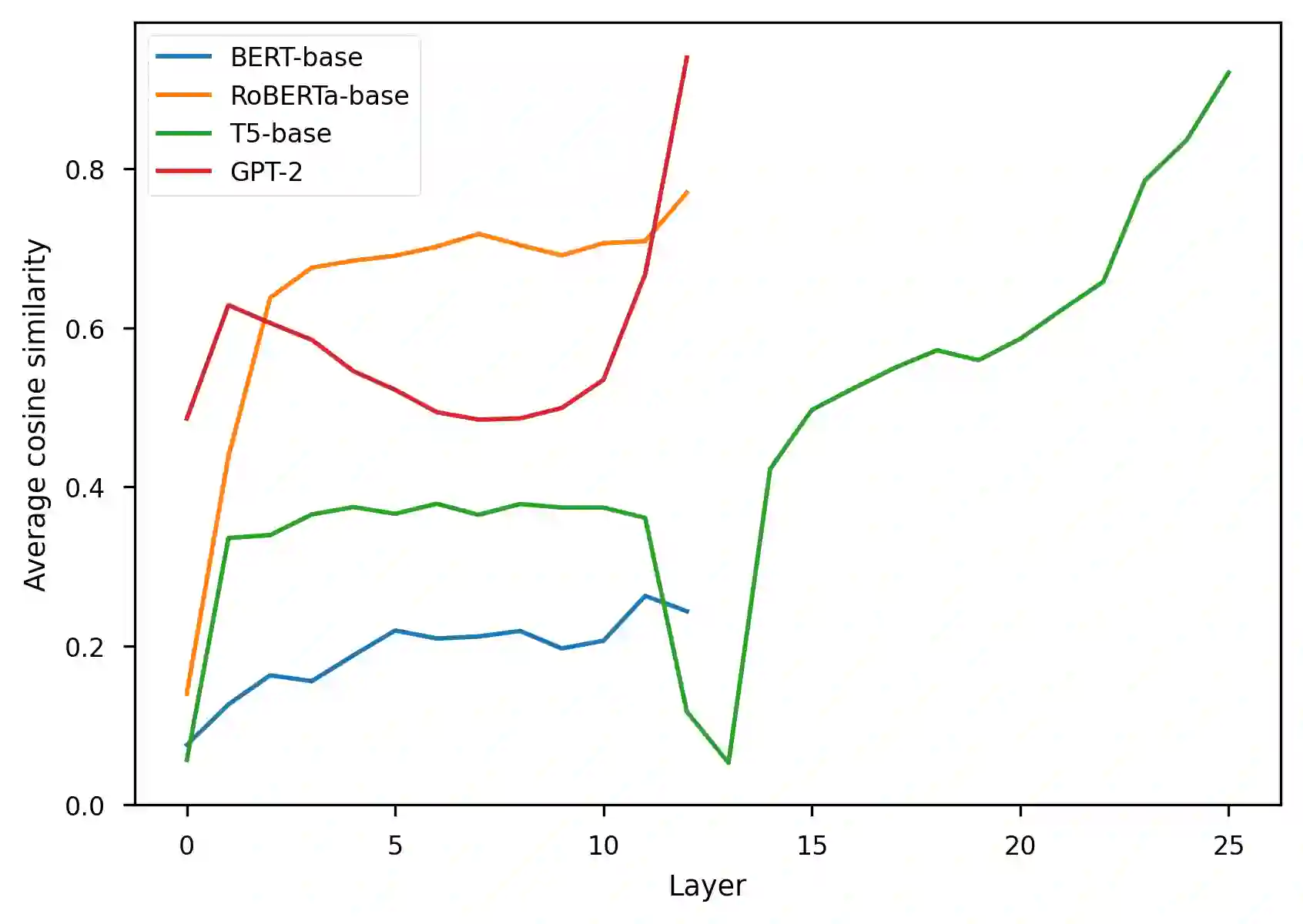
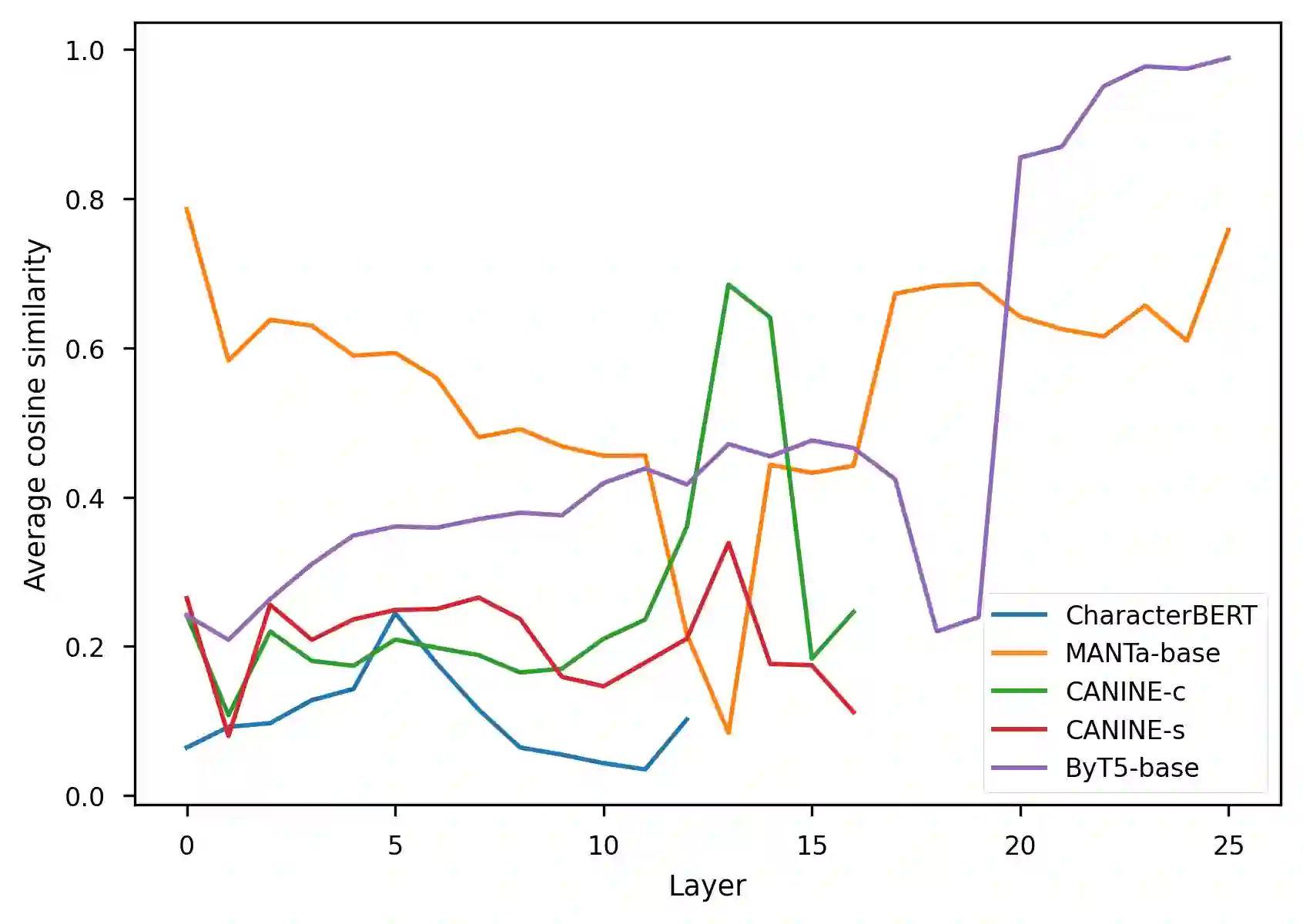
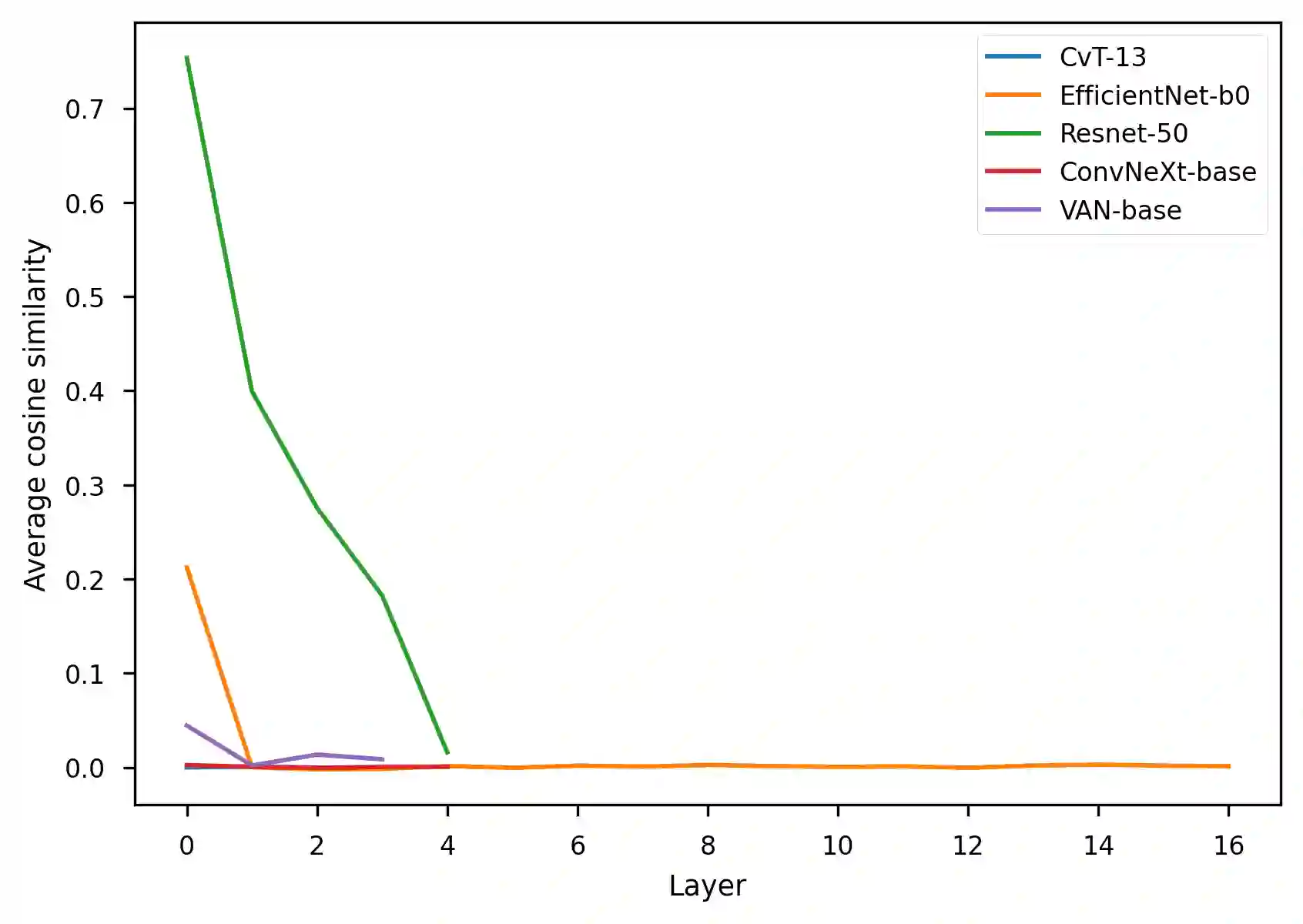
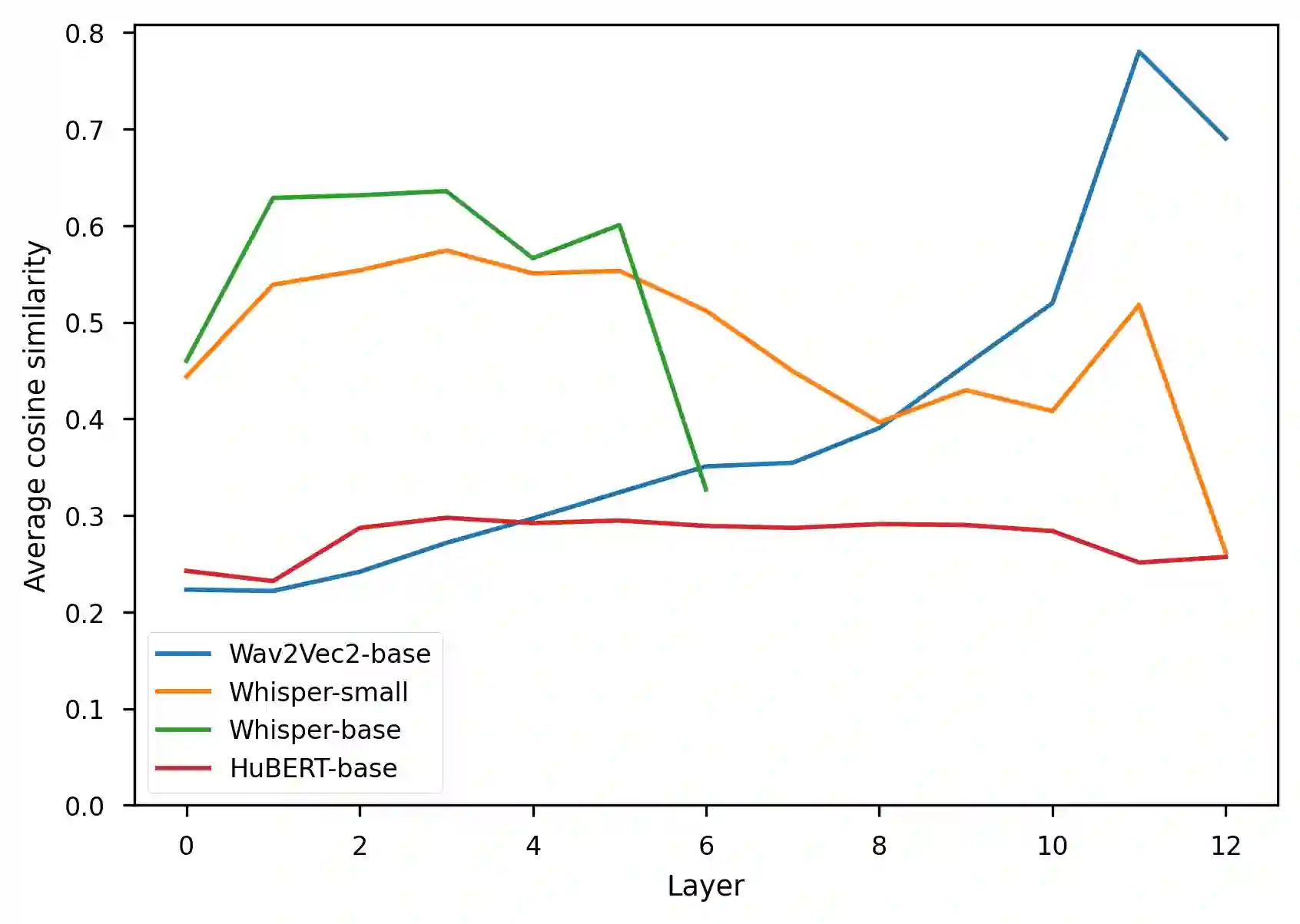
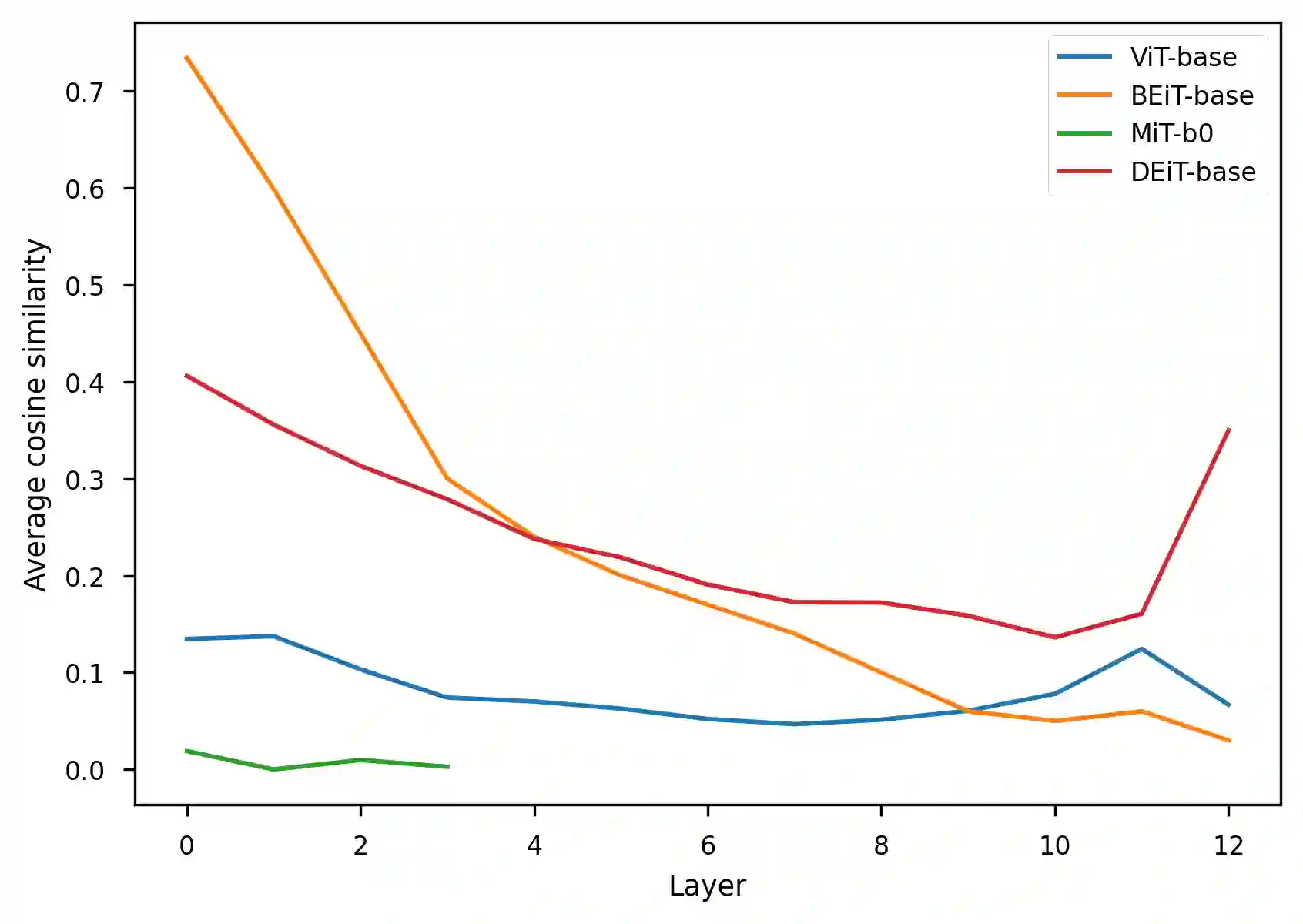
The representation degeneration problem is a phenomenon that is widely observed among self-supervised learning methods based on Transformers. In NLP, it takes the form of anisotropy, a singular property of hidden representations which makes them unexpectedly close to each other in terms of angular distance (cosine-similarity). Some recent works tend to show that anisotropy is a consequence of optimizing the cross-entropy loss on long-tailed distributions of tokens. We show in this paper that anisotropy can also be observed empirically in language models with specific objectives that should not suffer directly from the same consequences. We also show that the anisotropy problem extends to Transformers trained on other modalities. Our observations suggest that anisotropy is actually inherent to Transformers-based models.
翻译:表示退化问题是一种广泛存在于基于Transformer的自监督学习方法中的现象。在自然语言处理中,该现象表现为各向异性——即隐藏表示的一种奇异特性,使得它们在角度距离(余弦相似度)上异常接近。近期部分研究倾向于将各向异性归因于在长尾词分布上优化交叉熵损失的后果。本文证明,在具有特定目标函数的语言模型中,即使不直接受到相同损失函数的影响,各向异性仍可通过实验观测到。我们还发现各向异性问题可扩展至其他模态上训练的Transformer模型。我们的观察表明,各向异性实际上是基于Transformer的模型的固有属性。