通用智能体(即无需领域特定工程即可在陌生环境中执行任务的系统)的愿景在很大程度上仍未实现。目前的智能体主要以专用型为主,尽管 OpenAI SDK Solo Agent 和 Claude Code 等新兴实现方案展示了更广泛能力的雏形,但尚未有人对其通用性能进行系统性评估。现有的智能体基准测试通常假定存在领域特定的集成,其任务信息的编码方式阻碍了对通用智能体的公平评价。 本文将通用智能体评估确立为一项核心研究目标(First-class research objective)。我们提出了此类评估的概念性原则、一种支持智能体与基准测试集成的“统一协议”(Unified Protocol),以及一个名为 Exgentic 的通用智能体评估实用框架。我们在六个环境中对五种主流智能体实现进行了基准测试,建立了首个“开放通用智能体排行榜”(Open General Agent Leaderboard)。实验结果表明,通用智能体具备跨多元环境的泛化能力,在无需任何环境特定调优的情况下,其性能可与领域专用智能体相媲美。 为奠定通用智能体系统化研究的基础,我们开源了评估协议、框架及排行榜:www.exgentic.ai。
1. 引言 (Introduction)
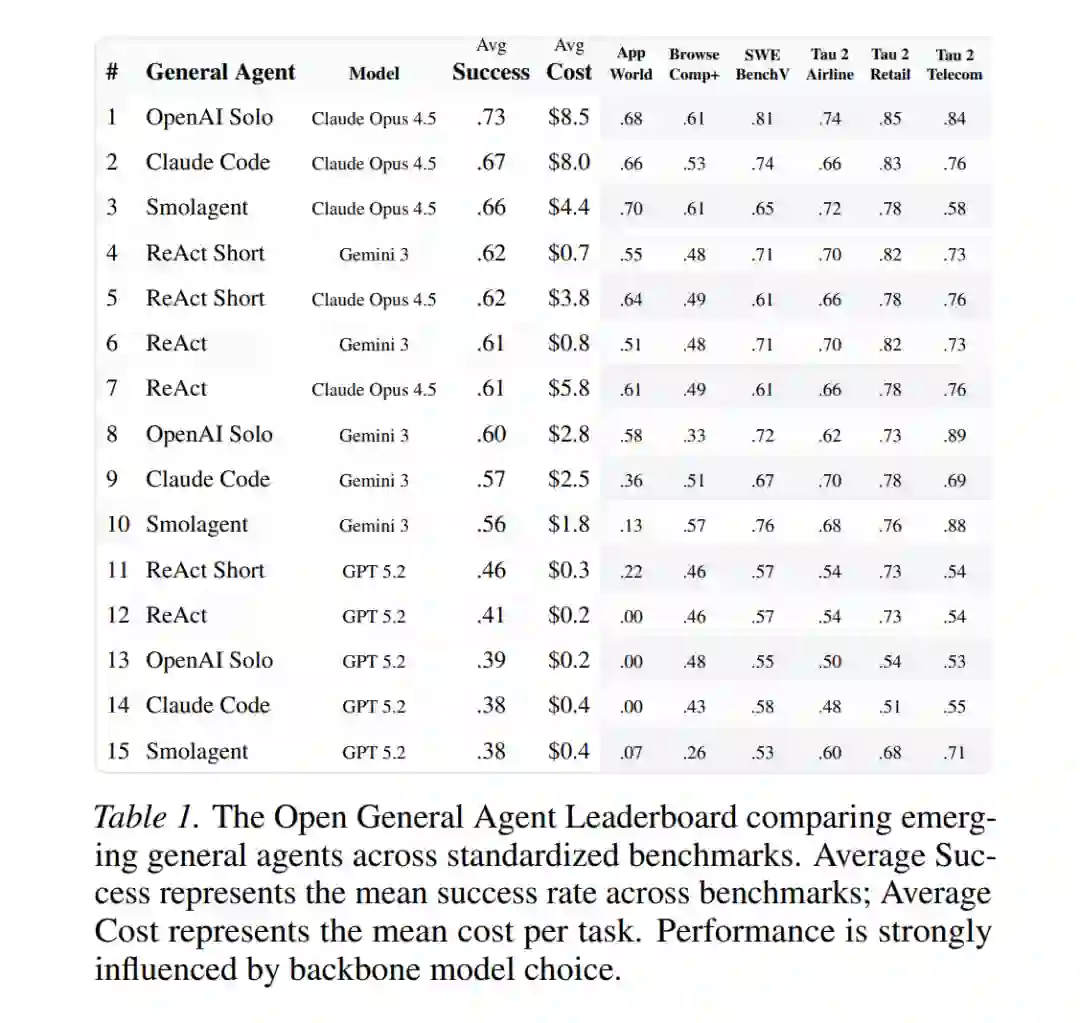
AI 智能体领域已取得显著进展,智能体系统在从软件工程任务处理到 Web 界面导航的多个领域展现出令人印象深刻的能力 (Zhang et al., 2024; Deng et al., 2023)。然而,目前的进展很大程度上依赖于领域专业化和手动调优;相比之下,异构的现实世界场景则需要无需此类手动定制即可实现规模化部署的通用智能体 (c.f., Marreed et al., 2025; Bandel et al., 2026)。 尽管通用智能体至关重要,但当前的评估实践无法对其能力进行充分评估。现有的智能体基准测试,如 SWE-Bench Verified (Jimenez et al., 2023) 和 $\tau^2$-Bench (Yao et al., 2024),虽为领域特定智能体提供了宝贵的评估,但它们存在的两项约束阻碍了通用智能体评估:首先,它们使用定制化的通信协议 (Anonymous, 2026);其次,它们隐式地假设智能体预先掌握了基准测试特定的目标和环境语义。 