

基于能量的预测世界模型通过对隐能量地形(latent energy landscapes)进行推理,而非直接生成像素,为多步视觉规划提供了一种高效方案。然而,现有方法仍面临两大核心挑战:其一,其隐表征通常在欧几里得空间(Euclidean space)中学习,忽略了状态间潜在的几何属性与层级结构;其二,这类模型在长程预测(long-horizon prediction)中表现乏力,导致在长时段推演(rollouts)中性能迅速衰减。 为解决上述问题,我们提出了 GeoWorld。这是一种几何世界模型,通过引入双曲联合嵌入预测架构(Hyperbolic JEPA),将隐表征从欧几里得空间映射至双曲流形(hyperbolic manifolds),从而有效地保留了层级关系与几何结构。此外,我们提出了一种用于能量优化驱动的**几何强化学习(Geometric Reinforcement Learning)**方法,实现了双曲隐空间内稳定的多步规划。在 CrossTask 和 COIN 数据集上的广泛实验表明,相较于当前最先进的 V-JEPA 2 模型,GeoWorld 在 3 步规划任务中将成功率(SR)提升了约 3%,在 4 步规划任务中提升了约 2%。
1. 引言 (Introduction)
自回归(Autoregressive, AR)下一标记预测(next-token prediction)赋予了大语言模型 (LLMs) [79] 和视觉语言模型 (VLMs) [20, 53] 广泛的世界知识与推理能力,使其能够有效应对涉及搜索 [78]、推理 [32, 33, 44] 及规划 [8, 35, 65, 82] 的复杂任务。尽管 LLMs 的成功源于对语言空间的建模(这被视为获取人类水平知识的一种捷径 [48]),但它们仍无法完全表征真实世界的丰富信息,例如物理与几何属性 [3]。在现实世界中,人类及生物认知主要通过视觉信息而非单纯依赖语言来获取知识,因为视觉提供的信息带宽远高于语言 [62]。例如,人类婴儿在发育出语言系统之前的最初几个月里,主要通过视觉感知进行学习 [38];而某些动物则根本不具备语言能力 [18]。因此,研究者提出了仅从视觉输入(如视频)中学习的世界模型 [3, 5, 46, 59, 63],并通过生成式(Generative)或预测式(Predictive)方法进行规划。 生成式世界模型 [46, 59, 63] 显式地生成像素或可解码为像素的隐视觉标记(latent visual tokens),以便一次仅预测一步 [67]。因此,它们缺乏对完整轨迹结构或多步能量地形(energy landscape)的感知。相比之下,以 JEPA [41] 为代表的预测式世界模型 [2, 3, 5, 29] 则不生成像素。相反,它们在隐空间(latent space)中学习一种能量地形,用以衡量当前状态与目标状态之间的兼容性。这使得多步层次化规划(multi-step hierarchical planning)成为可能:高层推理负责最小化隐空间中的能量,而底层模块则填充物理细节。 然而,现有的基于能量的预测式世界模型面临两大严峻挑战: 1. 几何忽视(Geometric neglect):尽管预测式模型在隐空间中进行多步层次化规划,但其表征通常是在欧几里得空间(Euclidean space)中学习的,未能保留状态间潜在的几何关系。因此,所学得的能量地形无法捕获隐状态之间具有意义的测地距离(geodesic distances)或层级嵌入(hierarchical embeddings) [51],从而削弱了模型在长程范围内进行几何一致性规划的能力。 1. 多步缺陷(Multi-step shortcoming):多步视频数据稀缺且获取成本高昂,因此现有的预测式模型主要基于单步视频转换进行训练 [12, 31, 37, 40, 47, 66]。尽管从概念上讲,在整个轨迹上学习能量地形可以实现长程规划,但其性能随规划步数的增加而迅速下降,暴露了模型在长程时间依赖性建模上的弱点。
