
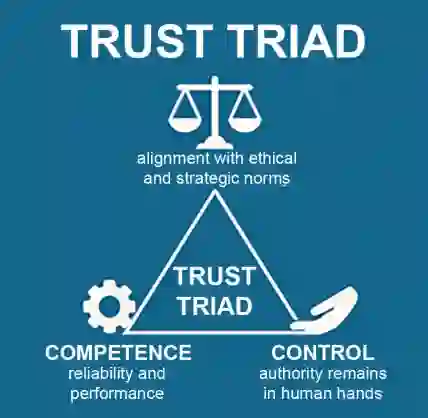
随着大型语言模型从语言奇观演变为战略工具,军方必须面对一个关键问题:何时以及如何能够信任这些机器?本文提出一个务实的框架,用于评估大型语言模型在军事决策背景下的可信度。借鉴成熟的人类信任模型并针对算法时代进行调整,“信任三角”——品格、能力与控制——为高级军事领导者提供了一种结构化方法,用以评估旨在增强而非取代人类判断的大型语言模型。
分析涵盖了军事决策支持的全过程,从数据聚合到兵棋推演与规划。分析表明,尽管大型语言模型在加速常规参谋任务方面已具实用性,但将其整合到更具分析性和操作性的角色中,则需要新的可信度标准。利用源自TrustLLM评估套件的加权指标,本文对当前模型进行了比较评估,揭示了它们在伦理对齐、事实可靠性及压力下的鲁棒性方面存在的显著差异。
结论清晰但非最终定论:没有模型是完美的,但某些模型比其他模型更适合军事用途——并且它们正在快速改进。本文还指出了当前评估框架中的关键差距,特别是在衡量透明度与可问责性方面。为解决这些问题,建议对诸如透明度评估分数和归因可追溯性分数等标准化指标进行进一步研究。信任,无论在战争还是技术中,都是赢得的。本文旨在帮助军事领导者区分仅仅是能够执行的系统,与那些值得指挥层信赖的系统。
成为VIP会员查看完整内容
相关内容

最新内容
相关VIP内容
相关资讯