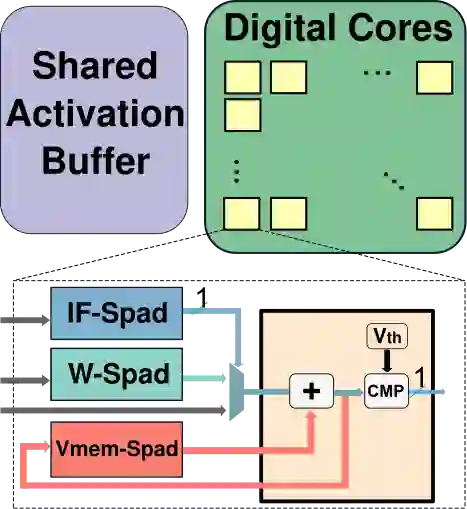
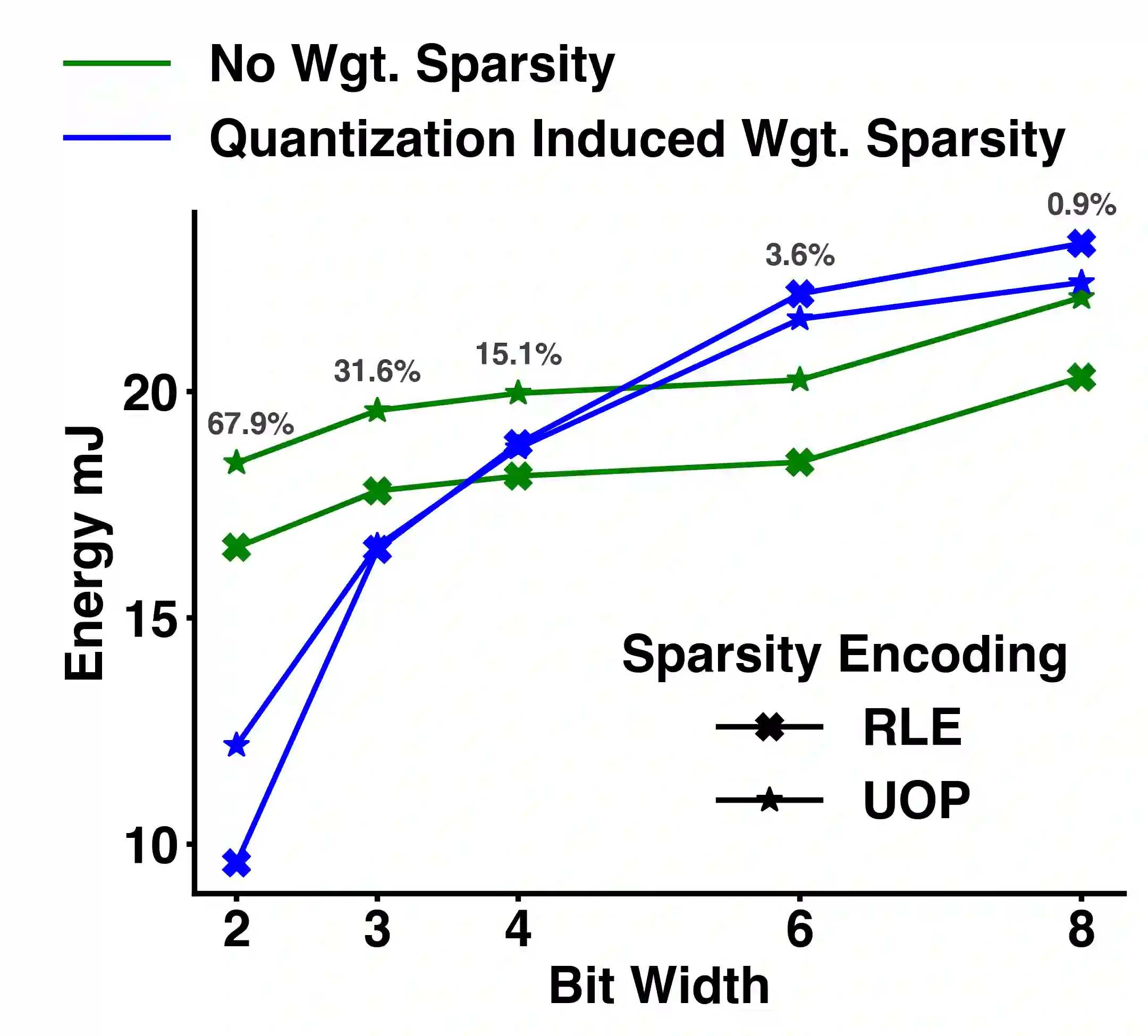
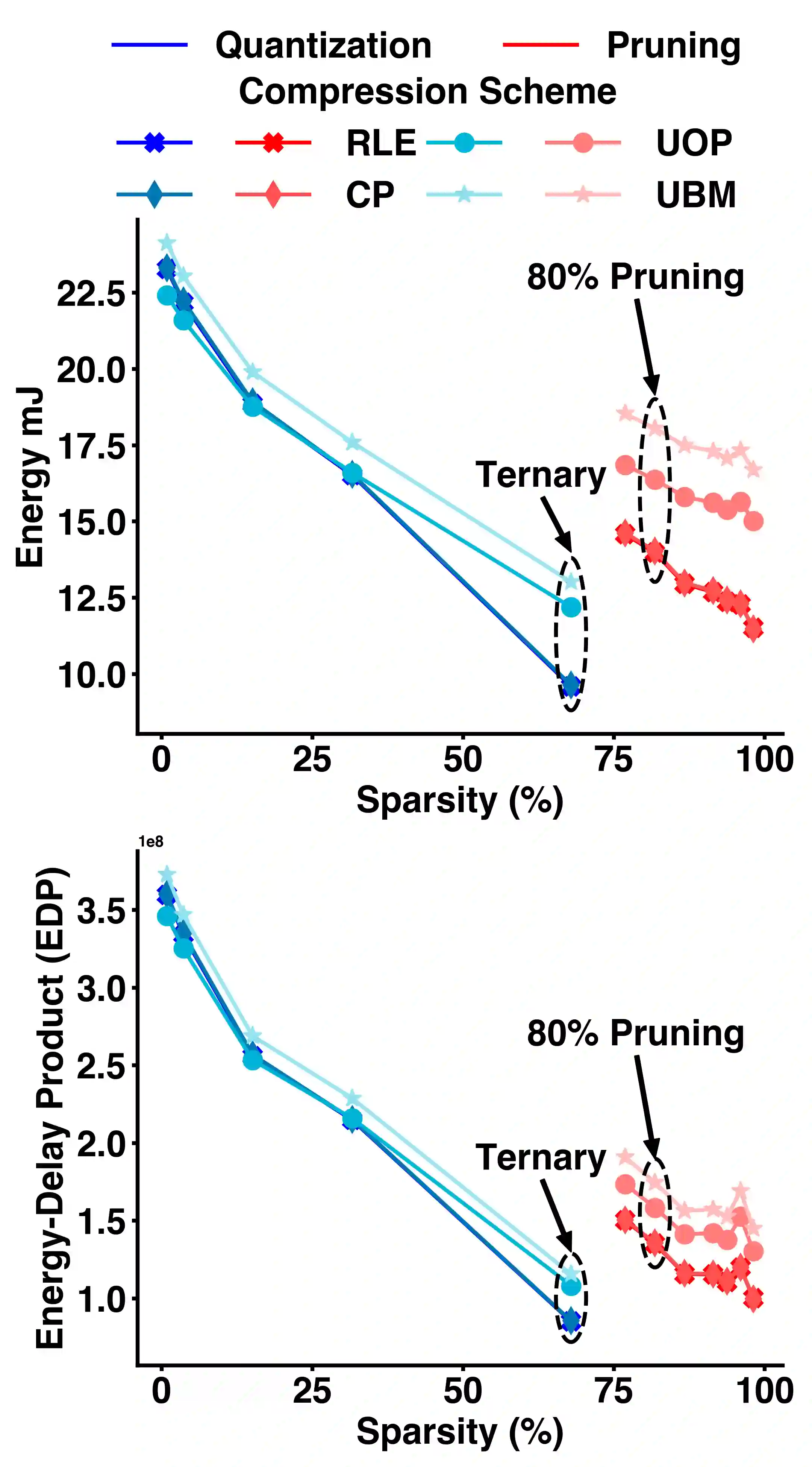
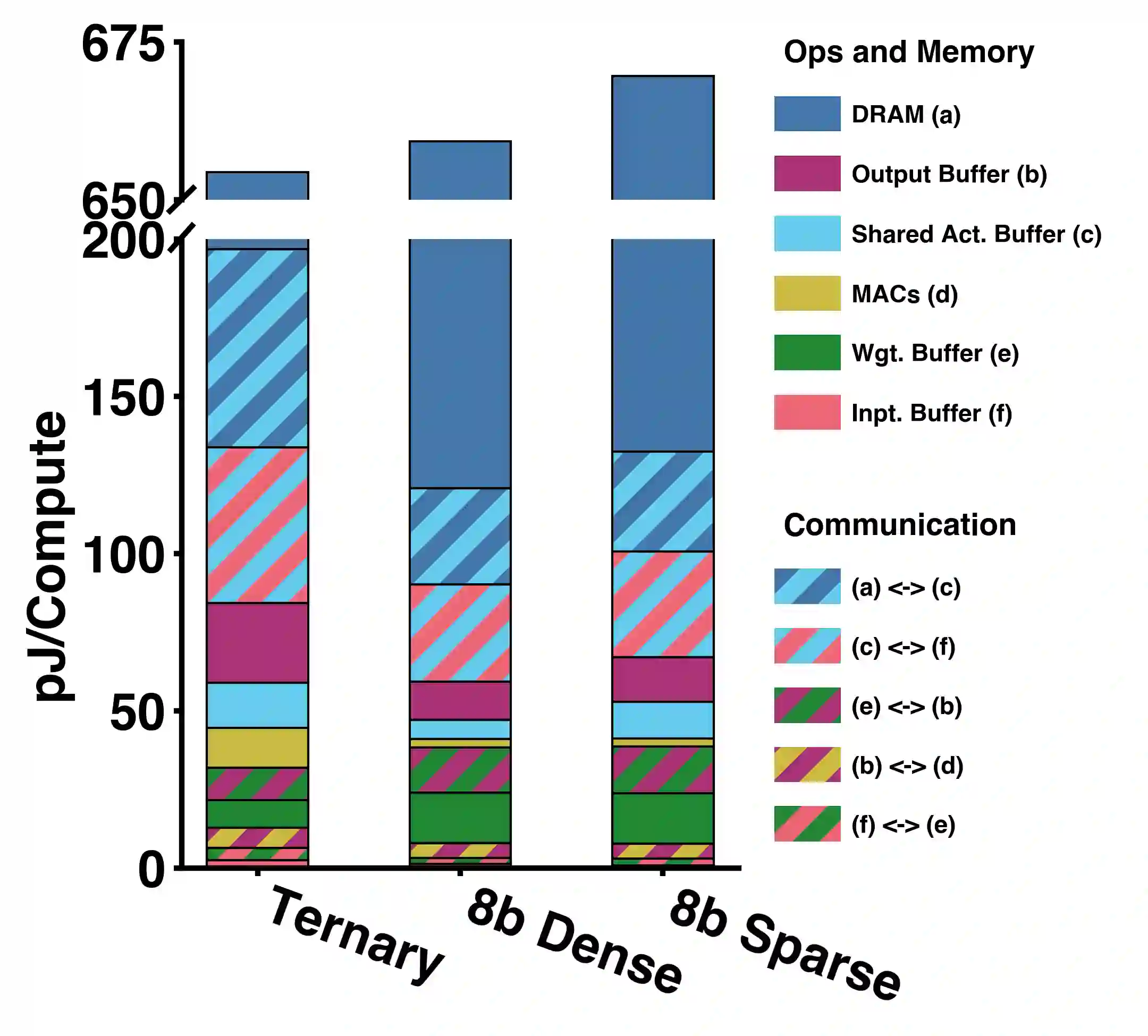
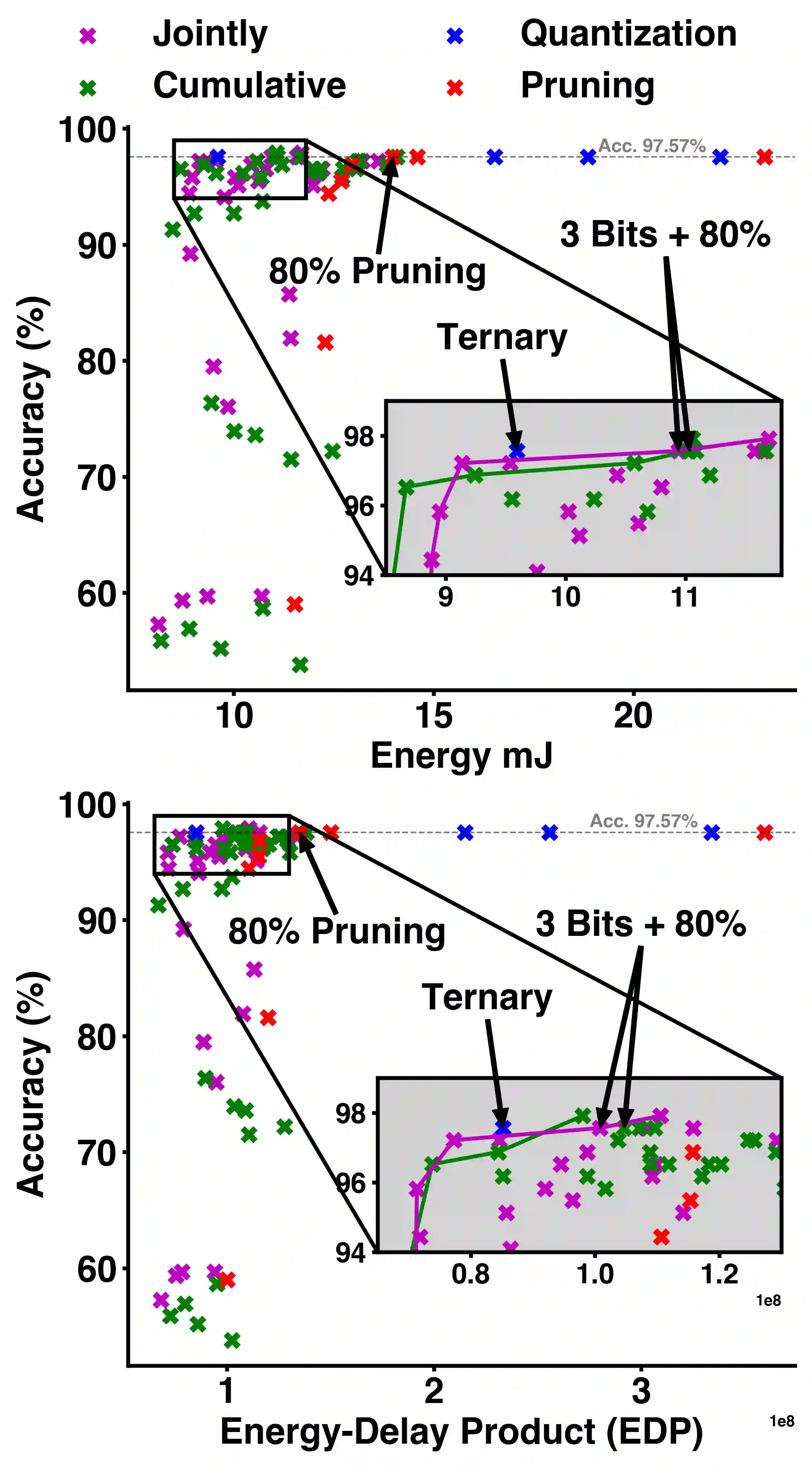
Energy efficient implementations and deployments of Spiking neural networks (SNNs) have been of great interest due to the possibility of developing artificial systems that can achieve the computational powers and energy efficiency of the biological brain. Efficient implementations of SNNs on modern digital