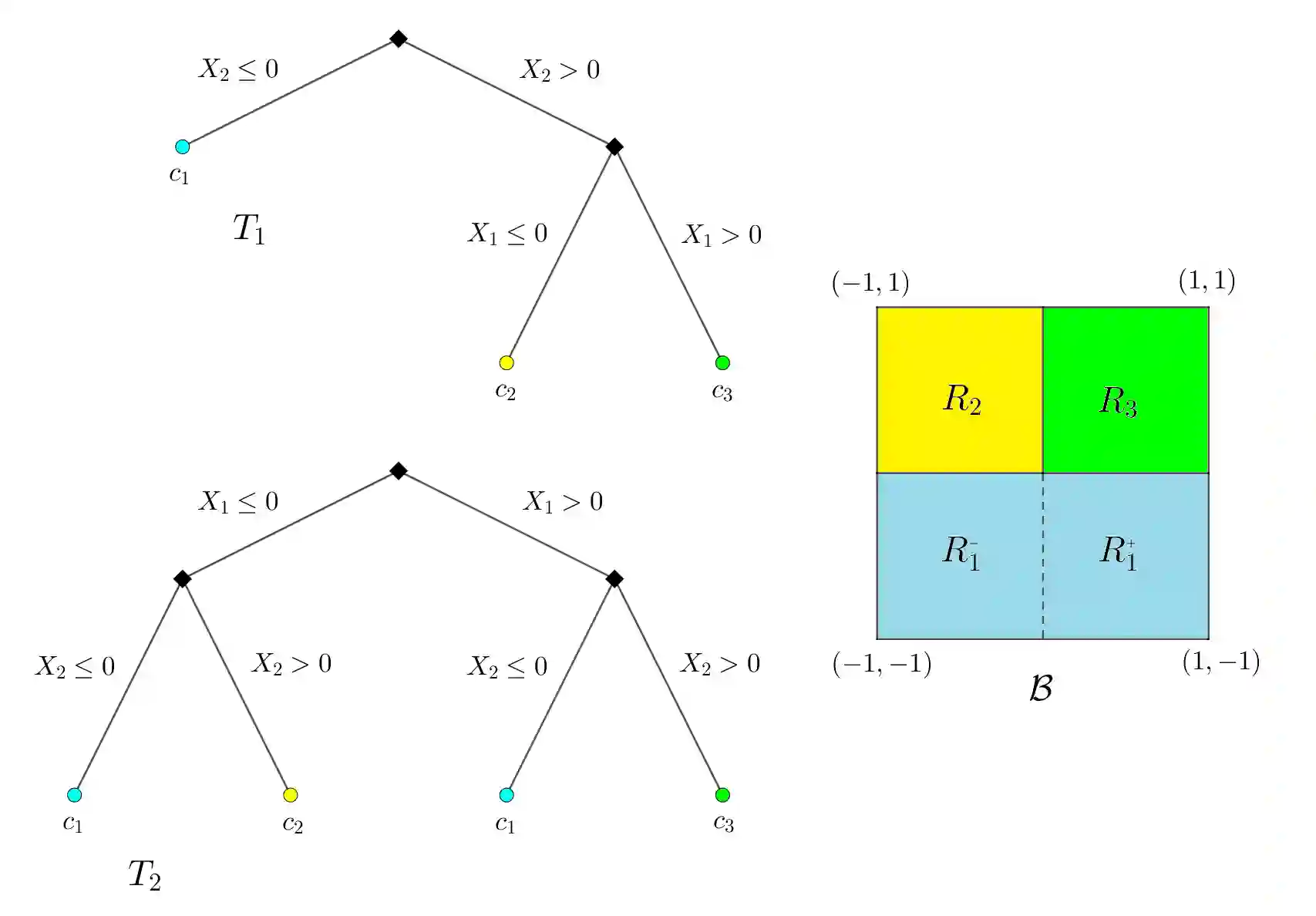
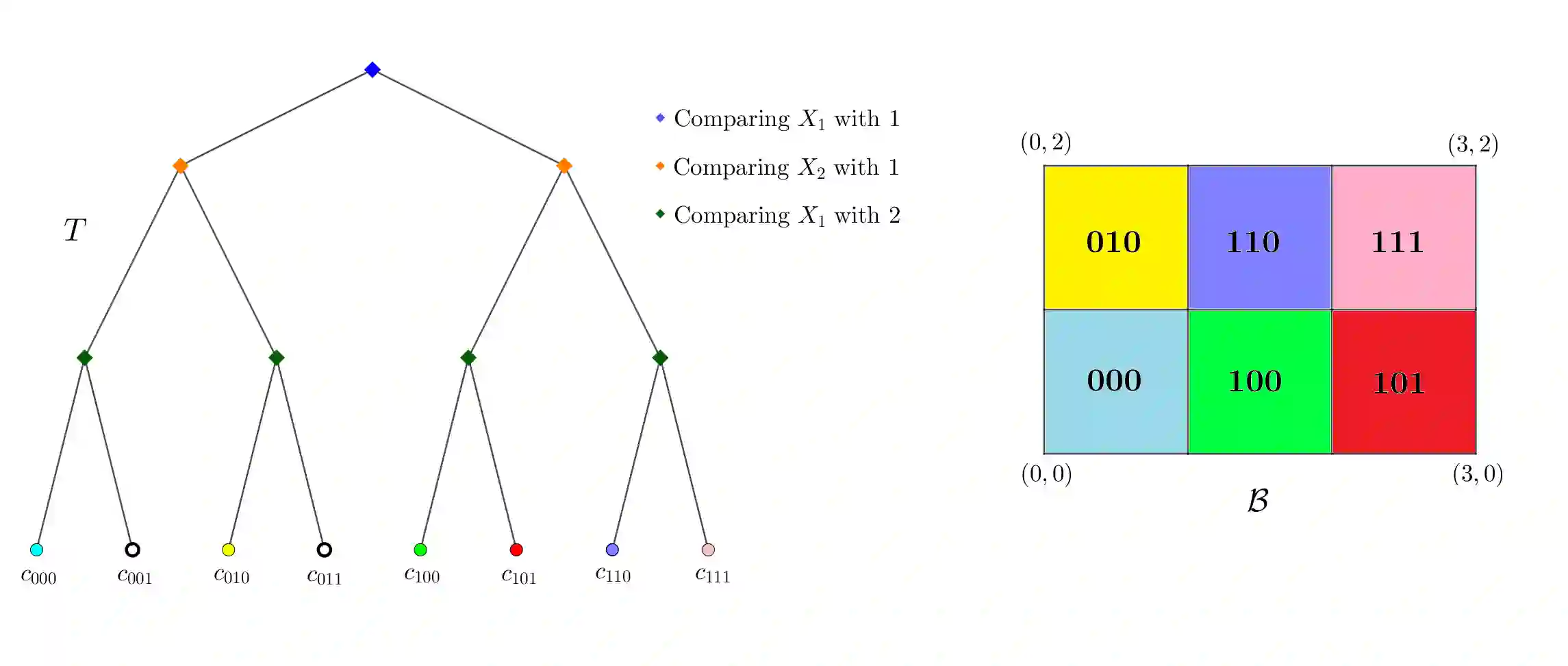
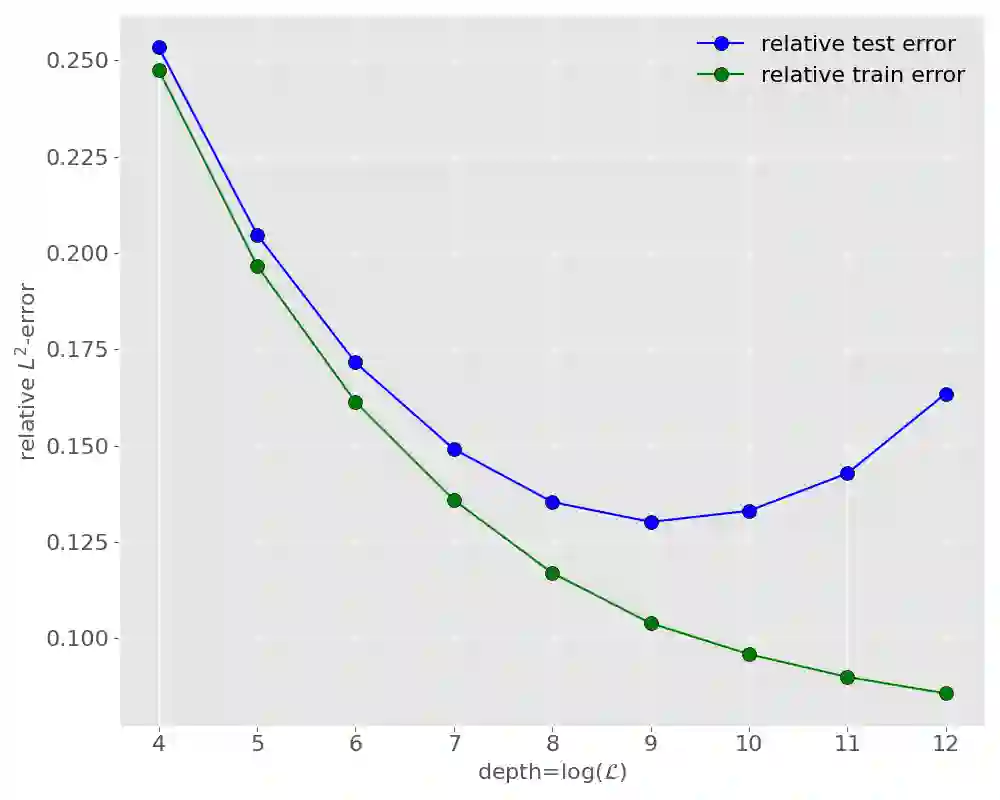
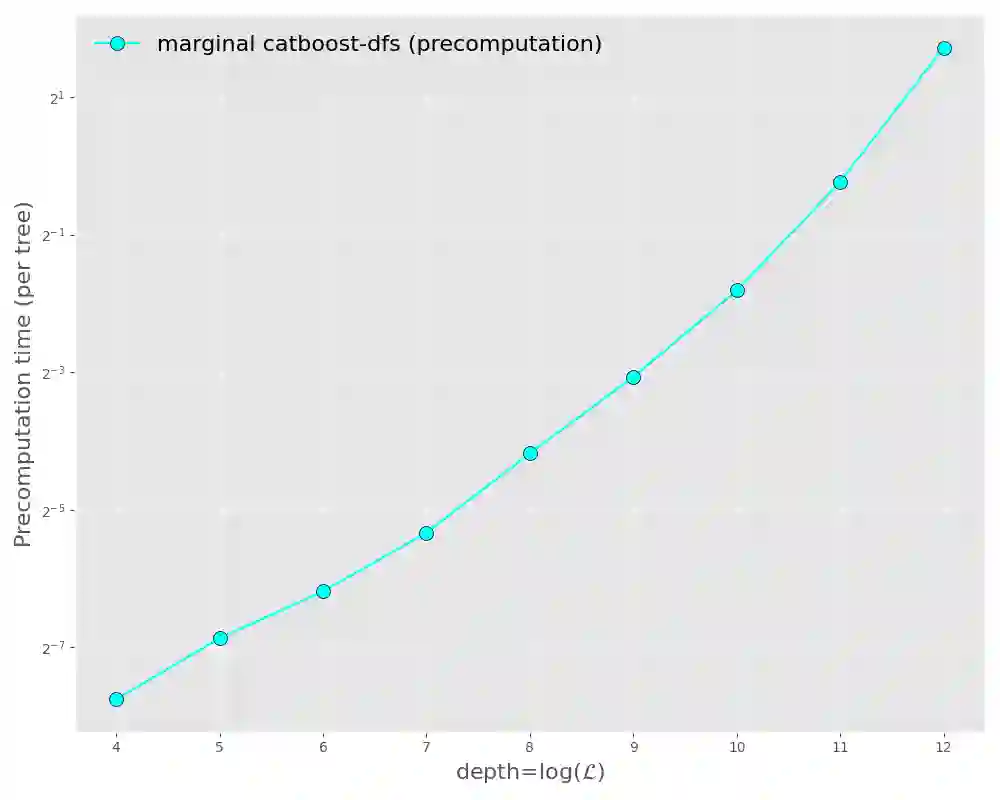
Due to their power and ease of use, tree-based machine learning models, such as random forests and gradient-boosted tree ensembles, have become very popular. To interpret them, local feature attributions based on marginal expectations, e.g. marginal (interventional) Shapley, Owen or Banzhaf values, may be employed. Such methods are true to the model and implementation invariant, i.e. dependent only on the input-output function of the model. We contrast this with the popular TreeSHAP algorithm by presenting