

尽管视觉-语言-动作 (Vision–Language–Action, VLA) 模型取得了长足进步,但一个核心瓶颈仍未被深入探究:即支撑具身学习 (Embodied Learning) 的数据基础设施。在本综述中,我们提出,VLA 领域的未来演进将不仅取决于模型架构,更在于高保真数据引擎与结构化评估协议的协同设计。为此,我们围绕“数据集、基准测试与数据引擎”三大支柱,对 VLA 研究进行了系统性的、以数据为中心 (Data-centric) 的分析。
在数据集方面,我们从具身多样性、模态构成及动作空间形式化 (Action Space Formulation) 等维度对真实世界与合成语料库进行了分类,揭示了从根本上限制大规模数据采集的“保真度-成本”权衡难题。在基准测试方面,我们对任务复杂性与环境结构进行了耦合分析,揭示了现有评估协议在组合泛化 (Compositional Generalization) 与长程推理 (Long-horizon Reasoning) 评估中存在的结构性缺失。在数据引擎方面,我们探讨了基于仿真、视频重建及自动化任务生成的范式,并指出了它们在物理落地 (Physical Grounding) 与仿真-现实迁移 (Sim-to-real Transfer) 方面的共同局限性。
通过对上述分析的综合,我们提炼出四大开放性挑战:表示对齐、多模态监督、推理评估以及可扩展的数据生成。我们主张,应对这些挑战需将数据基础设施视作核心研究课题,而非次要的背景考量。为支持社区研究,我们发布了一个持续更新的资源仓库: https://github.com/ziyaow1010/vla-datasets-benchmarks。
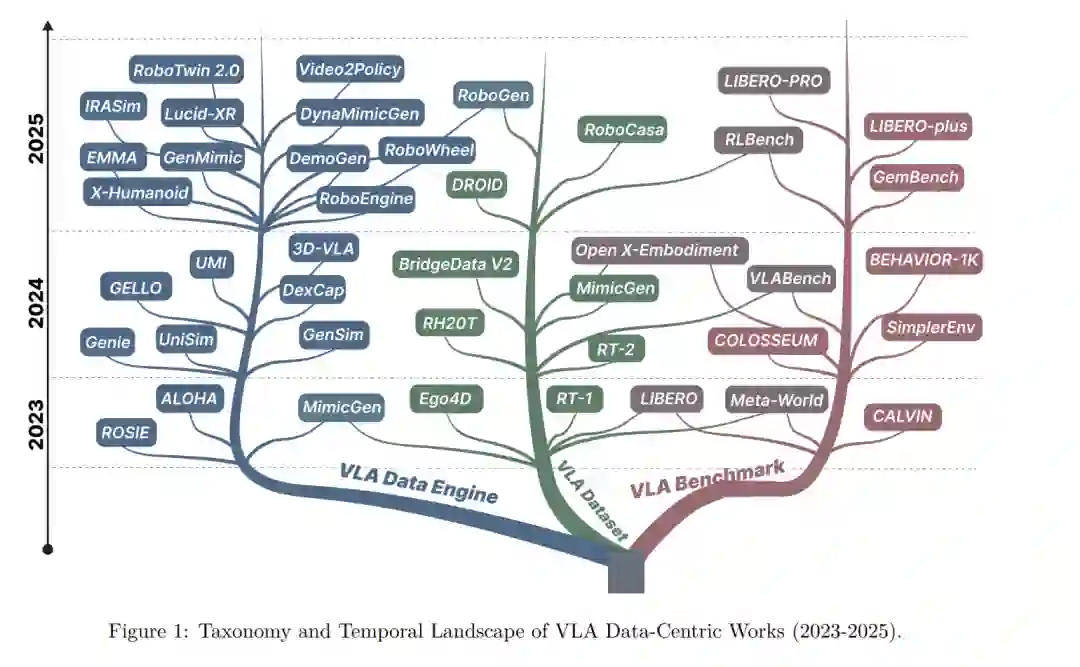
1 引言
构建能够跨越多样化任务和环境、并遵循自然语言指令的机器人,是具身智能 (Embodied AI) 的核心目标。视觉-语言-动作 (Vision–Language–Action, VLA) 模型通过学习将视觉观测和语言指令直接映射为动作,从而致力于实现这一目标 (Kim et al., 2024; Ma et al., 2024)。与专为受控环境下的固定任务设计的传统操纵系统不同,VLA 模型被寄予厚望,要求其具备跨物体、跨环境和跨任务变体的泛化能力 (Kawaharazuka et al., 2025)。这种灵活性对于在开放式或以人为中心的环境中运行的机器人至关重要,因为这类环境中的各种情况无法预先完全设定。 受益于多个领域的进展,VLA 引起了日益广泛的关注。首先,大规模视觉-语言模型 (VLM) 在视觉感知和指令遵循方面有了实质性提升 (Zhang et al., 2024a; Dai et al., 2023),为将语言锚定 (Grounding) 到视觉语境中提供了强大的骨干网络。其次,机器人演示数据集的增长以及模仿学习的进步,使得直接从人类演示中训练动作策略变得更具可行性 (Shao et al., 2025; Zhang et al., 2025a; Xiang et al., 2025)。