hardware are also inspired by advances in machine learning and deep neural networks (DNNs). Two techniques widely employed in the efficient deployment of DNNs -- the quantization and pruning of parameters, can both compress the model size, reduce memory footprints, and facilitate low-latency execution. The interaction between quantization and pruning and how they might impact model performance on SNN accelerators is currently unknown. We study various combinations of pruning and quantization in isolation, cumulatively, and simultaneously (jointly) to a state-of-the-art SNN targeting gesture recognition for dynamic vision sensor cameras (DVS). We show that this state-of-the-art model is amenable to aggressive parameter quantization, not suffering from any loss in accuracy down to ternary weights. However, pruning only maintains iso-accuracy up to 80% sparsity, which results in 45% more energy than the best quantization on our architectural model. Applying both pruning and quantization can result in an accuracy loss to offer a favourable trade-off on the energy-accuracy Pareto-frontier for the given hardware configuration.
翻译:脉冲神经网络(SNN)的能量高效实现与部署一直备受关注,因其有望开发出兼具生物大脑计算能力与能效的人工系统。现代数字硬件上SNN的高效实现也受深度学习与深度神经网络(DNN)领域进展的启发。DNN高效部署中广泛采用的两种技术——参数量化与剪枝——均可压缩模型规模、减少内存占用并促进低延迟执行。目前尚不清楚量化与剪枝之间的相互作用及其如何影响SNN加速器上的模型性能。我们针对面向动态视觉传感器相机(DVS)手势识别的最新SNN模型,分别研究了剪枝与量化在孤立、累积与联合(同时)应用下的多种组合。结果表明,该先进模型对激进参数量化具有鲁棒性,直至三值权重时仍无精度损失。然而,仅采用剪枝时,模型仅能在稀疏度达80%时维持等精度,其能耗比基于我们架构模型的最优量化方案高出45%。同时应用剪枝与量化虽会导致精度损失,但可在给定硬件配置下,于能量-精度帕累托前沿上实现有利的权衡。