近期的整合工作,如 BrowserGym (Chezelles et al., 2025) 和 Harbor (Shaw, 2025),通过向智能体暴露当前目标和环境语义,在单一领域内集成了多个基准测试(见图 2(B))。尽管这迈出了一步,但这些框架仍强制执行单一协议(BrowserGym 为基于 Web 的协议,Harbor 为基于 CLI 的协议),这限制了智能体使用其原生集成机制,实际上评估的是智能体的“阉割版本” (Yehudai et al., 2025)。 我们将通用 AI 智能体作为研究目标,提出了一种具体的评估方法,并首次对跨多元环境的通用智能体进行了系统性分析(见图 3)。具体而言,本文的贡献有三个方面: 1. 提出统一协议(Unified Protocol):这是一种基准测试与智能体之间的中继协议(见图 2(C))。该协议通过规范化的任务表示,桥接了智能体接口(如 CLI、工具调用 API、MCP)与基准测试之间的通信,实现了评估过程与领域特定实现及通信协议的解耦。 1. 发布 Exgentic 评估框架:基于统一协议,我们发布了 Exgentic。这是一个针对通用智能体的评估工具集,支持模块化深度分析——包括架构对比、语言模型影响分析以及智能体-模型配对优化。 1. 建立开放通用智能体排行榜(Open General Agent Leaderboard):运行 Exgentic 框架,我们提出了首个公开的开放通用智能体排行榜以引导该领域开发,总计评估成本为 2.2 万美元(见表 1)。
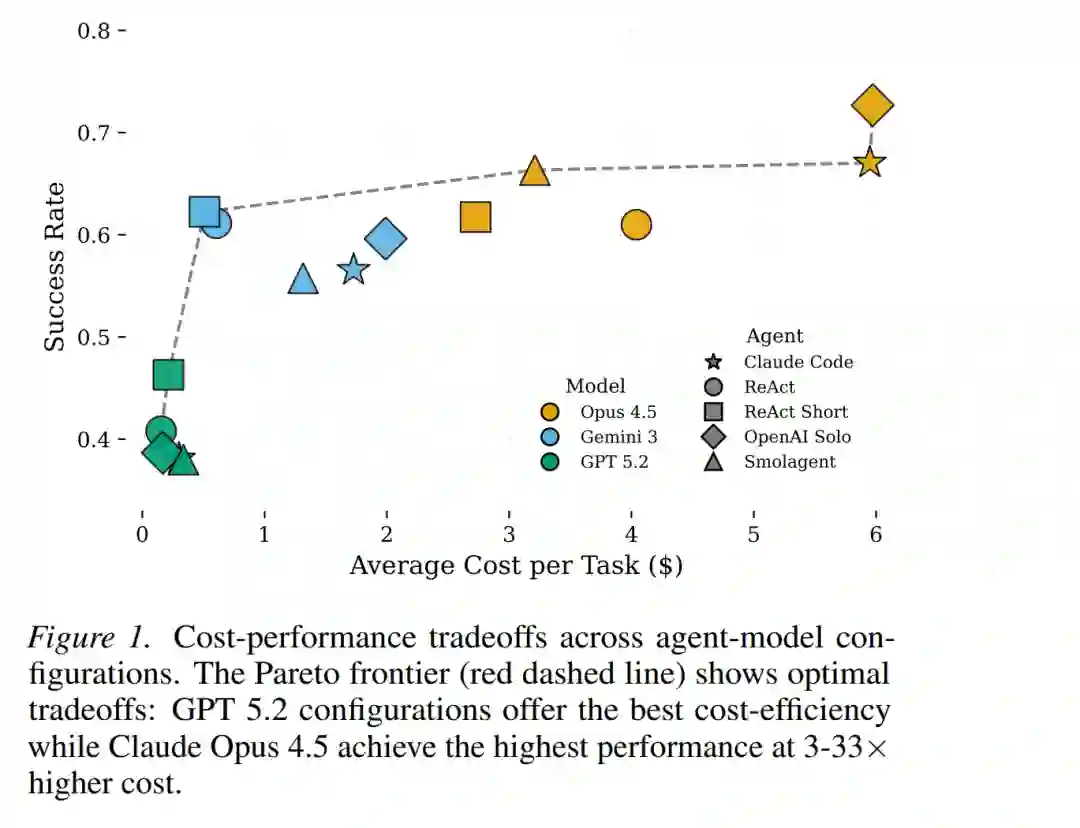
我们对该排行榜的分析凸显了当代通用智能体的能力与局限。虽然这些智能体展现了显著的跨领域泛化能力——其性能通常与领域优化的基准线持平——但其成功主要由底层语言模型决定(见图 1)。相反,不同的智能体脚手架(Agentic Scaffolds)表现出相近的性能,但在成本上存在巨大差异。这些发现共同指明了通用智能体的潜力。 最后,推进通用智能体需要集体努力。我们希望“开放通用智能体排行榜”能成为超越单一任务方法的催化剂,并邀请研究社区通过贡献具有泛化挑战性的基准测试和新型评估协议来扩展这一生态系统。