

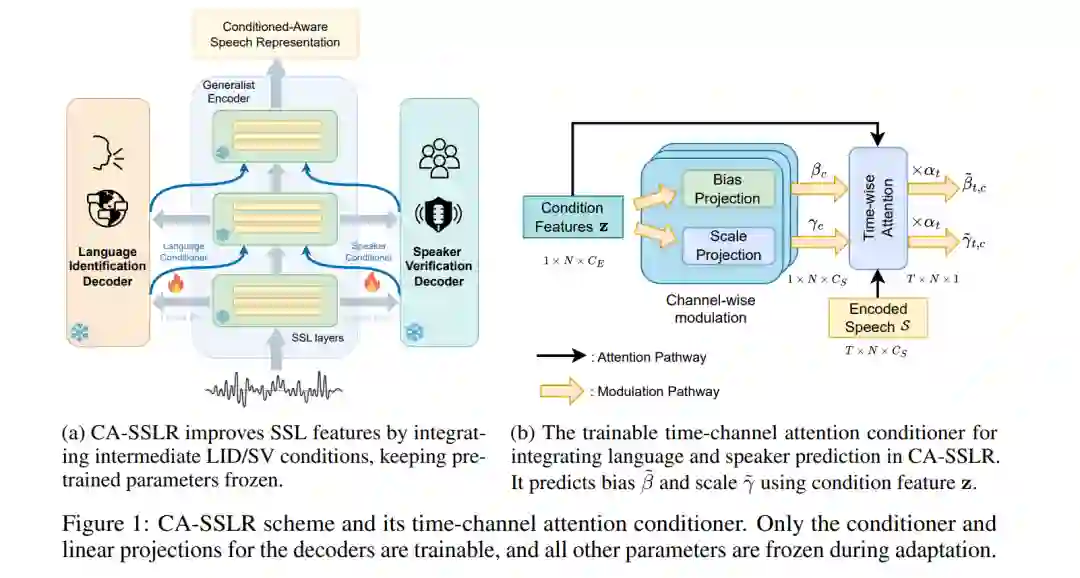
我们提出了条件感知自监督学习表征(CASSLR),这是一种通用的条件模型,广泛适用于各种语音处理任务。与传统的微调方法(通常针对下游模型进行优化)相比,CA-SSLR整合了来自前层的语言和说话人嵌入,使得自监督学习(SSL)模型能够感知当前的语言和说话人上下文。该方法减少了对输入音频特征的依赖,同时保持了基础自监督学习表征(SSLR)的完整性。CA-SSLR提升了模型的能力,并在最小化特定任务微调的情况下,展示了其在未知任务上的广泛适应性。我们的方法采用线性调制来动态调整内部表征,从而实现细粒度的适应性,同时不显著改变原始模型的行为。实验表明,CA-SSLR减少了可训练参数的数量,缓解了过拟合,并在资源稀缺和未知任务中表现出色。具体来说,CA-SSLR在LID(语言识别)错误上相对减少了10%,在ML-SUPERB基准上的ASR(自动语音识别)字符错误率(CER)提高了37%,在VoxCeleb-1上的SV(说话人验证)等错误率(EER)减少了27%,展示了其有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日
相关主题

最新内容
相关VIP内容
相关资讯
相关论文
Arxiv
43+阅读 · 2023年4月19日
Arxiv
232+阅读 · 2023年4月7日