
长期记忆已成为自主大语言模型(LLM)智能体的核心组件,赋予其持续适应、终身多模态学习以及高级推理的能力。然而,随着记忆系统从静态检索数据库向动态、智能体化(agentic)机制转型,关于记忆治理、语义漂移及隐私漏洞的关键问题也随之浮现。尽管近期的综述研究广泛关注记忆检索的效率,但在很大程度上忽视了高度动态环境下记忆损坏(memory corruption)的潜在风险。 为应对这些新兴挑战,我们提出了“稳定性与安全性受控记忆”(Stability and Safety-Governed Memory, SSGM)框架,这是一种概念性的治理架构。SSGM 通过在记忆巩固前强制执行一致性校验、时间衰减建模和动态访问控制,实现了记忆演进与执行过程的解耦。通过形式化分析与架构分解,我们展示了 SSGM 如何缓解因敏感上下文固化至长期存储而导致的拓扑诱导型知识泄露,并有效防止知识在迭代摘要过程中因语义漂移而产生的退化。最终,本研究提供了记忆损坏风险的详尽分类法,并为部署安全、持久且可靠的智能体记忆系统确立了稳健的治理范式。
1 引言
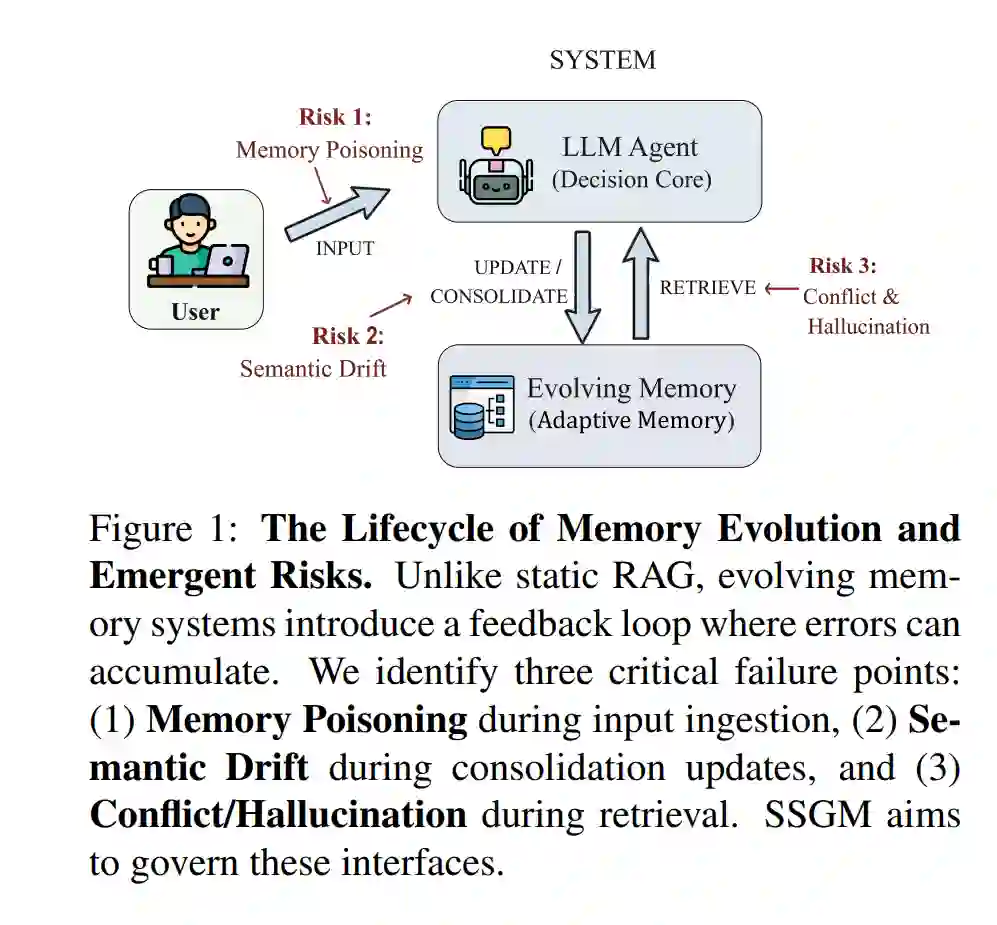
大语言模型(LLM)智能体在多个领域均展现出卓越的推理与交互能力 (Matarazzo and Torlone, 2025);然而,在缺乏专门机制的情况下,其本质上仍是无状态(stateless)的。标准 LLM 依赖于固定长度的上下文窗口,这限制了其进行无限信息留存的能力 (Zhong et al., 2024; Yousuf et al., 2025; OpenAI, 2023)。早期的解决方案多采用检索增强生成(RAG)来提供静态知识库 (Lewis et al., 2020; Gao et al., 2023),但现代自主智能体则渴求更具动态性的能力:即从经验中学习、更新其世界模型并随时间推移优化其策略的能力 (Xi et al., 2023; Wang et al., 2023)。 这一需求驱动了从静态存储向自适应、自优化记忆系统的范式转移。近期的架构不再将记忆操作视为被动的检索任务,而是将其视作主动的决策过程。例如,Memory-R1 利用强化学习训练专门的子智能体,根据任务反馈自主决定何时添加、更新或删除记忆单元 (Yan et al., 2026)。