the reasoning performances of a supervised LLM. We find that pre-training loss is a better indicator of the model's performance than the model's parameter count. We apply supervised fine-tuning (SFT) with different amounts of supervised data and empirically find a log-linear relation between data amount and model performance, and we find better models improve less with enlarged supervised datasets. To augment more data samples for improving model performances without any human effort, we propose to apply Rejection sampling Fine-Tuning (RFT). RFT uses supervised models to generate and collect correct reasoning paths as augmented fine-tuning datasets. We find with augmented samples containing more distinct reasoning paths, RFT improves mathematical reasoning performance more for LLMs. We also find RFT brings more improvement for less performant LLMs. Furthermore, we combine rejection samples from multiple models which push LLaMA-7B to an accuracy of 49.3% and outperforms the supervised fine-tuning (SFT) accuracy of 35.9% significantly.
翻译:数学推理对大型语言模型(LLMs)而言是一项具有挑战性的任务,而数学推理能力与LLM能力之间的规模关系尚未得到充分探索。本文研究了预训练损失、监督数据量以及增强数据量如何影响经过监督训练的LLM的推理性能。我们发现,与模型的参数数量相比,预训练损失是模型性能更好的指示指标。我们应用了不同监督数据量的监督微调(SFT),并通过实验发现数据量与模型性能之间存在对数线性关系,同时发现性能更优的模型在增大监督数据集时改进幅度较小。为了在不依赖人工的情况下增加更多数据样本以提升模型性能,我们提出了一种称为拒绝采样微调(RFT)的方法。RFT利用监督模型生成并收集正确的推理路径,作为增强后的微调数据集。我们发现,当增强样本包含更多不同的推理路径时,RFT能进一步提升LLM在数学推理任务上的性能。同时,RFT对性能较弱的LLM带来的改进更为显著。此外,我们将多个模型生成的拒绝采样结果进行组合,使LLaMA-7B的准确率达到了49.3%,显著优于监督微调(SFT)的35.9%准确率。