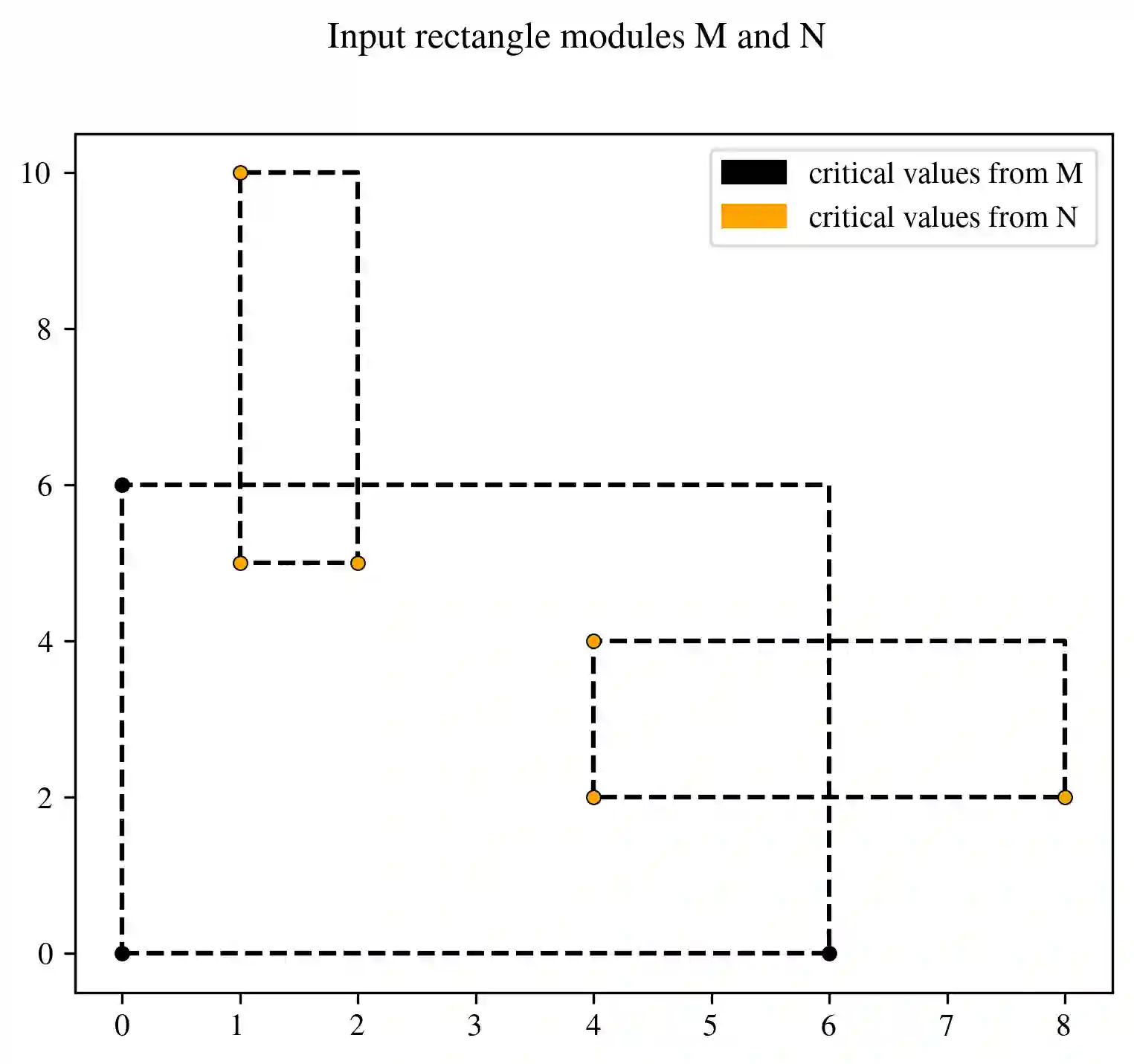
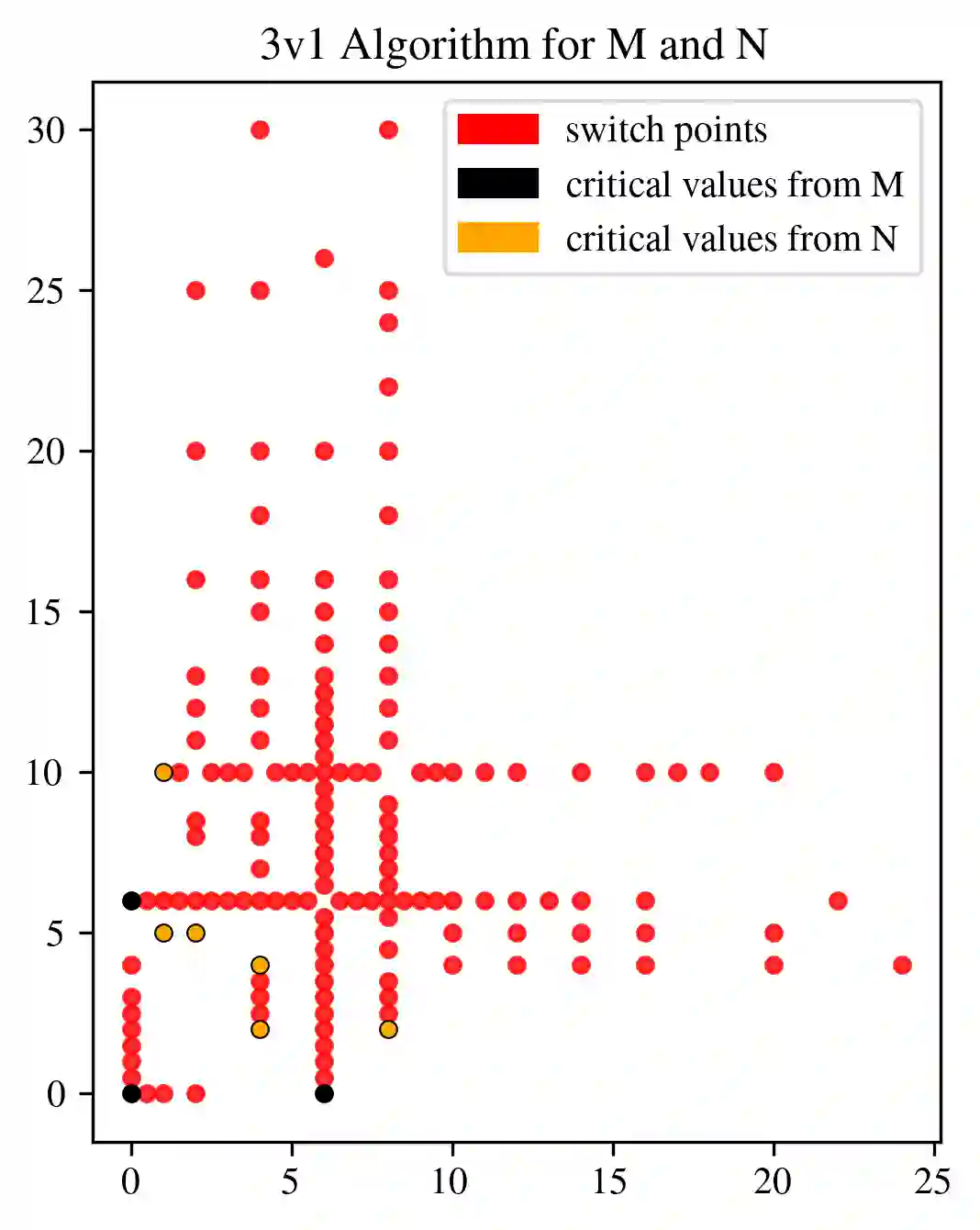
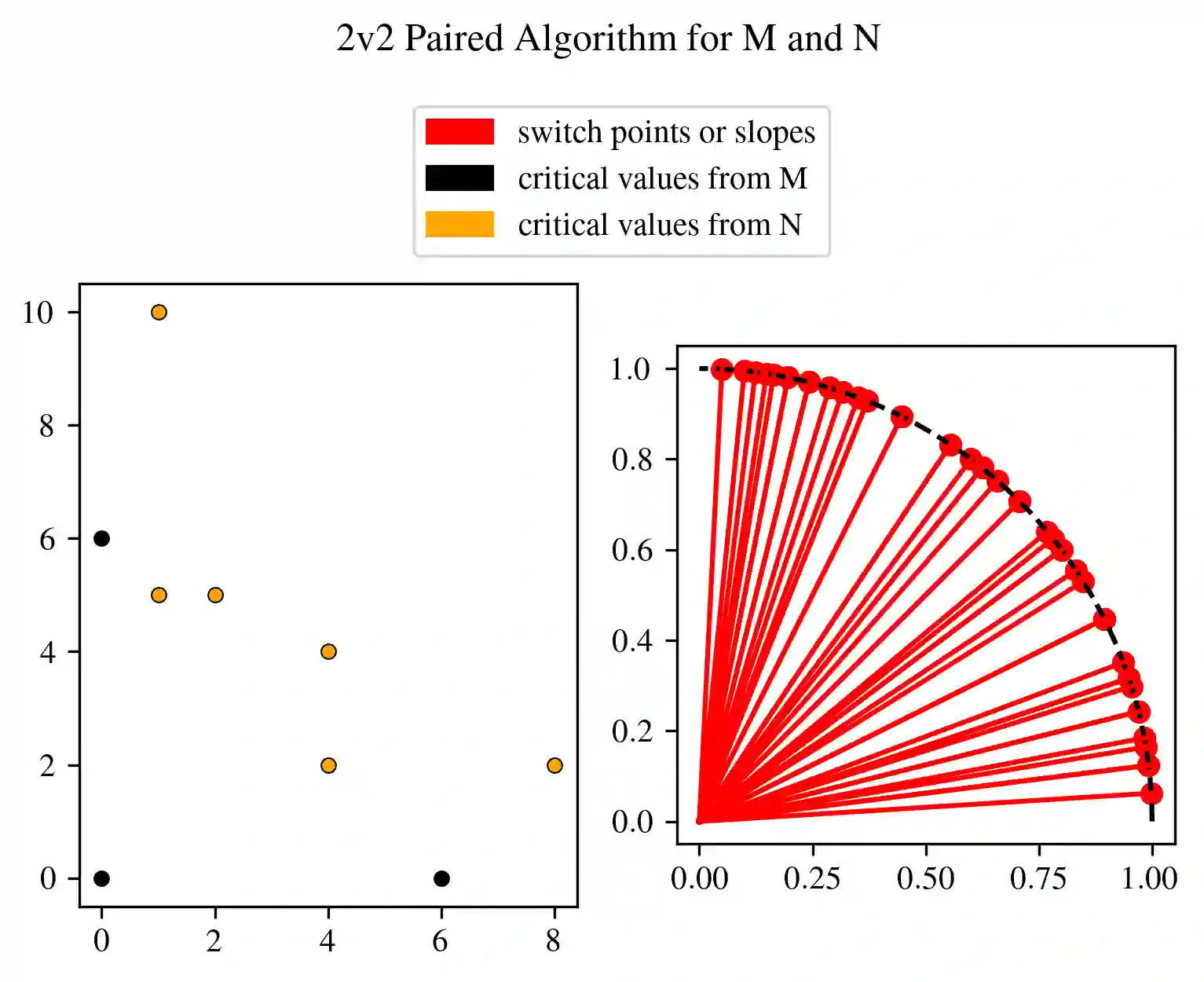
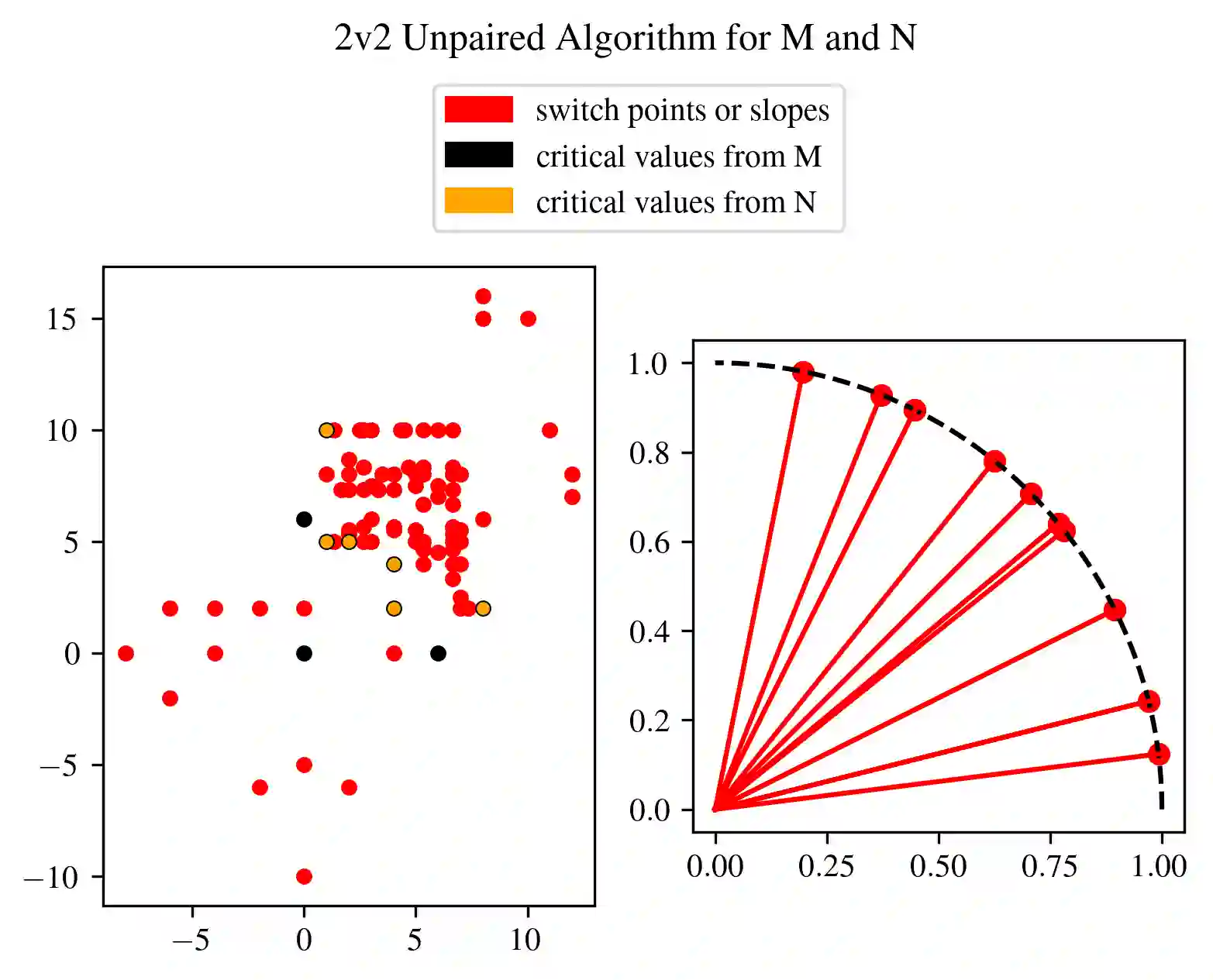
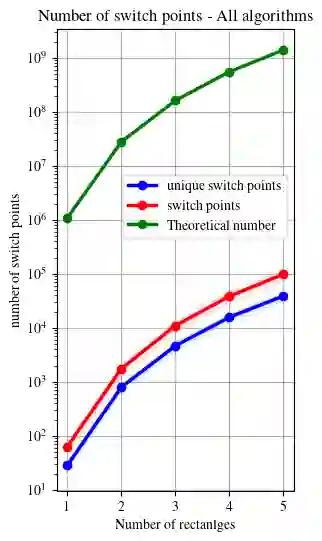
In multi-parameter persistence, the matching distance is defined as the supremum of weighted bottleneck distances on the barcodes given by the restriction of persistence modules to lines with a positive slope. In the case of finitely presented bi-persistence