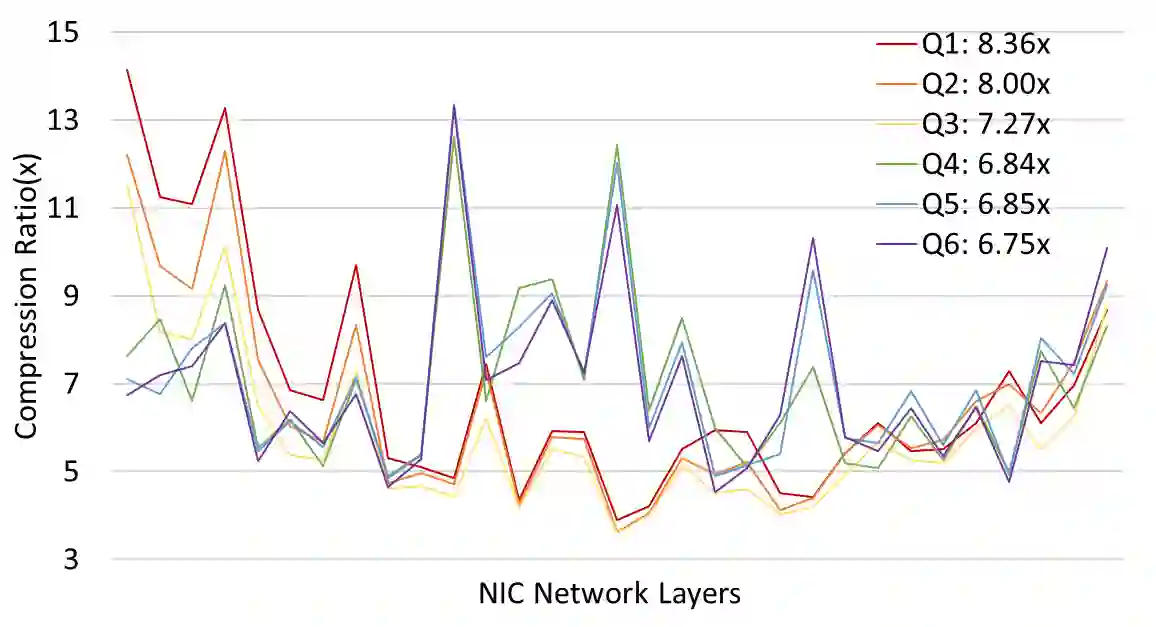
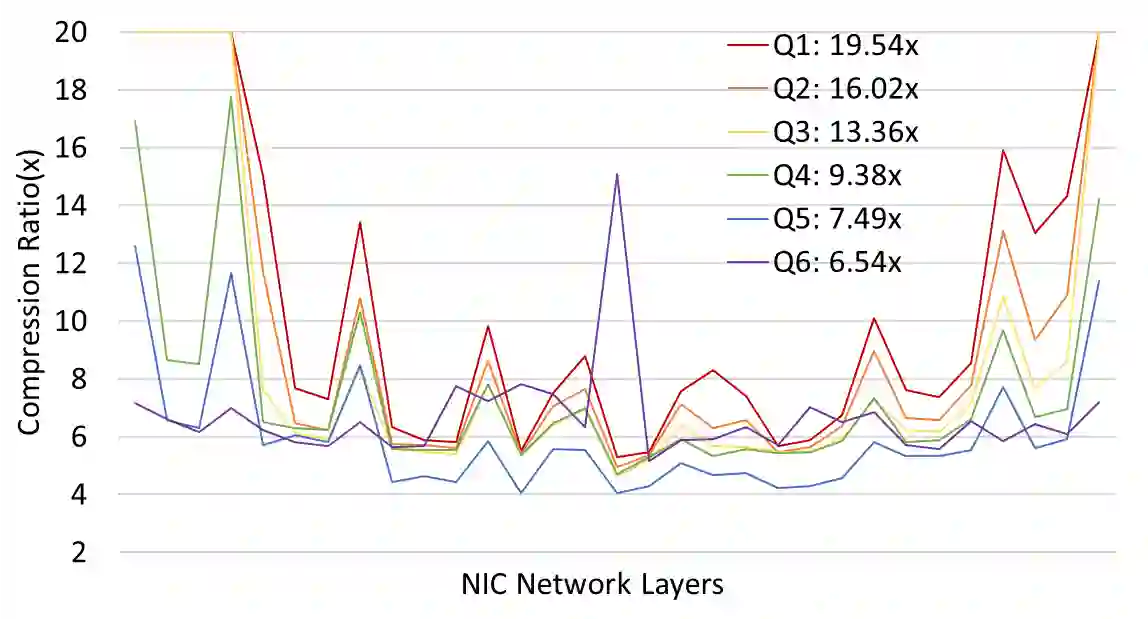
With neural networks growing deeper and feature maps growing larger, limited communication bandwidth with external memory (or DRAM) and power constraints become a bottleneck in implementing network inference on mobile and edge devices. In this paper, we propose an end-to-end differentiable bandwidth efficient neural inference method with the activation compressed by neural data compression method. Specifically, we propose a transform-quantization-entropy coding pipeline for activation compression with symmetric exponential Golomb coding and a data-dependent Gaussian entropy model for arithmetic coding. Optimized with existing model quantization methods, low-level task of image compression can achieve up to 19x bandwidth reduction with 6.21x energy saving.
翻译:随着神经网络深度增加和特征图尺寸增大,与外部存储器(或DRAM)之间有限的通信带宽和功耗约束成为在移动设备和边缘设备上实现网络推理的瓶颈。本文提出了一种端到端可微的带宽高效神经推理方法,通过神经数据压缩方法对激活值进行压缩。具体而言,我们提出了一种针对激活压缩的变换-量化-熵编码流水线,采用对称指数哥伦布编码以及基于数据相关的高斯熵模型进行算术编码。通过结合现有模型量化方法进行优化,图像压缩这一低层次任务可达到高达19倍的带宽缩减,同时实现6.21倍的能耗节省。