类似地,Mem0 和 AtomMem 等框架引入了动态巩固机制,通过原子操作持续优化存储结构 (Chhikara et al., 2025; Huo et al., 2026)。在这些系统中,记忆不再是不可变的日志,而是随智能体共同演进的可变资产 (Zhang et al., 2026b; Luo et al., 2026)。 然而,赋予智能体重写自身记忆的自主权,也将稳定性-塑性困境(stability-plasticity dilemma)引入了人工系统。若缺乏稳健的治理,记忆的持续优化将产生显著风险。智能体可能因反复摘要而逐渐扭曲事实(语义漂移)、强化次优工作流(过程漂移)(Han et al., 2025; Rath, 2026),或在无意中将幻觉及恶意注入内化为有效知识 (Wang et al., 2025; Greshake et al., 2023)。不同于静态 RAG 系统中错误仅局限于单次检索步骤,演进式记忆系统中的错误具有累积性和持久性。如图 1 所示,这在三个关键接口上形成了复合失效循环:输入摄取(投毒)、记忆巩固(漂移)以及记忆检索(幻觉)。图 1 展示了这一粗粒度的生命周期风险循环,随后在表 2 中将其精细化为四维失效分类法。正如近期综述所述 (Hu et al., 2025; Luo et al., 2026),虽然记忆更新机制已得到深入研究,但确保其长期正确性与安全性的协议仍有待开发。 为填补这一空白,本文提出了稳定性与安全性受控记忆(SSGM)框架。我们认为,若要使 LLM 智能体在关键任务环境中具备可靠性,必须将记忆演进与记忆治理进行解耦。本研究的主要贡献如下: 1. 演进分类法:我们从内容抽象、结构重组(例如,从列表转变为卡片盒式图结构 (Xu et al., 2025; Jiang et al., 2026))以及策略优化三个维度对记忆演进进行了分类。 1. 失效分析:我们识别并形式化了自适应记忆中的关键失效模式,特别是区分了内在漂移(如知识冲突)与外在威胁(如记忆投毒)。 1. SSGM 框架:我们综合了受控记忆架构的设计原则,通过集成一致性校验与基准事实锚定,以缓解失控演进带来的风险。 1. 基本权衡:我们对智能体记忆中固有的三大基本权衡进行了形式化讨论,即延迟-安全权衡、稳定性-塑性冲突以及图结构的可扩展性,为未来研究奠定了基础。

