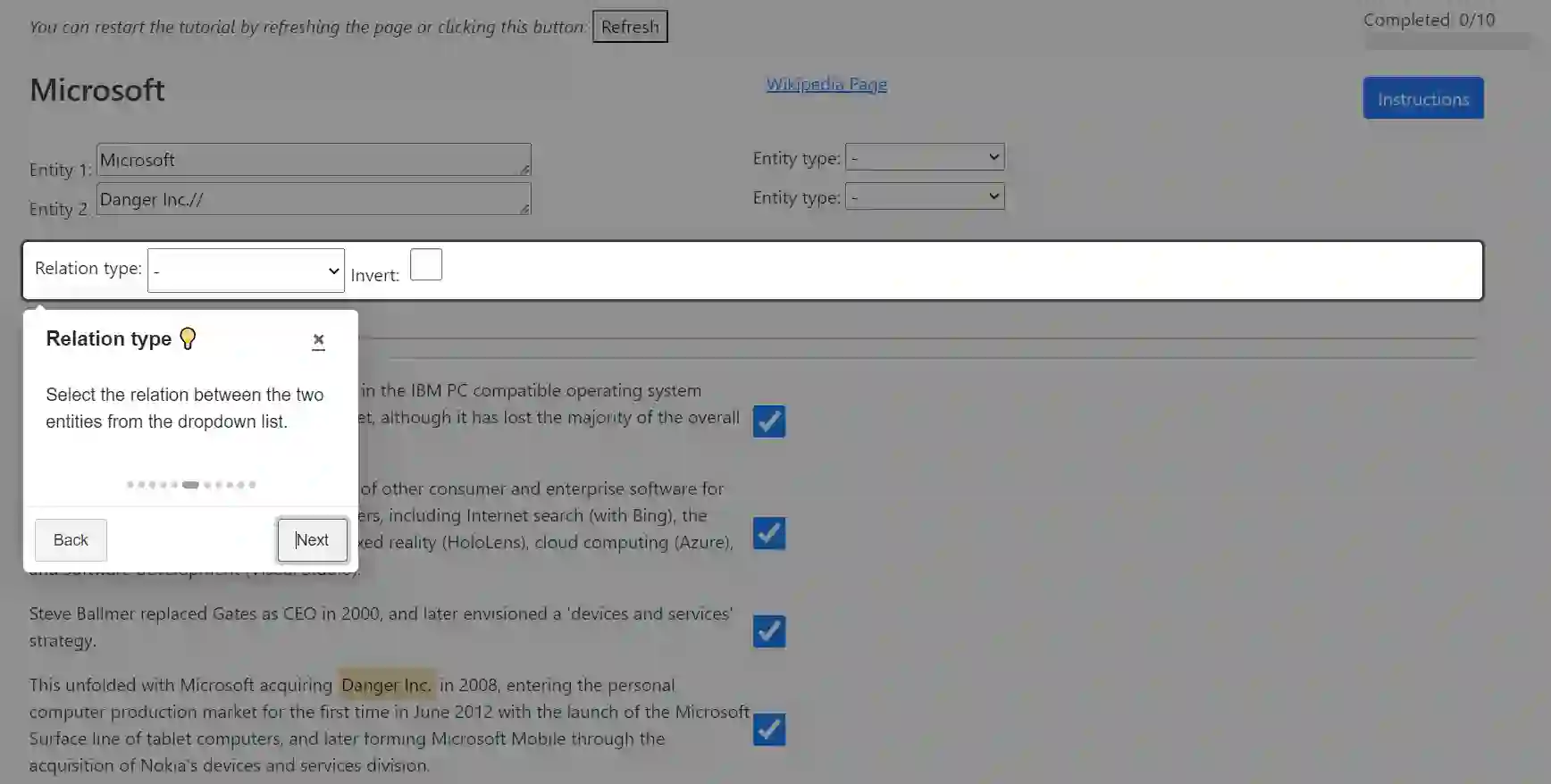
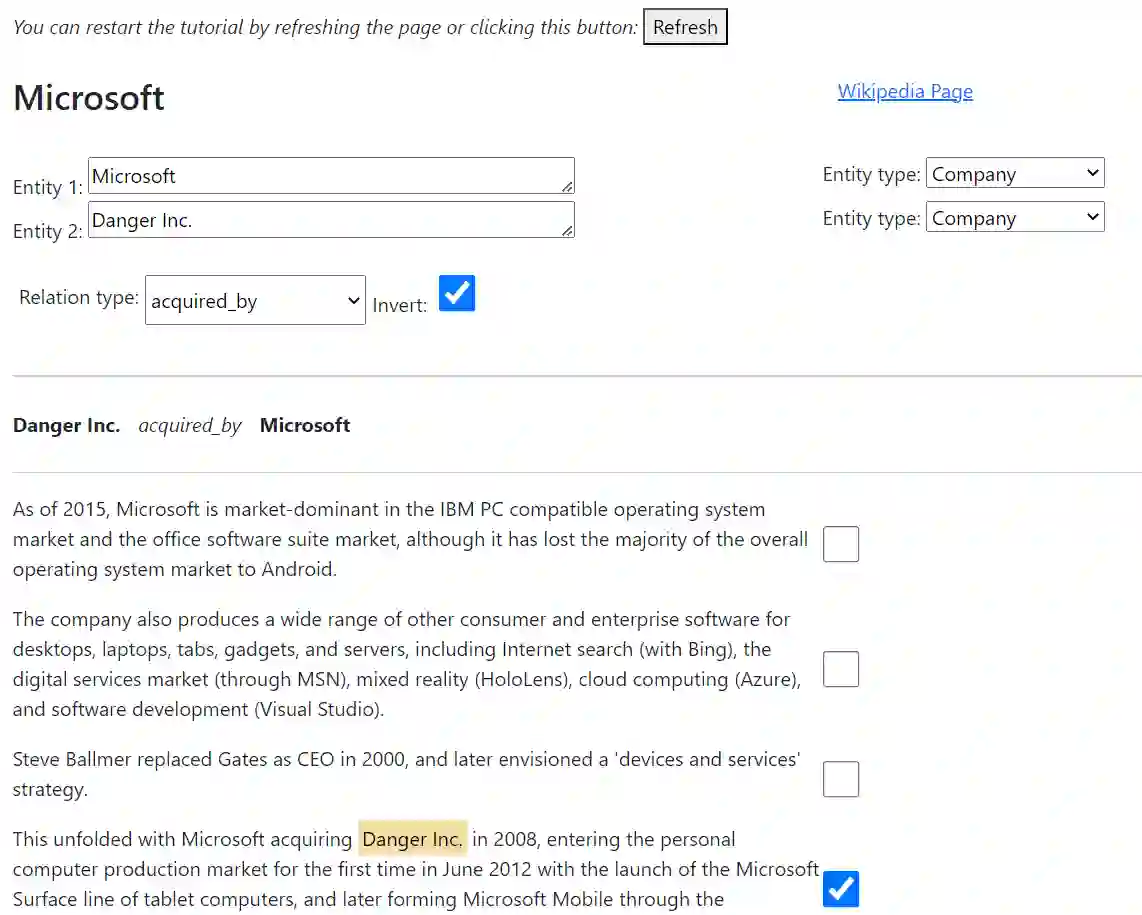
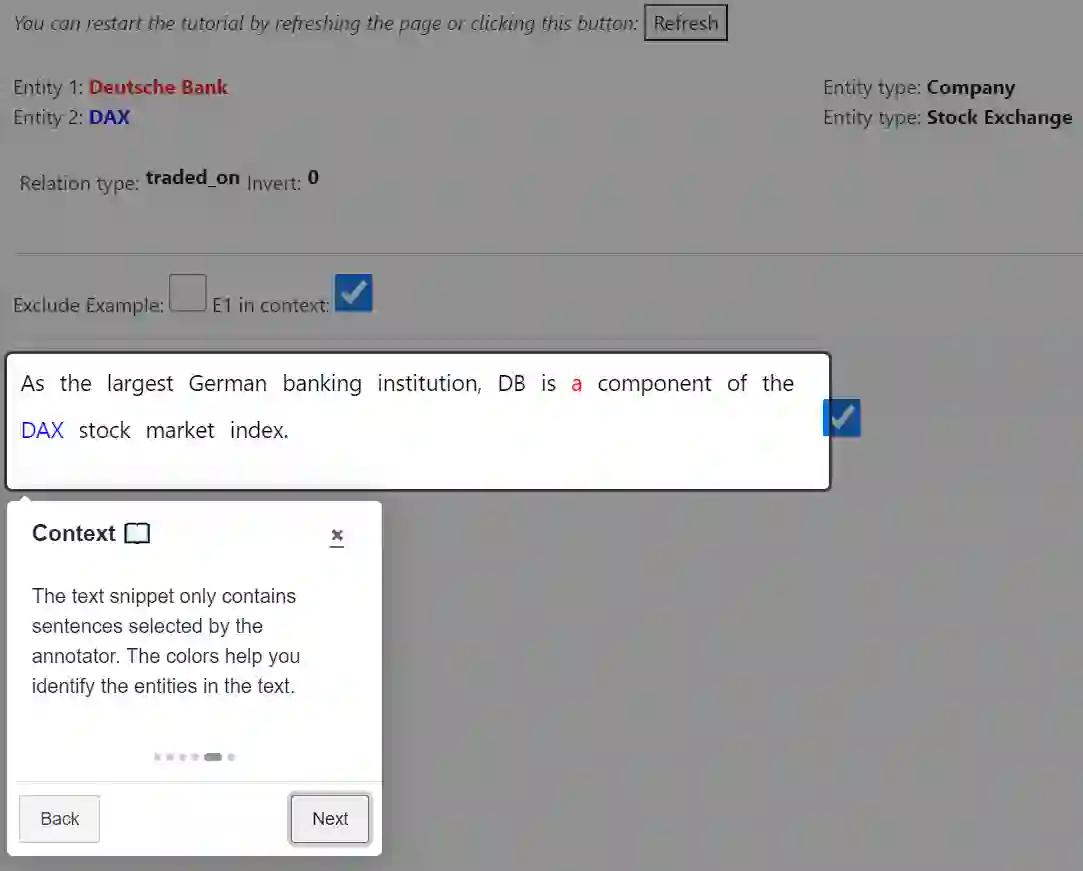
We introduce CORE, a dataset for few-shot relation classification (RC) focused on company relations and business entities. CORE includes 4,708 instances of 12 relation types with corresponding textual evidence extracted from company Wikipedia pages. Company names and business entities pose a challenge for few-shot RC models due to the rich and diverse information associated with them. For example, a company name may represent the legal entity, products, people, or business divisions depending on the