摘要
视频生成模型已崭露头角,成为物理世界的高保真模型。这类模型能够根据多模态用户输入,合成高质量视频,从而捕捉智能体(Agents)与环境之间细粒度的交互。凭借其卓越的能力,视频生成模型解决了基于物理的仿真器(Physics-based Simulators)长期面临的诸多挑战,推动了其在机器人等多个领域的广泛应用。例如,视频模型无需引入过度简化的假设,即可实现照片级真实感且符合物理规律的变形体仿真(Deformable-body Simulation),从而突破了传统物理仿真的主要瓶颈。此外,视频模型可作为基础世界模型(Foundation World Models),以细粒度且具有强表达能力的方式捕捉世界动态,进而克服了纯语言抽象在描述错综复杂的物理交互时表达能力有限的问题。
本文综述了视频模型及其作为机器人具身世界模型(Embodied World Models)的应用,涵盖模仿学习(Imitation Learning)中的高效数据生成与动作预测、强化学习(Reinforcement Learning)中的动力学与奖励建模,以及视觉规划和策略评估等方面。进一步地,我们重点探讨了阻碍视频模型在机器人领域可信集成的关键挑战,包括指令跟随能力弱、幻觉问题(如违反物理规律)、不安全内容生成,以及数据整理、训练和推理成本高昂等根本性限制。最后,我们针对这些开放性研究挑战提出了未来的研究方向,旨在激发相关研究,最终推动其在安全关键型场景(Safety-critical Settings)等更广泛领域的应用。 关键词: 视频生成模型,世界建模,视觉规划,策略学习与评估

1. 引言 (Introduction)
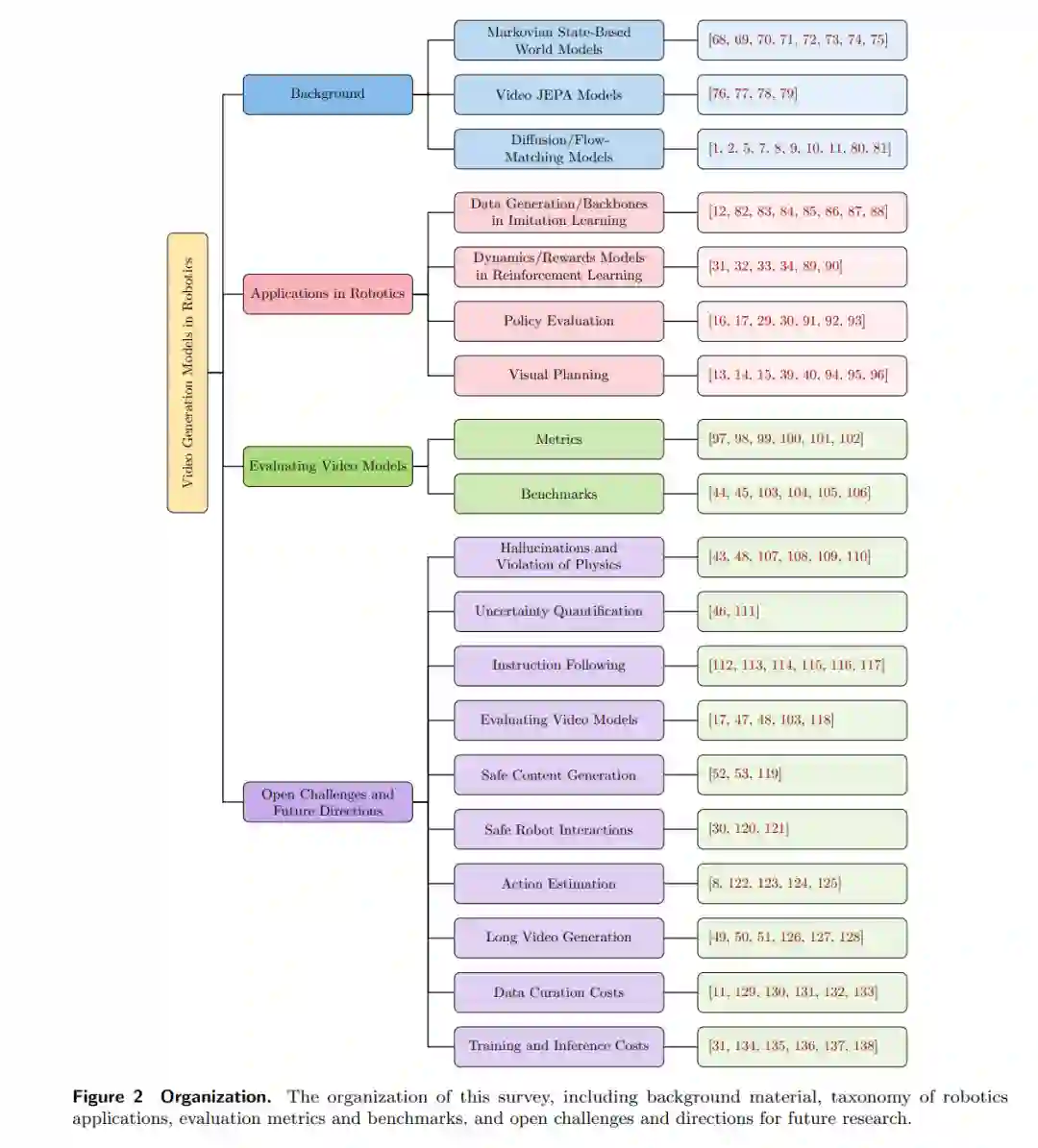
生成式建模(Generative Modeling)领域的最新突破,例如扩散模型(Diffusion)和流匹配(Flow-matching)[1, 2],已通过文本提示词、机器人动作和视频帧等用户输入,实现了高保真的可控视频合成。通过在互联网规模的数据上进行训练,最先进(SOTA)的视频模型学会了生成丰富的内容,捕捉美学和动态(运动)效果(例如电影级布光、相机运动以及智能体之间的物理交互),从而推动了视频编辑和内容创作领域的广泛应用 [3–11]。得益于其令人印象深刻的零样本泛化能力(Zero-shot Generalization)[18],这些模型正日益被整合到机器人领域中,例如用于机器人数据生成、视觉规划、策略学习和策略评估 [12–17]。在本综述中,我们将回顾视频模型,重点阐述其能力、在机器人领域的应用及其局限性。 大型视觉语言模型(VLMs/LLMs)[19–21] 的出现,凭借其卓越的语言生成和常识推理能力,显著改变了众多问题领域(如自然语言处理、计算机视觉、机器人学等)的技术现状。