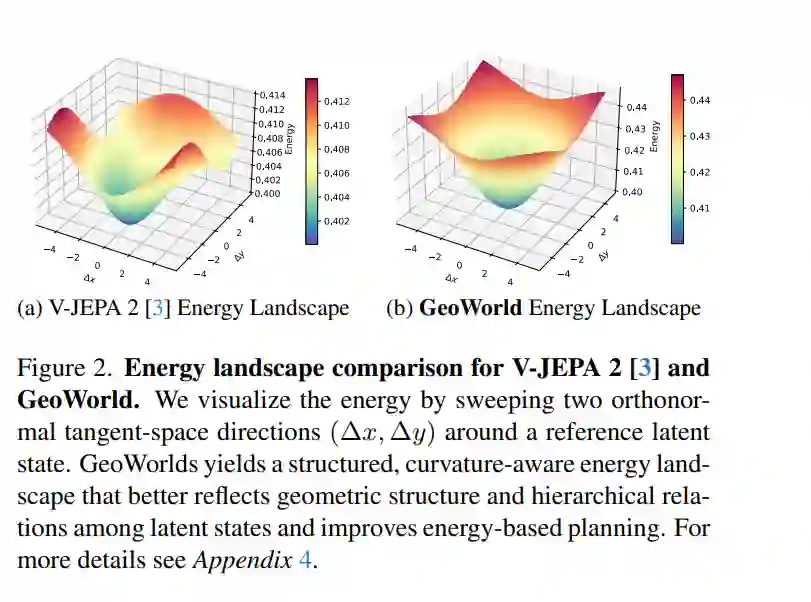
我们的出发点是从几何视角解决上述问题。针对第一个挑战,需要一个几何感知(geometry-aware)的世界模型,在学习层次化规划的能量地形时保留几何属性。针对第二个挑战,强化学习 (RL) 已被证明在预训练基础模型的输出不尽如人意时,能有效对其进行微调 [54, 60]。因此,需要一种几何感知强化学习方法,在隐流形(latent manifold)上获取最优轨迹,从而提升模型的多步规划能力。 据此,我们引入了几何世界模型 (GeoWorld)。如图 1 所示,该方法通过保留隐空间中的几何结构与层级感知,增强了基于能量的预测式世界模型。 * 为了应对第一个挑战,我们提出了双曲 JEPA (Hyperbolic JEPA, H-JEPA)。它将隐表征从欧几里得空间 $\mathbb{R}^n$ 映射到双曲流形(hyperbolic manifold)$\mathbb{H}^n$ 上,其中测地距离能够自然地编码状态间的层级关系。通过沿双曲测地线学习动力学,H-JEPA 在多步预测过程中保留了隐空间几何,确保学得的能量地形与物理世界的潜在结构一致,并支持几何一致性规划(如图 2 所示)。 * 为了应对第二个挑战,我们设计了几何强化学习 (Geometric Reinforcement Learning, GRL)。它将多步规划重新定义为对基于能量的价值函数的优化,其中较低的双曲能量对应较高的累积回报。GRL 直接优化世界模型的预测器(predictor),无需训练额外的策略或奖励模型。通过利用**双曲测地线最小化(hyperbolic geodesics minimization)和三角不等式正则化(triangle inequality regularization)**来调整预测器的能量价值表征,GRL 强制模型在隐流形上产生测地线一致的推演(rollouts),有效提升了长程稳定性和规划性能。
为了验证本方法在长程规划上的能力,我们在标准基准数据集(包括 CrossTask [88] 和 COIN [71])上评估了多步目标条件视觉规划任务。GeoWorld 相比此前最先进的预测式世界模型 V-JEPA 2 实现了持续改进,在两个数据集上的 3 步规划中成功率 (SR) 提升了约 3%,4 步规划中提升了约 2%。 本工作的贡献总结如下:
引入了 几何世界模型 (GeoWorld) 及 双曲 JEPA (H-JEPA)。通过将隐表征映射至双曲流形并沿双曲测地线学习动力学,该模型保留了几何结构与层级关系,为多步预测和规划构建了几何一致的能量地形。 * 提出了 几何强化学习 (GRL)。这是一个基于能量的优化框架,通过双曲能量最小化和三角不等式正则化直接优化预测器,实现了测地线一致的推演,增强了长程规划的稳定性。 * 在 CrossTask 和 COIN 数据集上的长程目标条件视觉规划中展现了强劲性能,相比 V-JEPA 2,在 3 步和 4 步规划中分别实现了约 3% 和 2% 的成功率提升。