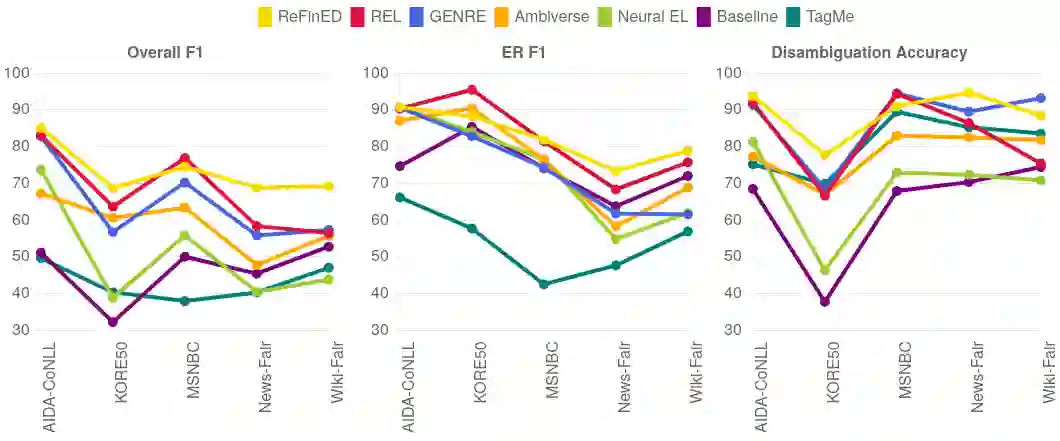
Existing evaluations of entity linking systems often say little about how the system is going to perform for a particular application. There are two fundamental reasons for this. One is that many evaluations only use aggregate measures (like precision, recall, and F1 score), without a detailed error analysis or a closer look at the results. The other is that all of the widely used benchmarks have strong biases and artifacts, in particular: a strong focus on named entities, an unclear or missing specification of what else counts as an entity mention, poor handling of ambiguities, and an over- or underrepresentation of certain kinds of entities. We provide a more meaningful and fair in-depth evaluation of a variety of existing end-to-end entity linkers. We characterize their strengths and weaknesses and also report on reproducibility aspects. The detailed results of our evaluation can be inspected under https://elevant.cs.uni-freiburg.de/emnlp2023 . Our evaluation is based on several widely used benchmarks, which exhibit the problems mentioned above to various degrees, as well as on two new benchmarks, which address the problems mentioned above. The new benchmarks can be found under https://github.com/ad-freiburg/fair-entity-linking-benchmarks .
翻译:对实体链接系统的现有评估往往很少说明该系统在特定应用中的表现。这有两个根本原因:其一,许多评估仅使用聚合指标(如精确率、召回率和F1分数),缺乏详细的错误分析或对结果的深入审视;其二,所有广泛使用的基准存在严重偏差和人为因素,尤其表现为:过度聚焦于命名实体,对哪些内容算作实体提及的定义不明确或缺失,处理歧义的能力不足,以及某些类型实体的过度或不足代表。我们针对多种现有端到端实体链接器提供了更有意义且公平的深入评估,既刻画了它们的优势与不足,也报告了可复现性方面的结果。评估的详细结果可在 https://elevant.cs.uni-freiburg.de/emnlp2023 查阅。我们的评估基于多个广泛使用的基准(这些基准在不同程度上存在上述问题)以及两个新基准(这些新基准解决了上述问题)。新基准可在 https://github.com/ad-freiburg/fair-entity-linking-benchmarks 获取。