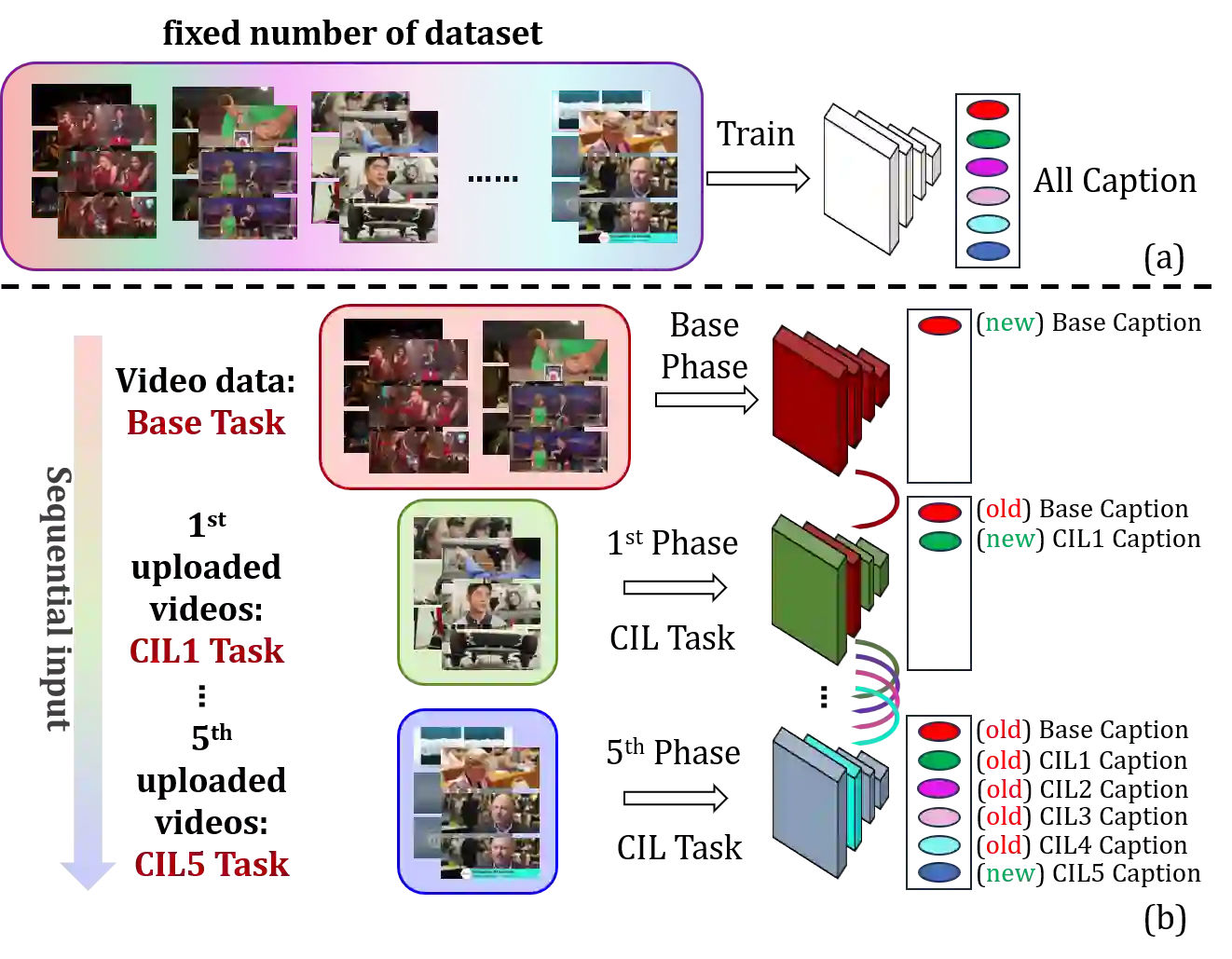
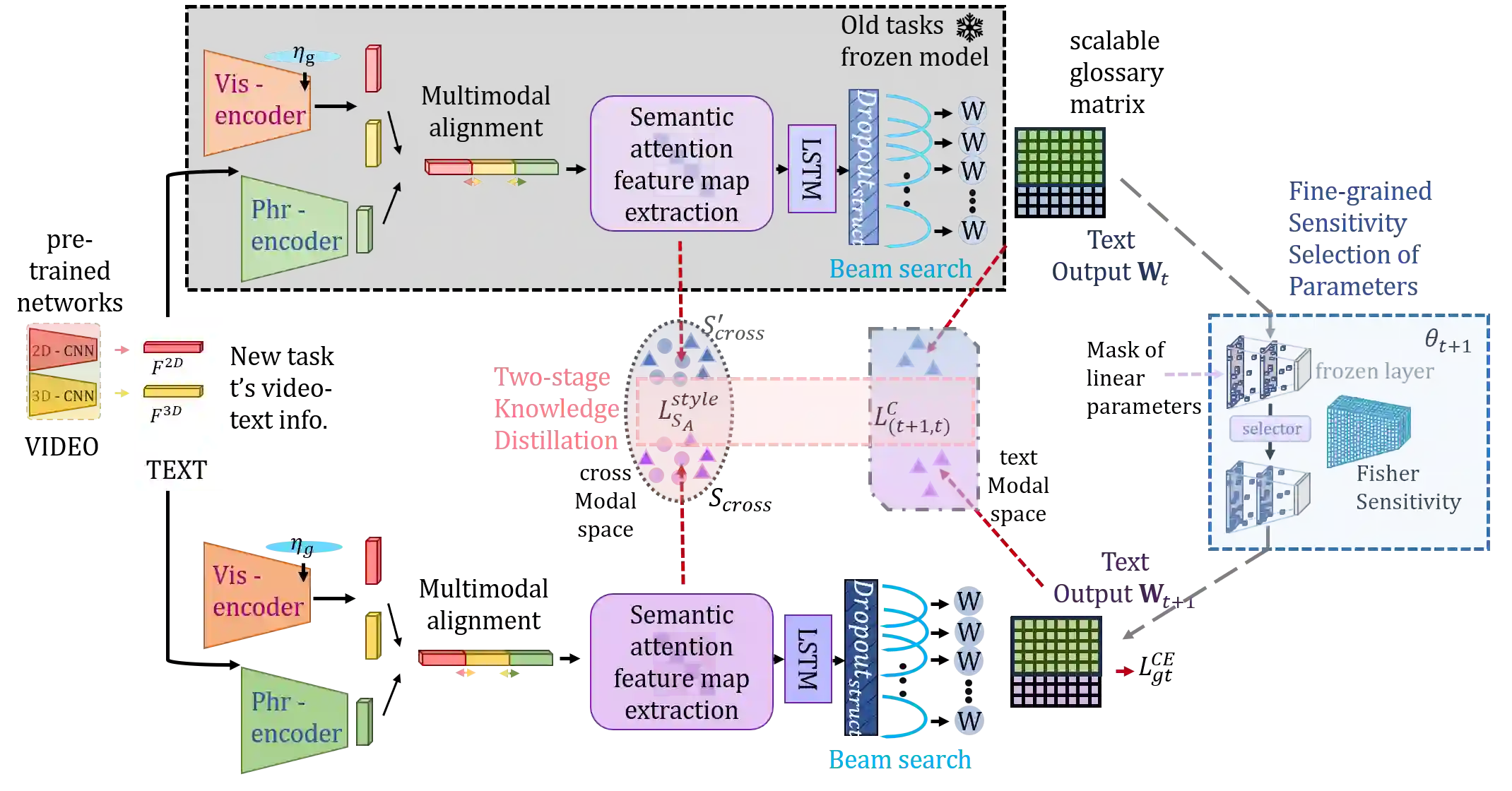
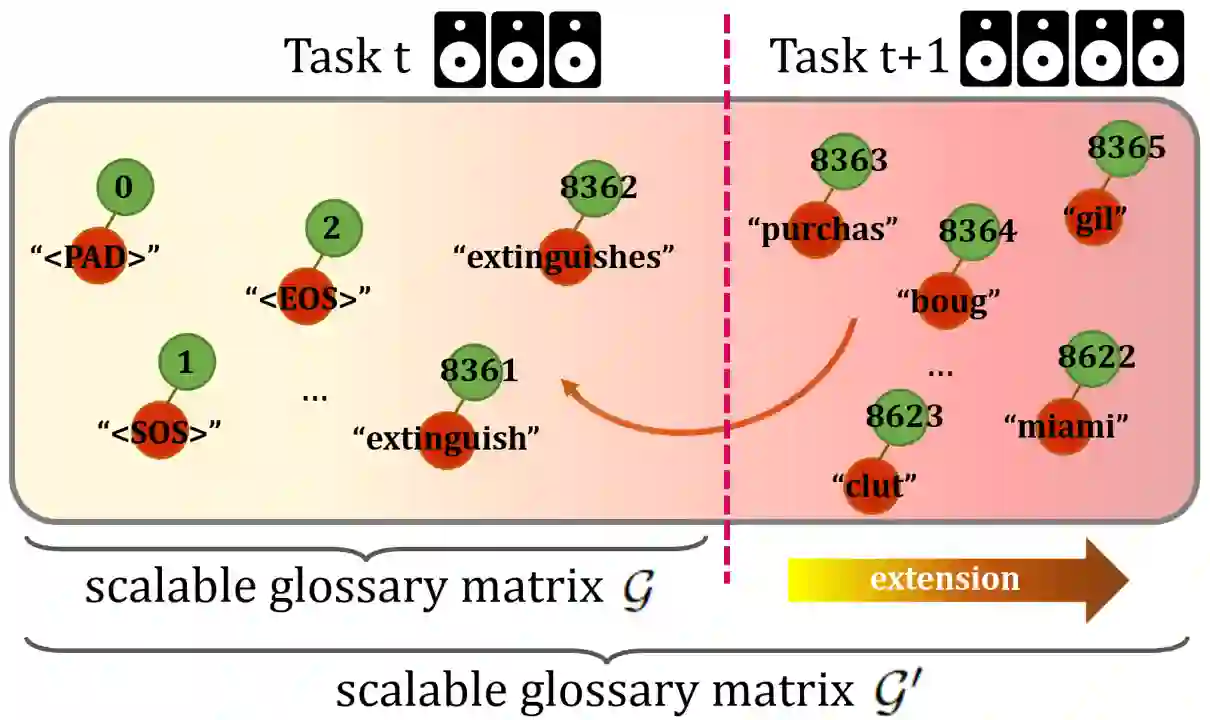
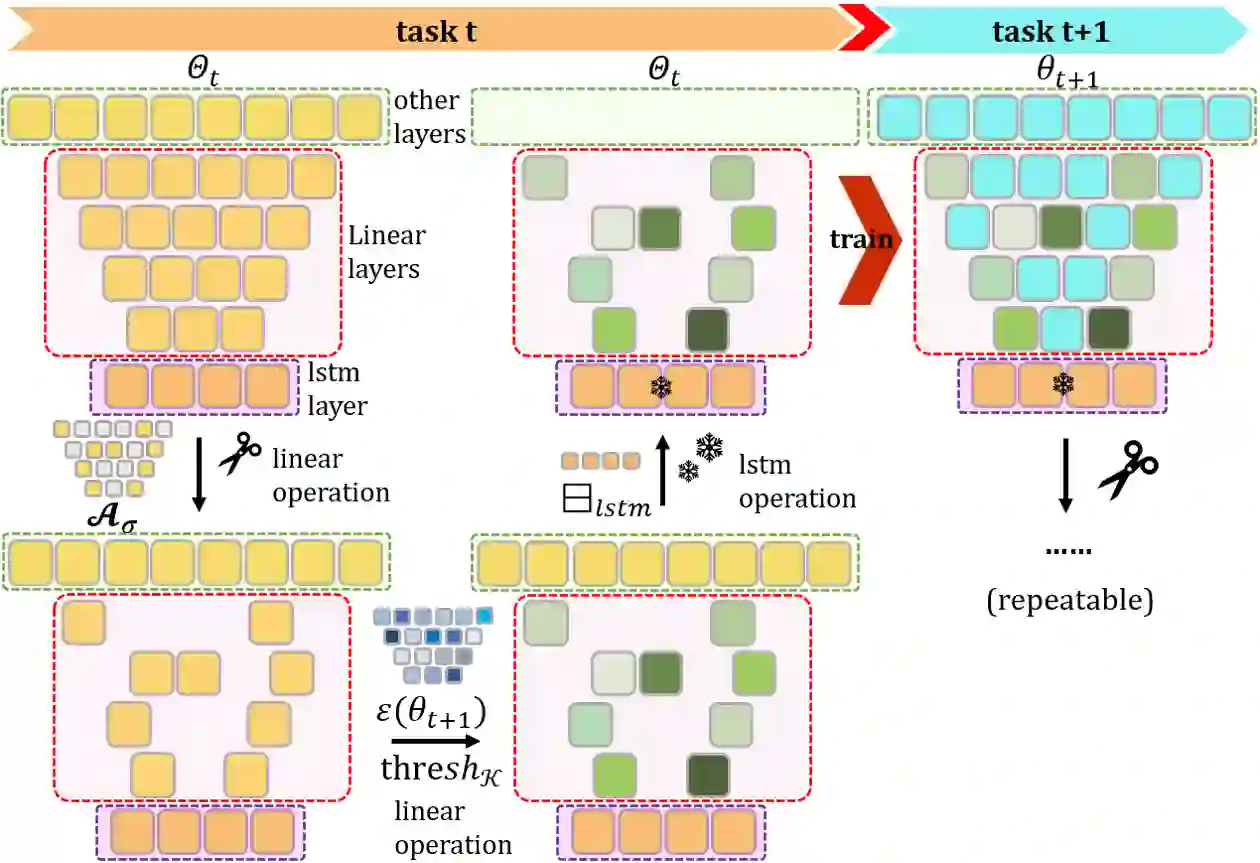
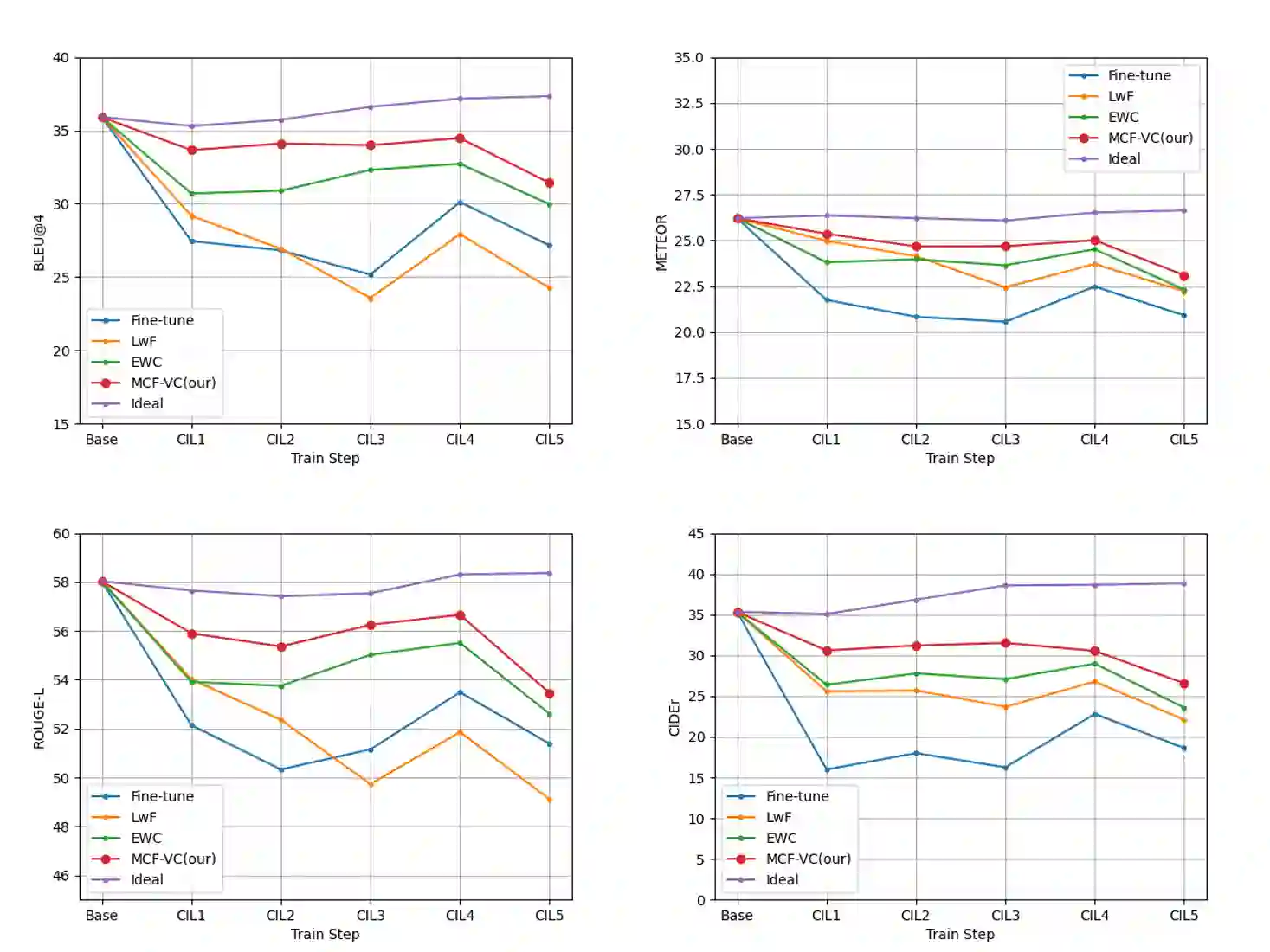
To address the problem of catastrophic forgetting due to the invisibility of old categories in sequential input, existing work based on relatively simple categorization tasks has made some progress. In contrast, video captioning is a more complex task in multimodal