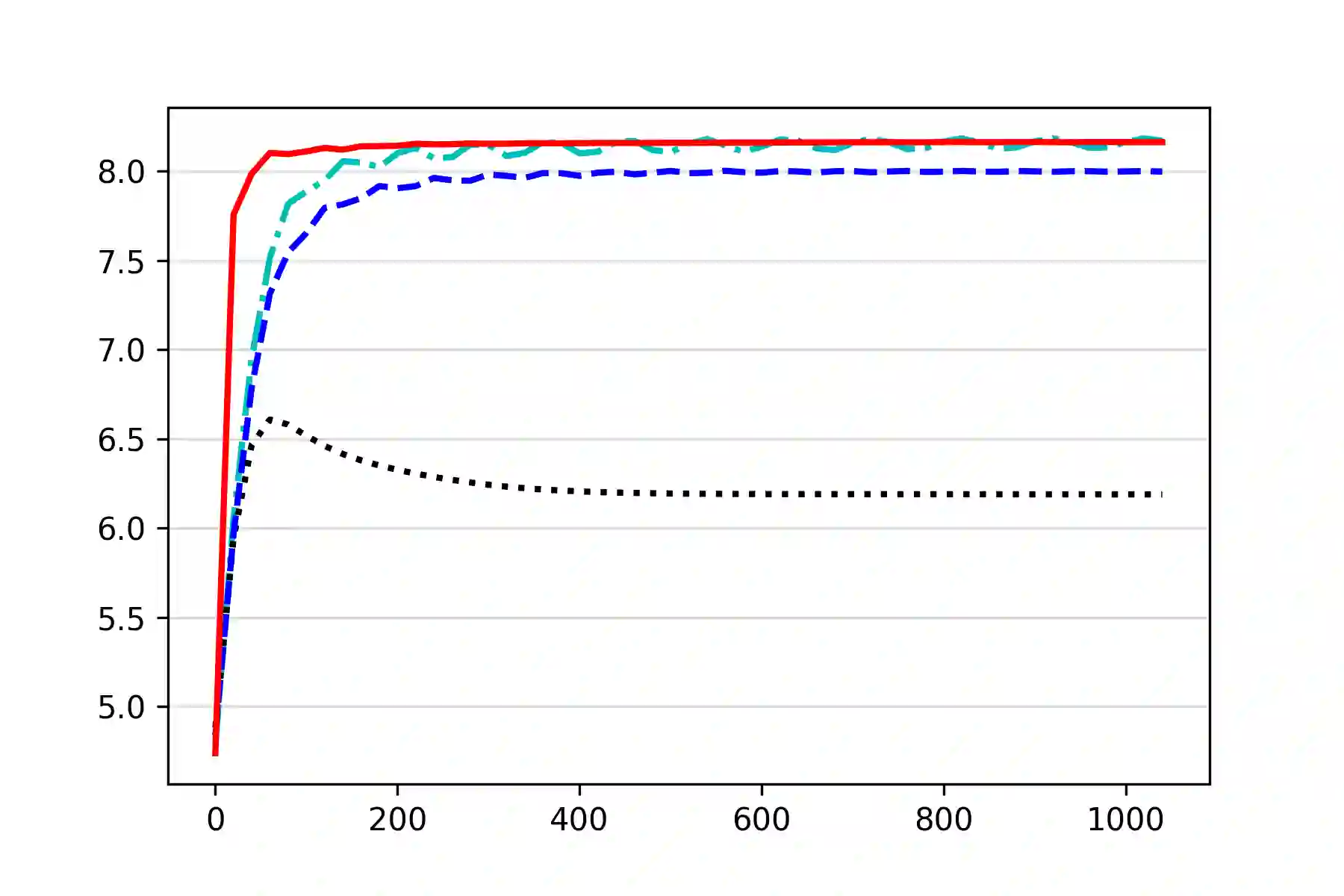
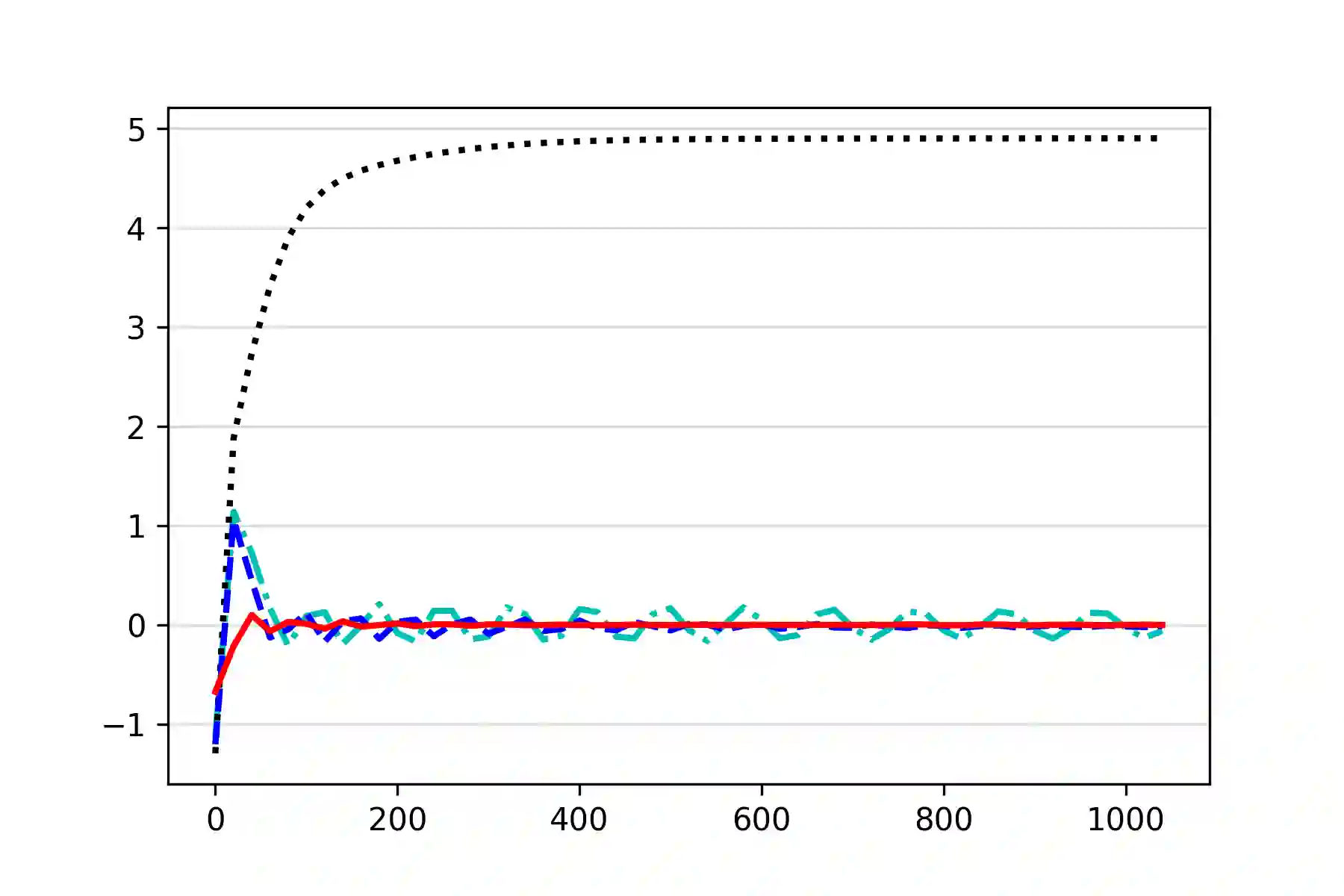
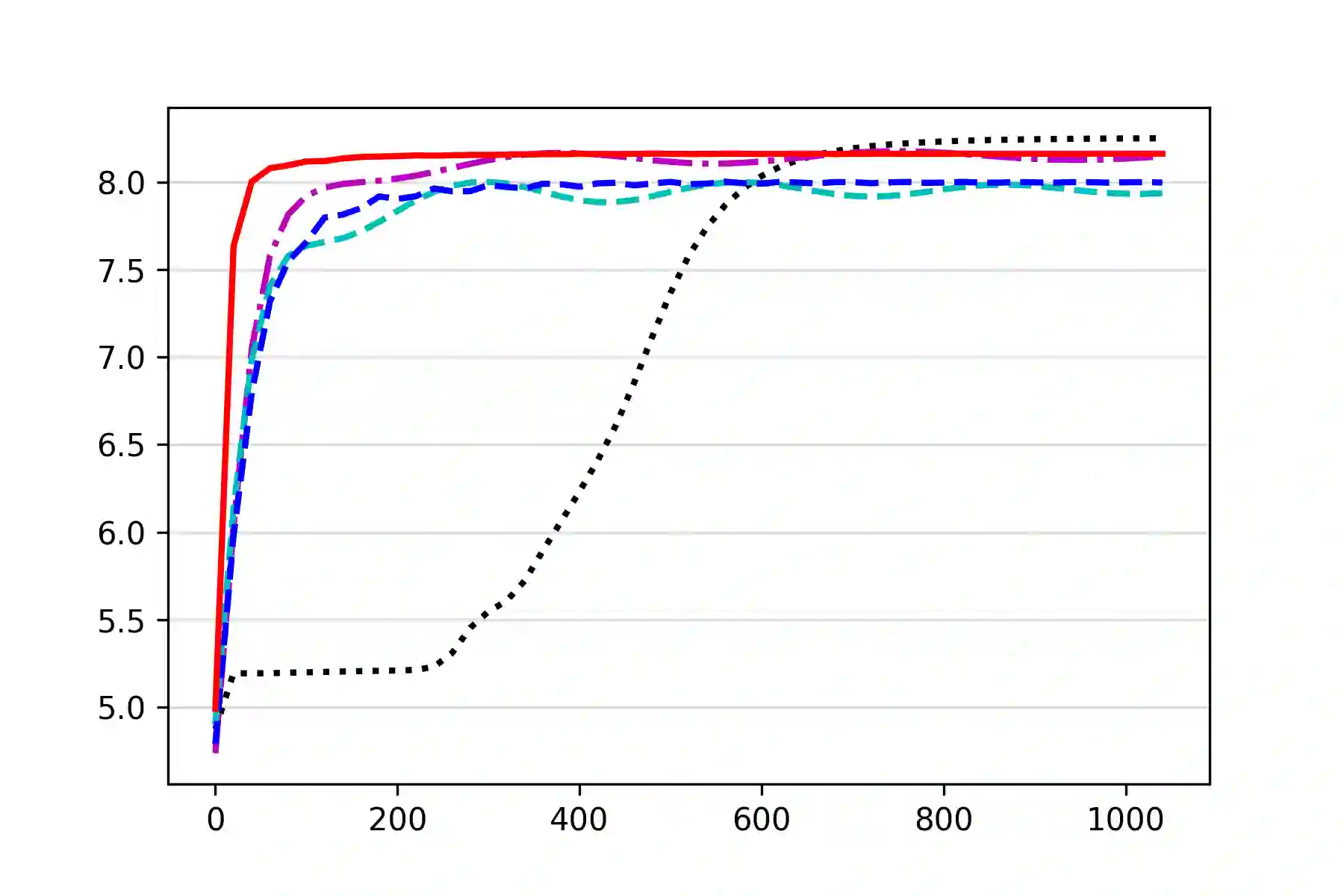
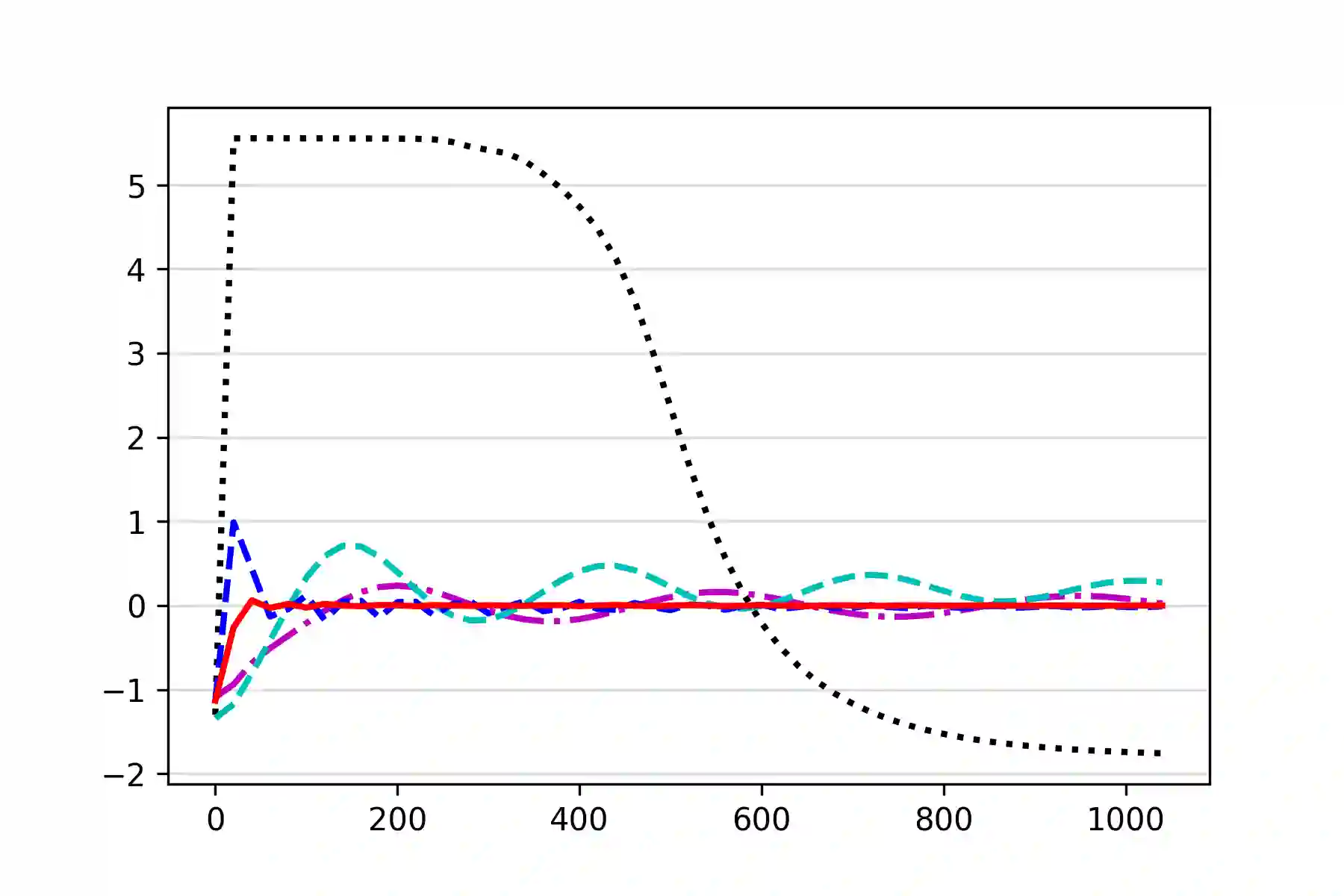
We study the problem of computing an optimal policy of an infinite-horizon discounted constrained Markov decision process (constrained MDP). Despite the popularity of Lagrangian-based policy search methods used in practice, the oscillation of policy iterates in these methods has not been fully understood, bringing out issues such as violation of constraints and sensitivity to hyper-parameters. To fill this gap, we employ the Lagrangian method to cast a constrained MDP