

超越语言建模:多模态预训练技术探究
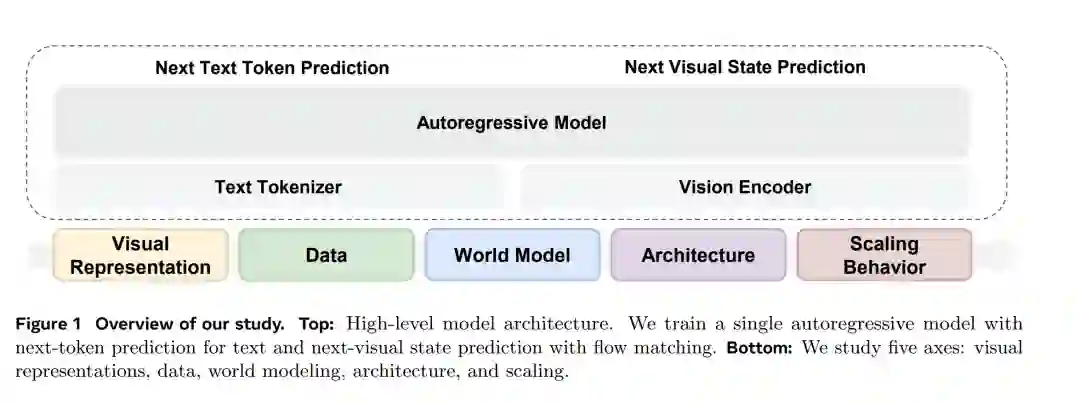
视觉世界为推动基础模型超越语言范畴提供了关键维度。尽管该方向的研究兴趣日益增长,但原生多模态模型的设计空间依然模糊。本文通过受控的、从零开始的预训练实验提供了实证层面的清晰见解,在排除语言预训练干扰的情况下,分离出主导多模态预训练的核心因素。我们采用了 Transfusion 框架——即对语言使用下一 Token 预测(Next-token Prediction),对视觉使用扩散机制(Diffusion)——在包括文本、视频、图文对、乃至动作条件视频在内的多样化数据上进行训练。 我们的实验得出了四个核心见解: 1. 表示自编码器(RAE):通过在视觉理解与生成任务上同时展现卓越性能,RAE 提供了一种最优的统一视觉表示; 1. 模态协同性:视觉与语言数据具有互补性,能够为下游任务能力产生协同效应; 1. 世界建模(World Modeling):统一的多模态预训练自然地导向了世界建模,其各项能力从通用训练中自发涌现; 1. 混合专家架构(MoE):MoE 不仅实现了高效且强大的多模态缩放(Scaling),同时自然地诱导了模态专业化分工。
通过 IsoFLOP 分析,我们计算了两种模态的缩放法则,并揭示了缩放不对称性(Scaling Asymmetry):视觉模态对数据的渴求程度显著高于语言。我们证明,MoE 架构能够调和这种缩放不对称性——它既提供了语言所需的高模型容量,又适应了视觉的数据密集型特性,从而为构建真正统一的多模态模型铺平了道路。 项目主页:https://beyond-llms.github.io/
1 引言 (Introduction)
基础模型时代在很大程度上是由语言预训练的成功所定义的 (OpenAI, 2022; Google, 2023)。通过在数万亿文本 Token 上缩放自回归模型,我们创建了具备卓越推理能力的系统。然而,从根本上说,文本是人类的一种抽象——是对现实的一种有损压缩。借用柏拉图的“地穴寓言” (Plato, 375 BCE) 来比喻:语言模型已经精通了对墙上阴影的描述,却从未见过投射这些阴影的实物。它们很好地捕捉了符号,却遗失了物理世界中高保真度的物理学、几何学和因果关系。 除了这一哲学层面的局限外,还存在一个现实的硬性瓶颈:高质量文本数据是有限的,且正趋于枯竭 (Sutskever, 2025)。相比之下,视觉世界在“洞穴之外”拥有无穷无尽的信号流,捕捉到了语言所遗漏的原始现实动态。因此,未来的道路要求我们超越阴影,直接对源头进行建模。我们将目光转向统一多模态预训练,不再将视觉信号视为辅助输入,而是将其视作与语言对等的“一等公民”。 目前,统一多模态预训练的科学版图在很大程度上仍是不透明的。虽然近期的研究 (Wang et al., 2024; Zhou et al., 2025a; Cui et al., 2025) 已开始迈出纯语言预训练的范畴,但其设计空间充满了混杂变量。大多数当前的方法论 (Liao et al., 2025; Deng et al., 2025) 并非从零开始同时学习视觉和语言,而是依赖于预训练语言模型的初始化 (Grattafiori et al., 2024; Yang et al., 2025a)。这种范式优先考虑保留现有的语言能力,同时使模型适配多模态。此外,嵌入在这些预训练骨干网络中的既有知识,掩盖了关于多模态训练本身所能得出的结论,导致很难理清哪些能力源于统一训练,哪些又继承自语言预训练。因此,视觉与语言之间的基本动态及缩放关系仍未得到充分理解。 在本文中,我们力求为这一领域提供实证层面的清晰见解。我们完全聚焦于预训练阶段,因为模型的核心能力主要是在此阶段获得的 (Zhou et al., 2024)。我们使用 Transfusion 框架从零开始训练单个模型——对语言采用下一 Token 预测,对视觉采用扩散机制——训练数据涵盖文本、视频、图文对以及动作条件视频。我们通过受控实验来隔离关键变量,并在涵盖语言评测、视觉理解/生成以及世界建模规划能力的广泛任务光谱上进行评估。 具体而言,我们研究了以下维度: * 视觉表示:我们评估了从变分自编码器(VAE)、语义表示到原始像素的广泛视觉表示形式。我们确定了表示自编码器(RAE)为最优表示方案。(第 3 节) * 数据:我们研究了从纯文本、纯视频到成对图文及动作条件视频的多种数据混合方案。我们发现模态间的干扰极小,在某些情况下甚至观察到了正向协同效应。(第 4 节) * 世界建模:我们将评估扩展到导航世界模型(NWM)设定中,将动作直接格式化为文本 Token。我们证明了物理预测能力主要源于通用多模态预训练(如视频),而非特定领域数据。(第 5 节) * 架构:我们研究了在统一多模态设置下混合专家架构(MoE)的设计选择,并观察到了模态分离与统一的自然形成。(第 6 节) * 缩放特性:我们进行了 IsoFLOP 实验,推导出了统一预训练期间视觉与语言的缩放法则。我们揭示了一种缩放不对称性,即视觉模态对数据的渴求程度显著高于语言,并发现 MoE 架构能有效弥合这一差距。(第 7 节)