通过在互联网规模数据上的预训练,大语言模型习得了解决广泛任务所需的广博基础知识,从而涌现为令人惊叹的零样本 AI 模型。例如,VLM 已成为 SOTA 视觉-语言-动作(Vision-Language-Action, VLA)机器人策略的主干网络 [22–24],使机器人能够使用单一(统一)策略替代多个特定任务策略来执行多样化任务。尽管能力卓越,语言模型仍面临一些重要的局限性。首先,纯语言抽象(Language-only Abstractions)缺乏高效捕捉物理世界内在错综复杂交互过程所需的表达力。例如,考虑创建一个简洁且细粒度的描述,用以刻画机器人夹爪与目标变形物体(如布料)之间的接触交互任务。由于信息密度极高且语言容量有限,此类任务极具挑战性。其次,以语言为中心的建模难以准确模拟现实世界现象(事件)之间的时空依赖关系,而这对全面理解物理世界至关重要。虽然基于物理的仿真器(Physics-based Simulators)提供了视觉世界建模能力,但其实际有效性受到若干根本性挑战的限制。特别是,基于物理的仿真通常需要限制性的简化假设,这阻碍了其预测结果在视觉和物理上的保真度。例如,物理引擎需要昂贵的资产整理(Asset Curation)流程以最小化仿真到现实的差距(Sim-to-real Gap),并且难以准确模拟具有复杂形态和动力学的变形体。视频生成模型通过提供逼真、物理一致的世界时空模型,解决了上述局限性。这些能力推动了视频模型在机器人领域应用的日益增长。 在机器人领域,视频模型正越来越多地被用作具身世界模型(Embodied World Models)[25–28]。高保真的世界建模为机器人策略的高效评估建立了可信赖的基础 [16, 17, 29, 30]。传统的策略评估需要建立真实的机器人工作站进行在线策略推演(Online Policy Roll-outs),考虑到相关的硬件和人力成本,其代价极为高昂。视频模型在不牺牲评估结果可靠性的前提下规避了这一瓶颈。作为高保真世界模型,视频模型还能提供准确的动力学和奖励预测,这对于使用强化学习训练机器人策略至关重要 [31–34]。此外,视频模型实现了具有成本效益的机器人数据生成,这在模仿学习(Imitation Learning)中尤为重要。虽然数据规模扩展已被证明是提升 SOTA 机器人策略性能的关键要素 [23, 35],但收集专家演示数据极其昂贵,构成了一个显著的限制。视频模型在不依赖人类监督的情况下促进了可扩展的数据生成,解决了这一紧迫挑战。来自视频模型的专家演示还可以通过运动重定向(Motion Retargeting)直接应用于机器人 [36–38]。除了生成成功的任务演示外,视频模型还可以合成失败的视频轨迹,赋予机器人策略纠正行为,从而提高鲁棒性。此外,生成的数据还可以通过视觉规划进行优化,以计算出更优的机器人轨迹 [14, 15, 39–42]。 