

论文链接:https://arxiv.org/pdf/2604.16042 * github 链接:https://github.com/PKU-PILLAR-Group/Survey-Intrinsic-Interpretability-of-LLMs
这几年,大语言模型越来越强,但一个老问题始终没有消失:我们到底能不能真正理解它为什么这样回答、为什么这样推理,又为什么会在某些场景下犯错甚至失控? 过去,主流做法大多是事后解释(post-hoc interpretability)。也就是说,先训练出一个性能很强但内部复杂的模型,再用特征归因、探针、LogitLens、稀疏自编码器、因果干预等方法,从外部去分析它。这样的研究非常重要,也确实帮助我们看到了不少模型内部规律。但它有一个根本局限:很多解释并不是模型真实计算过程本身,而是对这个过程的近似、投影或重建。论文中将这种问题概括为解释与真实计算之间的忠实性差距 (fidelity gap)。 也正因为如此,越来越多研究者开始把目光转向另一条路线:内生可解释性(intrinsic interpretability)。它追求的不是在模型训练完之后 “补一个解释器”,而是在模型结构、训练目标和信息流路径里,直接把可解释性嵌进去。换句话说,模型的 “解释” 不再是外挂,而是模型本身的一部分;这些可解释部件位于关键计算路径上,改动它们会直接影响模型输出。
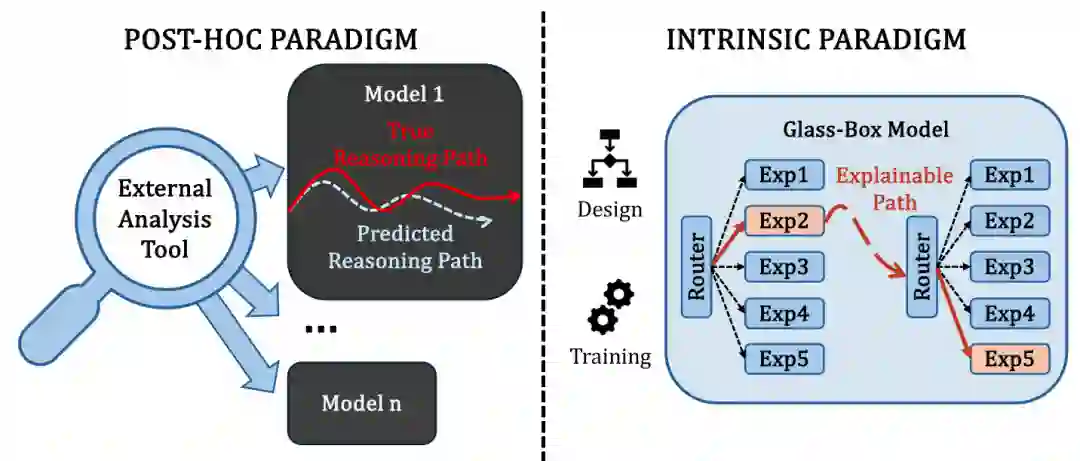
从 “解释黑箱” 到 “设计玻璃箱”,这是大模型可解释性研究中一个正在形成的重要转向。图 1 对比了两种范式:post-hoc 是在模型外部加分析工具,intrinsic 则是把解释性直接做进模型结构与训练路径中。 我们最近的一篇综述论文 《Towards Intrinsic Interpretability of Large Language Models: A Survey of Design Principles and Architectures》 被 ACL 2026 Main Conference 接收。这篇工作想回答的核心问题其实很直接:如果说过去的大模型可解释性研究主要在努力 “看清黑箱”,那么现在,一个更值得关注的问题是 —— 我们能不能把黑箱直接改造成更接近 “玻璃箱” 的系统? 论文系统梳理了这一方向的代表方法,并将现有工作总结为五类核心设计范式。
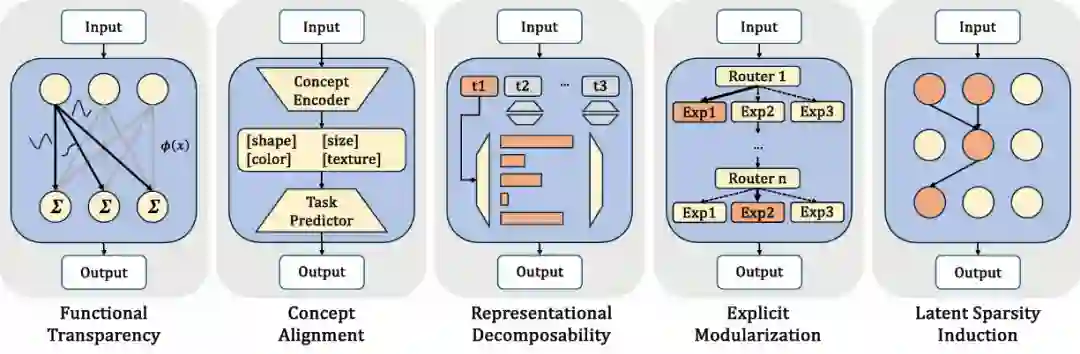