modules, all the available methods to compute the matching distance are based on restricting the computation to lines through pairs from a finite set of points in the plane. Some of these points are determined by the filtration data as they are entrance values of critical simplices. However, these critical values alone are not sufficient for the matching distance computation and it is necessary to add so-called switch points, i.e. points such that on a line through any of them, the bottleneck matching switches the matched pair. This paper is devoted to the algorithmic computation of the set of switch points given a set of critical values. We find conditions under which a candidate switch point is erroneous or superfluous. The obtained conditions are turned into algorithms that have been implemented. With this, we analyze how the size of the set of switch points increases as the number of critical values increases, and how it varies depending on the distribution of critical values. Experiments are carried out on various types of bi-persistence modules.
翻译:在多参数持久化中,匹配距离定义为在具有正斜率的直线上由持久化模块限制给出的条形码中加权瓶颈距离的上确界。对于有限表示的双持久化模块,所有可用的匹配距离计算方法均基于将计算限制在通过平面上有限点集构成的直线对上。其中一些点由过滤数据决定,作为关键单形的进入值。然而,仅凭这些关键值不足以计算匹配距离,还需添加所谓的切换点,即通过任意该点的直线上的瓶颈匹配会切换匹配对。本文致力于在给定关键值集合的条件下,算法化地计算切换点集。我们找到了候选切换点为错误或冗余的条件。这些条件被转化为算法并已实现。据此,我们分析了切换点集规模随关键值数量增加的变化规律,以及其随关键值分布变化的特性。实验在多种类型的双持久化模块上进行。