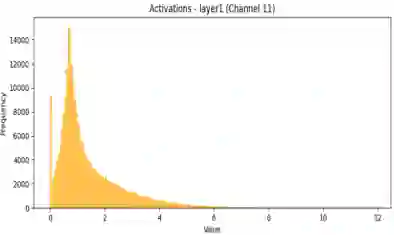
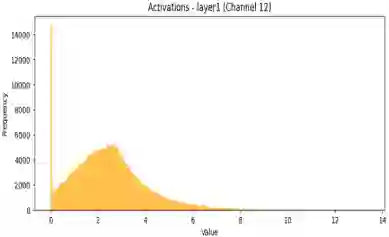
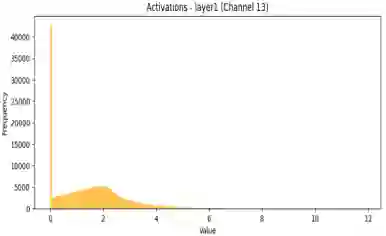
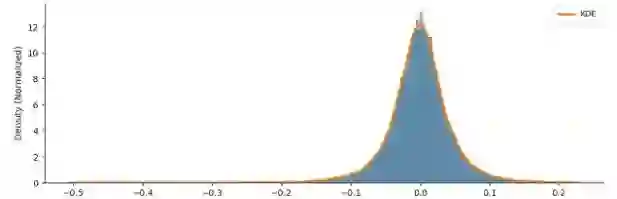
Quantization-Aware Training (QAT) is a critical technique for deploying deep neural networks on resource-constrained devices. However, existing methods often face two major challenges: the highly non-uniform distribution of activations and the static, mismatched codebooks used in weight quantization. To address these challenges, we propose Adaptive Distribution-aware Quantization (ADQ), a mixed-precision quantization framework that employs a differentiated strategy. The core of ADQ is a novel adaptive weight quantization scheme comprising three key innovations: (1) a quantile-based initialization method that constructs a codebook closely aligned with the initial weight distribution; (2) an online codebook adaptation mechanism based on Exponential Moving Average (EMA) to dynamically track distributional shifts; and (3) a sensitivity-informed strategy for mixed-precision allocation. For activations, we integrate a hardware-friendly non-uniform-to-uniform mapping scheme. Comprehensive experiments validate the effectiveness of our method. On ImageNet, ADQ enables a ResNet-18 to achieve 71.512% Top-1 accuracy with an average bit-width of only 2.81 bits, outperforming state-of-the-art methods under comparable conditions. Furthermore, detailed ablation studies on CIFAR-10 systematically demonstrate the individual contributions of each innovative component, validating the rationale and effectiveness of our design.
翻译:量化感知训练(QAT)是在资源受限设备上部署深度神经网络的关键技术。然而,现有方法通常面临两大挑战:激活值的分布高度非均匀,以及权重量化中使用的码本静态且不匹配。为应对这些挑战,我们提出自适应分布感知量化(ADQ),一种采用差异化策略的混合精度量化框架。ADQ的核心是一种新颖的自适应权重量化方案,包含三项关键创新:(1)基于分位数的初始化方法,构建与初始权重分布紧密对齐的码本;(2)基于指数移动平均(EMA)的在线码本自适应机制,以动态跟踪分布变化;(3)基于敏感度的混合精度分配策略。对于激活值,我们集成了一种硬件友好的非均匀到均匀映射方案。综合实验验证了本方法的有效性。在ImageNet上,ADQ使ResNet-18以仅2.81比特的平均位宽达到71.512%的Top-1准确率,在可比条件下优于现有最先进方法。此外,在CIFAR-10上的详细消融研究系统性地证明了各创新组件的独立贡献,验证了我们设计的合理性与有效性。