图 2 内生可解释性的五类设计范式,全文最核心的一张总览图。 在这篇综述中,我们将现有方法概括为五条路线:功能透明性(Functional Transparency)、概念对齐(Concept Alignment)、表征可分解性(Representational Decomposability)、显式模块化(Explicit Modularization)以及潜在稀疏性诱导(Latent Sparsity Induction)。这五类方法并不是简单按模型家族来分,而是按 “解释性是如何被构造出来的” 来分。也就是说,我们更关心:解释性究竟被放在了模型的哪个层面,又通过什么机制进入了真实计算路径。 先看第一类,功能透明性。这类方法强调:模型内部的计算过程本身就应该具有清晰结构和明确语义,而不是完全由难以拆解的稠密变换组成。论文中提到,这一方向的代表包括广义加性模型 (GAM),以及后续一些希望让运算本身更可读的结构设计(NAM, SENN, KAN)。它们的共同点是尽量把 “模型在算什么” 写清楚,让每个部分承担更明确的功能。代价也很明显:结构越透明,往往越容易受到表达能力和训练效率上的限制。 第二类是概念对齐。如果说功能透明性强调 “算得清楚”,那概念对齐更强调 “想得明白”。这类方法希望让模型中的某些中间变量,直接对应到人类可以理解的概念,比如属性、症状、主题或语义类别。概念瓶颈模型(CBM)就是其中的代表:模型先预测概念,再基于概念做下游判断。这样的好处是,我们可以直接看到模型是否在概念层面出了问题;但难点在于,人类概念本身不一定完整,也不一定总适合复杂语言任务。论文将这种代价概括为对齐成本 (alignment tax):当我们强行让表示更贴近人类理解方式时,模型的自由表达空间可能会受到约束。 第三类是表征可分解性。这条路线关注的是隐藏表示本身的组织方式。很多标准神经网络的表示高度纠缠,不同语义因素混在一起,很难说清某个维度究竟在表示什么。于是,一些工作尝试把表示拆成更独立的子空间、离散码本或更可分离的组成部分,让不同语义因素尽量存在于各自的空间。例如 Backpack Language Models 会把预测拆成更可解释的组成部分,尽量分离词义表示与上下文加权作用;而像 CoCoMix 这样的工作,则进一步把更高层的语义概念显式融入生成过程。这类工作的核心目标都是降低语义纠缠,提高表示层面的可读性与可操控性。 第四类是显式模块化。这是近年来与大模型架构结合得最紧密的一条路线之一,最典型的实现载体就是专家混合模型 (Mixture-of-Experts, MoE)。传统 MoE 更多是为了提升容量和效率,但论文指出,近来的不少工作开始把 “可解释性” 也纳入 MoE 的设计目标:例如,让 专家网络 更简单、更稀疏,或者让路由器的决策更具语义结构。这样一来,我们不只知道模型输出了什么,还能看到它调用了谁来完成这一步计算。
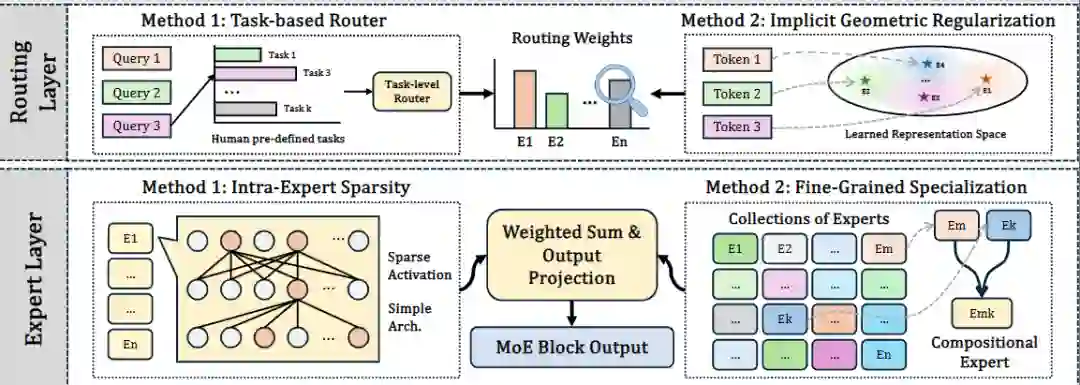