scenario, which has not been explored in the field of incremental learning. After identifying this stability-plasticity problem when analyzing video with sequential input, we originally propose a method to Mitigate Catastrophic Forgetting in class-incremental learning for multimodal Video Captioning (MCF-VC). As for effectively maintaining good performance on old tasks at the macro level, we design Fine-grained Sensitivity Selection (FgSS) based on the Mask of Linear's Parameters and Fisher Sensitivity to pick useful knowledge from old tasks. Further, in order to better constrain the knowledge characteristics of old and new tasks at the specific feature level, we have created the Two-stage Knowledge Distillation (TsKD), which is able to learn the new task well while weighing the old task. Specifically, we design two distillation losses, which constrain the cross modal semantic information of semantic attention feature map and the textual information of the final outputs respectively, so that the inter-model and intra-model stylized knowledge of the old class is retained while learning the new class. In order to illustrate the ability of our model to resist forgetting, we designed a metric CIDER_t to detect the stage forgetting rate. Our experiments on the public dataset MSR-VTT show that the proposed method significantly resists the forgetting of previous tasks without replaying old samples, and performs well on the new task.
翻译:针对序列输入中旧类别不可见所导致的灾难性遗忘问题,现有基于相对简单分类任务的工作已取得一定进展。然而,视频描述作为多模态场景下更具复杂性的任务,在增量学习领域尚未被探索。在分析序列输入视频时识别到这一稳定性-可塑性问题后,我们首次提出了一种在类增量学习多模态视频描述中缓解灾难性遗忘的方法(MCF-VC)。为了在宏观层面有效保持旧任务的性能,我们基于线性层参数掩码与费雪敏感性设计了细粒度敏感性选择模块(FgSS),用以从旧任务中筛选有用知识。进一步地,为了在具体特征层面更好地约束新旧任务的知识特性,我们创建了两阶段知识蒸馏方法(TsKD),能够在权衡旧任务的同时较好地学习新任务。具体而言,我们设计了两种蒸馏损失,分别约束语义注意力特征图的跨模态语义信息与最终输出的文本信息,从而在学习新类别时保留旧类别在模型间与模型内的风格化知识。为展示模型抗遗忘能力,我们设计了度量指标CIDER_t以检测阶段遗忘率。在公开数据集MSR-VTT上的实验表明,所提方法在不回放旧样本的情况下显著抵抗了先前任务的遗忘,并在新任务上表现优异。