此外,仿真工具、仿真-现实迁移 (Sim-to-real transfer) 方法以及边缘计算硬件的改进,进一步缩小了研究原型与实际部署之间的差距 (Todorov et al., 2012; Zhu et al., 2020; Sun et al., 2026)。这些进展共同促使 VLA 从一个很大程度上属于理论性的研究方向,转向能够与物理世界交互并能在广泛任务中泛化的系统。 尽管取得了这些进展,构建可靠的 VLA 系统依然困难重重,其核心挑战已日益演变为数据与评估问题,而非单纯的模型设计。在数据层面,VLA 数据集在模态覆盖、动作表示、机器人平台、任务定义和指令风格上存在巨大差异 (Padalkar et al., 2023; Liu et al., 2023)。真实世界的演示数据采集昂贵,且通常仅涵盖有限的任务和环境 (Khazatsky et al., 2024)。合成数据和仿真数据虽然可以大规模生产,但往往无法足够紧密地反映现实世界的情况,导致模型在场景、机器人或任务发生变化时失效 (Deng et al., 2025)。在评估层面,该领域缺乏标准化的协议:不同的工作采用不同的任务定义、成功准则和数据划分方式,这使得比较不同方法、或判断所报道的改进是否反映了真实的泛化能力变得十分困难。因此,迫切需要对 VLA 相关的数据集、基准测试以及用于大规模数据生产的数据引擎进行系统研究和分类,以更好地理解当前的局限性并支持该领域更可靠的发展。 在本综述中,我们通过提供结构化、以数据为中心的 VLA 研究分析来填补这一空白。我们将现有工作组织为三个主要类别:数据集、基准测试和数据引擎。“数据集”指用于训练 VLA 模型的高质量演示集合;“基准测试”定义了标准化的评估协议、任务设置和用于衡量性能与泛化能力的指标;“数据引擎”则是旨在收集、生成或增强 VLA 训练数据的可扩展系统或流水线。尽管这些类别在实践中可能存在重叠,但这种三位一体的组织方式使我们能够清晰地考察每个组成部分,并系统地比较设计选择。在每个类别中,我们进一步引入了更细粒度的分组:数据集被分为合成数据集和真实世界数据集;基准测试按任务设置(如桌面与非桌面)、轨迹长度 (Episode Horizon) 和任务复杂性进行组织;数据引擎则分为视频到数据流水线、硬件辅助数据采集系统和生成式数据引擎。对于每个分组,我们总结了代表性工作,分析了其设计选择,并讨论了其优缺点。我们还识别了开放性挑战,并概述了未来 VLA 数据和评估研究的有前景的方向。为了方便定位和比较相关工作,我们在图 1 中提供了一个树状分类体系,总结了 2023 年至 2025 年间代表性的 VLA 数据相关工作,并在统一框架下阐明了它们之间的关系。据我们所知,这是首篇从以数据为中心的视角系统分析 VLA 领域的综述。 我们的贡献总结如下: * 我们为 VLA 研究提出了一个统一的以数据为中心的分类法,将现有工作组织为数据集、基准测试和数据引擎,明确了它们在训练、评估和大规模数据生产中的不同角色。 * 我们引入了一个结构化分析框架来理解 VLA 数据资源,包括对基准测试的二维刻画,以及对数据集和数据引擎设计选择的系统比较。 * 我们识别了贯穿这三个组成部分的三大结构性挑战:跨具身的表示对齐、长程组合任务的可靠评估,以及保持物理真实性的可扩展数据生成。针对每一项挑战,我们都勾勒了未来的具体研究方向。