two (statistically similar) decision trees that compute the exact same function for which the "path-dependent" TreeSHAP yields different rankings of features, whereas the marginal Shapley values coincide. Furthermore, we discuss how the internal structure of tree-based models may be leveraged to help with computing their marginal feature attributions according to a linear game value. One important observation is that these are simple (piecewise-constant) functions with respect to a certain grid partition of the input space determined by the trained model. Another crucial observation, showcased by experiments with XGBoost, LightGBM and CatBoost libraries, is that only a portion of all features appears in a tree from the ensemble. Thus, the complexity of computing marginal Shapley (or Owen or Banzhaf) feature attributions may be reduced. This remains valid for a broader class of game values which we shall axiomatically characterize. A prime example is the case of CatBoost models where the trees are oblivious (symmetric) and the number of features in each of them is no larger than the depth. We exploit the symmetry to derive an explicit formula, with improved complexity and only in terms of the internal model parameters, for marginal Shapley (and Banzhaf and Owen) values of CatBoost models. This results in a fast, accurate algorithm for estimating these feature attributions.
翻译:由于其强大功能和易用性,基于树的机器学习模型(如随机森林和梯度提升树集成)已变得非常流行。为解释这些模型,可采用基于边际期望的局部特征归因方法,例如边际(干预型)Shapley值、Owen值或Banzhaf值。这类方法忠实于模型且具有实现不变性,即仅依赖模型的输入输出函数。我们通过呈现两个(统计上相似的)决策树(它们计算完全相同的函数,但"路径依赖型"TreeSHAP算法对特征排序不同,而边际Shapley值一致),将此类方法与主流的TreeSHAP算法形成对比。进一步地,我们讨论了如何利用树模型的内部结构,根据线性博弈值高效计算其边际特征归因。一个重要发现是:这些模型在由训练模型确定的输入空间网格划分上,属于简单的分段常数函数。另一个关键发现(通过XGBoost、LightGBM和CatBoost库的实验验证)在于:集成树中每棵树仅涉及全部特征的一部分。因此,计算边际Shapley值(或Owen值、Banzhaf值)的复杂度可显著降低。这一定理对更广泛的一类博弈值同样成立,我们将在公理化框架下对其进行刻画。以CatBoost模型为例,其树结构具有 oblivious(对称)特性,且每棵树的特征数不超过树深度。我们利用这种对称性,仅基于模型内部参数,推导出CatBoost模型边际Shapley值(及Banzhaf值、Owen值)的显式公式,显著降低了计算复杂度。该公式为快速准确估计上述特征归因提供了高效算法。