into a constrained saddle-point problem in which max/min players correspond to primal/dual variables, respectively, and develop two single-time-scale policy-based primal-dual algorithms with non-asymptotic convergence of their policy iterates to an optimal constrained policy. Specifically, we first propose a regularized policy gradient primal-dual (RPG-PD) method that updates the policy using an entropy-regularized policy gradient, and the dual via a quadratic-regularized gradient ascent, simultaneously. We prove that the policy primal-dual iterates of RPG-PD converge to a regularized saddle point with a sublinear rate, while the policy iterates converge sublinearly to an optimal constrained policy. We further instantiate RPG-PD in large state or action spaces by including function approximation in policy parametrization, and establish similar sublinear last-iterate policy convergence. Second, we propose an optimistic policy gradient primal-dual (OPG-PD) method that employs the optimistic gradient method to update primal/dual variables, simultaneously. We prove that the policy primal-dual iterates of OPG-PD converge to a saddle point that contains an optimal constrained policy, with a linear rate. To the best of our knowledge, this work appears to be the first non-asymptotic policy last-iterate convergence result for single-time-scale algorithms in constrained MDPs.
翻译:我们研究无限时域折扣约束型马尔可夫决策过程(constrained MDP)最优策略的计算问题。尽管基于拉格朗日方法的策略搜索方法在实践中广泛应用,但其策略迭代的振荡现象尚未被充分理解,由此引发约束违反和超参数敏感等问题。为填补这一空白,我们采用拉格朗日方法将约束型MDP转化为约束鞍点问题(其中最大/最小玩家分别对应原始/对偶变量),并开发了两种单时间尺度基于策略的原始-对偶算法,其策略迭代可非渐进收敛至最优约束策略。具体而言:首先提出正则化策略梯度原始-对偶方法(RPG-PD),该方法同时使用熵正则化策略梯度更新策略,并通过二次正则化梯度上升更新对偶变量。我们证明RPG-PD的策略-对偶迭代以次线性速率收敛至正则化鞍点,同时策略迭代以次线性速率收敛至最优约束策略。进一步通过引入策略参数化的函数逼近方法,我们将RPG-PD推广至大规模状态或动作空间,并建立类似的末次迭代次线性收敛性。其次提出乐观策略梯度原始-对偶方法(OPG-PD),该方法采用乐观梯度法同时更新原始/对偶变量。我们证明OPG-PD的策略-对偶迭代以线性速率收敛至包含最优约束策略的鞍点。据我们所知,本文首次实现约束型MDP中单时间尺度算法的非渐进策略末次迭代收敛结果。