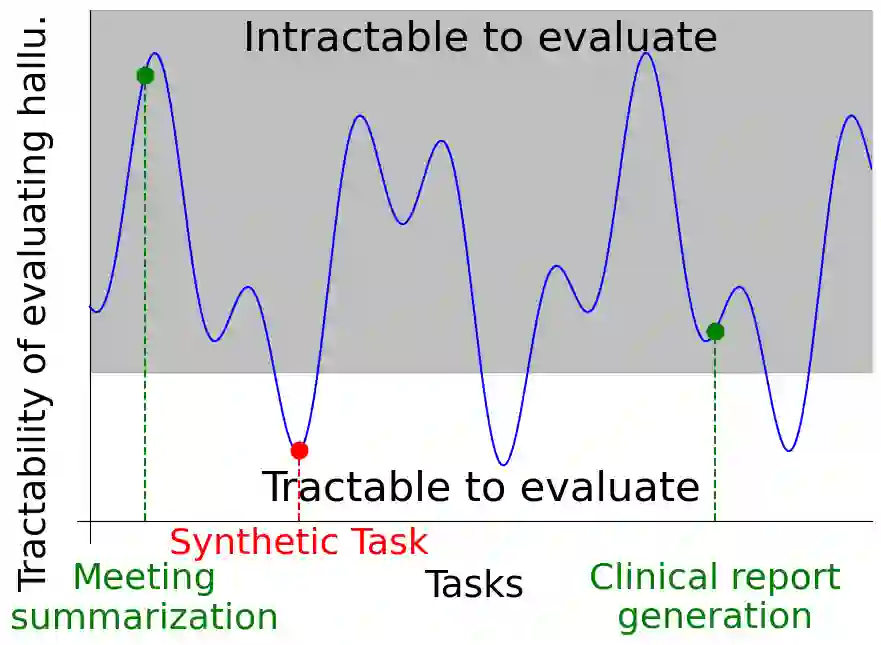
Large language models (LLMs) frequently hallucinate on abstractive summarization tasks such as document-based question-answering, meeting summarization, and clinical report generation, even though all necessary information is included in context. However, optimizing LLMs to hallucinate less on these tasks is challenging, as hallucination is hard to efficiently evaluate at each optimization step. In this work, we show that reducing hallucination on a synthetic task can also reduce hallucination on real-world downstream tasks. Our method, SynTra, first designs a synthetic task where hallucinations are easy to elicit and measure. It next optimizes the LLM's system message via prefix-tuning on the synthetic task, and finally transfers the system message to realistic, hard-to-optimize tasks. Across three realistic abstractive summarization tasks, SynTra reduces hallucination for two 13B-parameter LLMs using only a synthetic retrieval task for supervision. We also find that optimizing the system message rather than the model weights can be critical; fine-tuning the entire model on the synthetic task can counterintuitively increase hallucination. Overall, SynTra demonstrates that the extra flexibility of working with synthetic data can help mitigate undesired behaviors in practice.
翻译:大型语言模型(LLMs)在抽象摘要任务中频繁出现幻觉,例如基于文档的问答、会议摘要和临床报告生成,尽管所有必要信息都已包含在上下文中。然而,优化LLMs以减少这些任务中的幻觉具有挑战性,因为幻觉难以在每个优化步骤中高效评估。在本工作中,我们证明减少合成任务上的幻觉也能减少现实下游任务中的幻觉。我们的方法SynTra首先设计一个合成任务,在该任务中幻觉易于引发和测量。接着,通过前缀微调在合成任务上优化LLM的系统消息,最后将系统消息迁移到现实且难以优化的任务中。在三个现实抽象摘要任务中,SynTra仅使用合成检索任务作为监督,便减少了两个13B参数LLMs的幻觉。我们还发现,优化系统消息而非模型权重可能至关重要;对整个模型进行合成任务的微调反而可能增加幻觉。总体而言,SynTra证明了利用合成数据的额外灵活性有助于在实践中缓解不良行为。