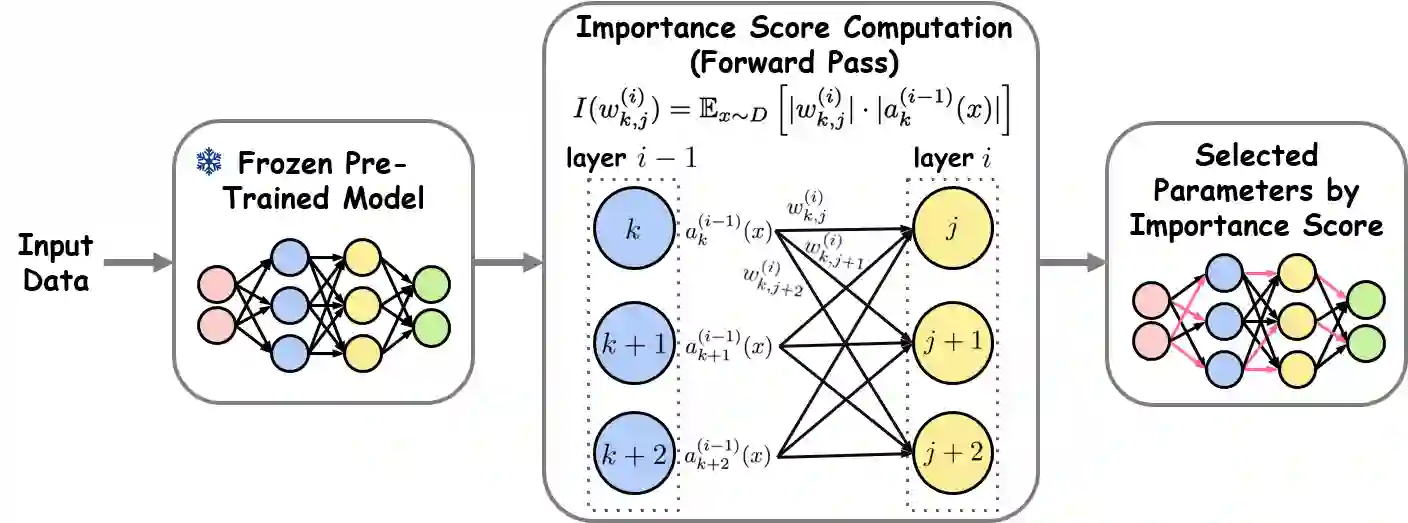
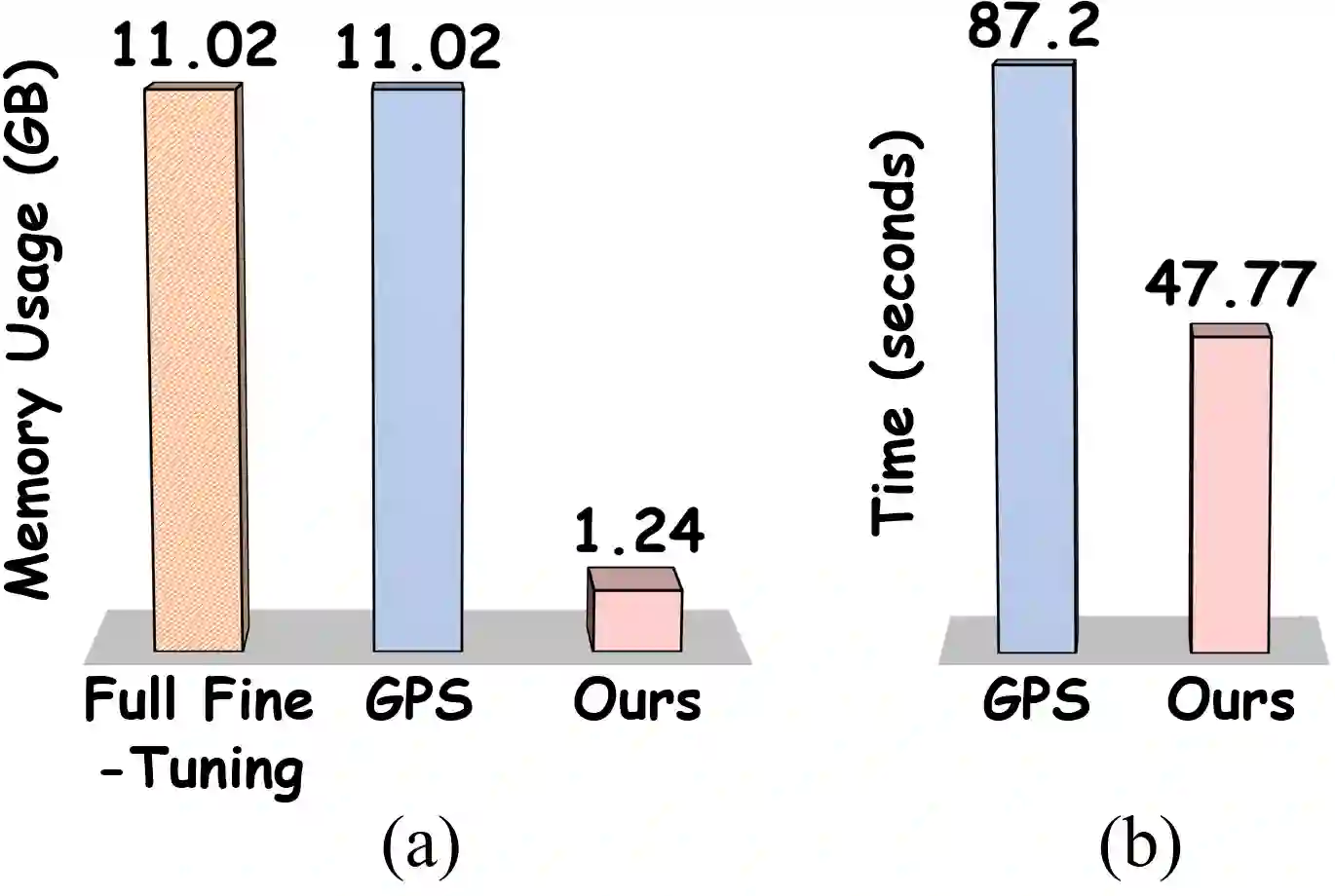
Parameter-Efficient Fine-Tuning (PEFT) has emerged as a key strategy for adapting large-scale pre-trained models to downstream tasks, but existing approaches face notable limitations. Addition-based methods, such as Adapters [1], introduce inference latency and engineering complexity, while selection-based methods like Gradient-based Parameter Selection (GPS) [2] require a full backward pass, which results in the same peak memory usage as full fine-tuning. To address this dilemma, we propose Feedforward-based Parameter Selection (FPS), a gradient-free method that identifies an optimal parameter subset in a single forward pass. FPS ranks parameters by the product of their magnitudes and corresponding input activations, leveraging both pre-trained knowledge and downstream data. Evaluated on $24$ visual tasks from FGVC and VTAB-1k, FPS achieves performance comparable to state-of-the-art methods while reducing peak memory usage by nearly $9 \times$ and accelerating parameter selection by about $2 \times$, offering a genuinely memory-efficient and practical solution for fine-tuning large-scale pre-trained models.
翻译:参数高效微调已成为将大规模预训练模型适配至下游任务的关键策略,但现有方法存在显著局限性。基于添加的方法(如适配器[1])会引入推理延迟与工程复杂度,而基于选择的方法(如基于梯度的参数选择[2])需执行完整反向传播,导致峰值内存占用与全参数微调相同。为解决这一困境,我们提出基于前馈的参数选择方法,这是一种无需梯度的单次前向传播参数优选方案。FPS通过参数幅值与其对应输入激活值的乘积对参数排序,同时利用预训练知识与下游数据。在FGVC和VTAB-1k的24个视觉任务评估中,FPS在保持与前沿方法相当性能的同时,将峰值内存占用降低近9倍,参数选择速度提升约2倍,为大规模预训练模型微调提供了真正内存高效且实用的解决方案。