context. Therefore, deriving the relation type between entities is highly dependent on textual context. To evaluate the performance of state-of-the-art RC models on the CORE dataset, we conduct experiments in the few-shot domain adaptation setting. Our results reveal substantial performance gaps, confirming that models trained on different domains struggle to adapt to CORE. Interestingly, we find that models trained on CORE showcase improved out-of-domain performance, which highlights the importance of high-quality data for robust domain adaptation. Specifically, the information richness embedded in business entities allows models to focus on contextual nuances, reducing their reliance on superficial clues such as relation-specific verbs. In addition to the dataset, we provide relevant code snippets to facilitate reproducibility and encourage further research in the field.
翻译:我们提出CORE,一个面向公司关系与商业实体的小样本关系分类(RC)数据集。该数据集包含源自公司维基百科页面的4,708个实例,对应12种关系类型及相应的文本证据。公司名称和商业实体因其关联信息的丰富多样,给小样本RC模型带来了挑战。例如,公司名称可能根据上下文表示法律实体、产品、人员或业务部门。因此,实体间关系类型的推导高度依赖文本语境。为评估最先进的RC模型在CORE数据集上的表现,我们在小样本领域自适应设置下开展实验。实验结果揭示了显著的性能差距,证实了在不同领域训练的模型难以适应CORE。有趣的是,我们发现基于CORE训练的模型展现出更强的跨领域性能,这凸显了高质量数据对鲁棒领域自适应的重要性。具体而言,商业实体嵌入的信息丰富性使模型能够聚焦于上下文细微差别,减少对关系特定动词等表面线索的依赖。除数据集外,我们还提供相关代码片段以促进可复现性,并推动该领域的进一步研究。