尽管视频模型提供了宝贵的能力,但其在机器人领域的集成仍面临显著的局限性。像大语言模型一样,视频模型倾向于产生幻觉(Hallucinate),即生成物理上不真实的视频,例如物体凭空出现/消失或以违反物理规律的方式变形 [43–46]。视频模型还难以遵循用户指令 [47, 48],特别是在长时视频生成任务中 [49–51]。此外,巨大的数据整理、训练和推理成本,以及视频生成中缺乏适当的内容安全保障,仍然是关键挑战 [52, 53],阻碍了其在机器人领域的更广泛采用。本综述提供了视频模型的广泛概览,明确了主流的模型架构、在机器人领域的关键应用以及主要挑战。我们重点介绍了视频模型作为机器人具身世界模型的四个主要应用,包括:(i) 模仿学习中的机器人数据生成和动作预测,(ii) 强化学习中的动力学和奖励建模,(iii) 策略评估,以及 (iv) 视觉规划,如图 1 (Figure 1) 所示。此外,我们概述了阻碍视频模型在机器人领域可信应用的重要开放性研究挑战,并提出了解决这些问题的重要未来研究方向。 与现有综述的比较。 先前的综述论文广泛涵盖了视频生成模型,特别是视频扩散模型,识别了主流模型架构 [54, 55]、可控视频生成技术 [56] 以及视频生成、编辑和理解的核心应用 [57]。其他综述 [58–61] 对世界模型进行了广泛讨论,对包括循环神经网络、Transformer、语言模型和场景重建模型(如高斯泼溅 Gaussian Splatting)在内的各种模型架构的研究进行了有价值的回顾。先前的工作还强调了视频模型提供的信息表示和任务制定的统一框架 [62],并主要通过历史视角讨论了视频模型能力的演变以及未来的潜在能力 [63]。尽管这些综述有助于广泛理解,但它们缺乏对生成式视频模型作为机器人世界模型的全面回顾 [58–61],也缺乏对生成式视频模型在机器人中的具体应用、相关挑战和未来方向的深入讨论 [54–57, 63]。相比之下,本综述提供了关于机器人领域视频生成模型的详尽讨论,特别是在机器人操作(Robot Manipulation)方面,这与自动驾驶等领域不同 [64–67],是现有综述未曾涉及的。 文章结构。 我们讨论了本综述的结构,如图 2 (Figure 2) 所示。在第 2 节中,我们概述了理解生成式视频建模至关重要的重要概念。我们首先讨论学习型世界模型,重点介绍这些模型从基于(潜在)状态的表征向基于高保真视频的表征的演变。接着,我们回顾基于扩散/流匹配的建模方法,强调其成功背后的核心原理。在第 3 节中,我们介绍了视频模型在机器人领域的主要应用,涵盖模仿学习中的机器人数据生成和动作预测、强化学习中的动力学和奖励建模、策略评估以及视觉规划。在第 4 节中,我们重点介绍用于评估视频模型的有用指标和基准。随后,我们在第 5 节中指出了开放性研究挑战,并提出了未来的研究方向。最后,我们在第 6 节总结全文。