图 3 面向可解释性的 MoE 设计思路,包括专家网络内部稀疏化、细粒度分解,以及更有语义结构的路由机制。 第五类是潜在稀疏性诱导。这类方法通过稀疏约束、门控机制或结构化正则,让模型在训练过程中自己长出更清晰的激活路径与功能划分。比如,在 Transformer 中广泛使用的 GLU / SwiGLU 一类门控结构,就可以让不同输入激活不同的通路;而更进一步的稀疏训练(sparse training)方法,则直接在训练过程中施加强稀疏约束,促使模型形成更紧凑、也更容易解释的计算子电路。这类方法的核心直觉是:很多 “不可解释” 问题,本质上来自过度稠密和高度叠加;如果模型被迫更有选择地激活参数和通路,它的内部功能分工就更容易显现出来。 不过,这五类范式并不是互相排斥的标签。恰恰相反,论文特别强调,它们更像是五种设计原则,而不是五个彼此隔绝的技术盒子。现实中的很多方法会同时具备多种特征:既有模块化结构,也有概念监督;既依赖稀疏路由,也强调表示解耦。也正因为如此,内生可解释性并不是某一个单点技巧,而更像一种新的模型设计观:不是在模型训练完成后再问 “它为什么这么做”,而是在设计模型时就提前规定 “它应该以什么样的方式思考”。 如果把时间线再拉长一点看,这个方向本身也经历了明显演化。早期更偏向低容量、人工定义结构,比如 GAM 一类方法;而近年的研究则越来越转向能够兼顾性能与透明性的、数据驱动的稀疏架构与模块化架构。下面的图 4 就把这种演化过程很直观地展示了出来:整个领域正在从 “刚性、预定义、低容量” 的可解释模型,走向 “更灵活、更可扩展、同时保留可解释结构” 的现代架构。
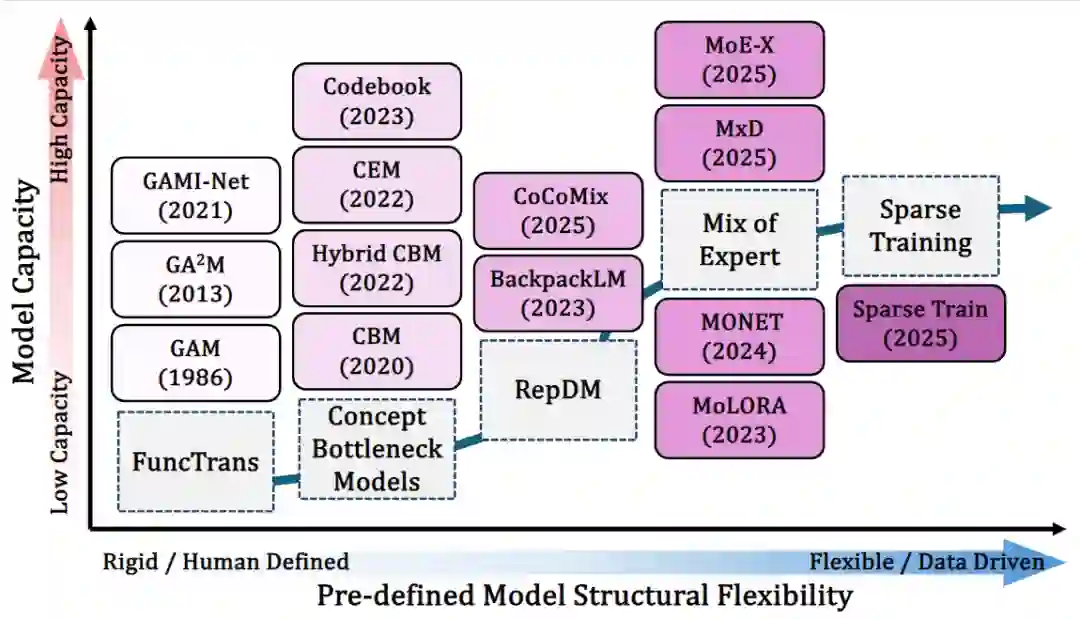
图 4 内生可解释性的发展脉络:从早期低容量、强先验的解释模型,逐步走向更灵活、更高容量、也更适合大模型时代的结构设计。 当然,这个方向还远没有成熟。论文总结了几个关键挑战。首先,定义和评估标准仍然不统一:什么才算真正的 “内生可解释”?仅仅有稀疏结构、模块化路径,是否就足够?其次,可解释性与性能之间的取舍仍然存在。虽然近年研究表明两者未必绝对冲突,但如何在大规模 LLM 上稳定实现 “既透明又强大”,仍然是开放问题。再次,很多方法在受控环境、小模型或局部模块上表现不错,但它们是否能稳健扩展到真正复杂的大模型系统,还需要更多验证。 但无论如何,一个趋势已经越来越清晰:大模型可解释性研究正在从 “观察模型” 走向 “设计模型”。这不只是方法层面的变化,更是研究视角的变化。过去,我们更像是在黑箱外部研究它;现在,我们开始认真思考,能不能在造这台机器的时候,就让它天然更容易被理解、被审计、被控制。 这或许就是内生可解释性最重要的意义。它不是单纯为了 “把论文讲得更好听”,也不是给模型套上一层解释包装,而是在通往更可信、更可控、更安全的大模型系统这条路上,提供一种更底层的可能性。 我们的这篇综述希望做的,正是为这个方向提供一个更系统的起点:一方面梳理已有方法背后的共同设计思想,另一方面也帮助研究者把 “可解释性” 从分析目标,真正推进为模型设计原则。对于大模型研究来说,这可能是一个值得长期投入的新起点。


