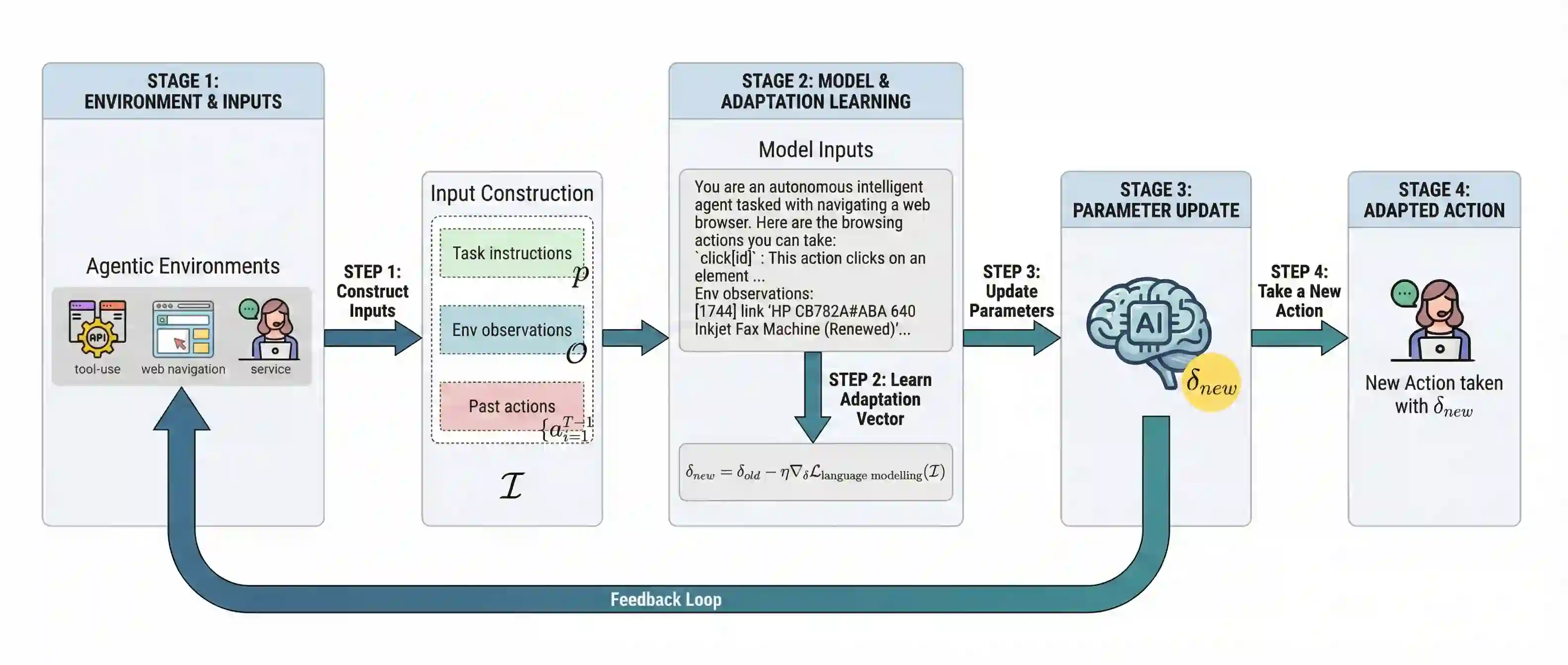
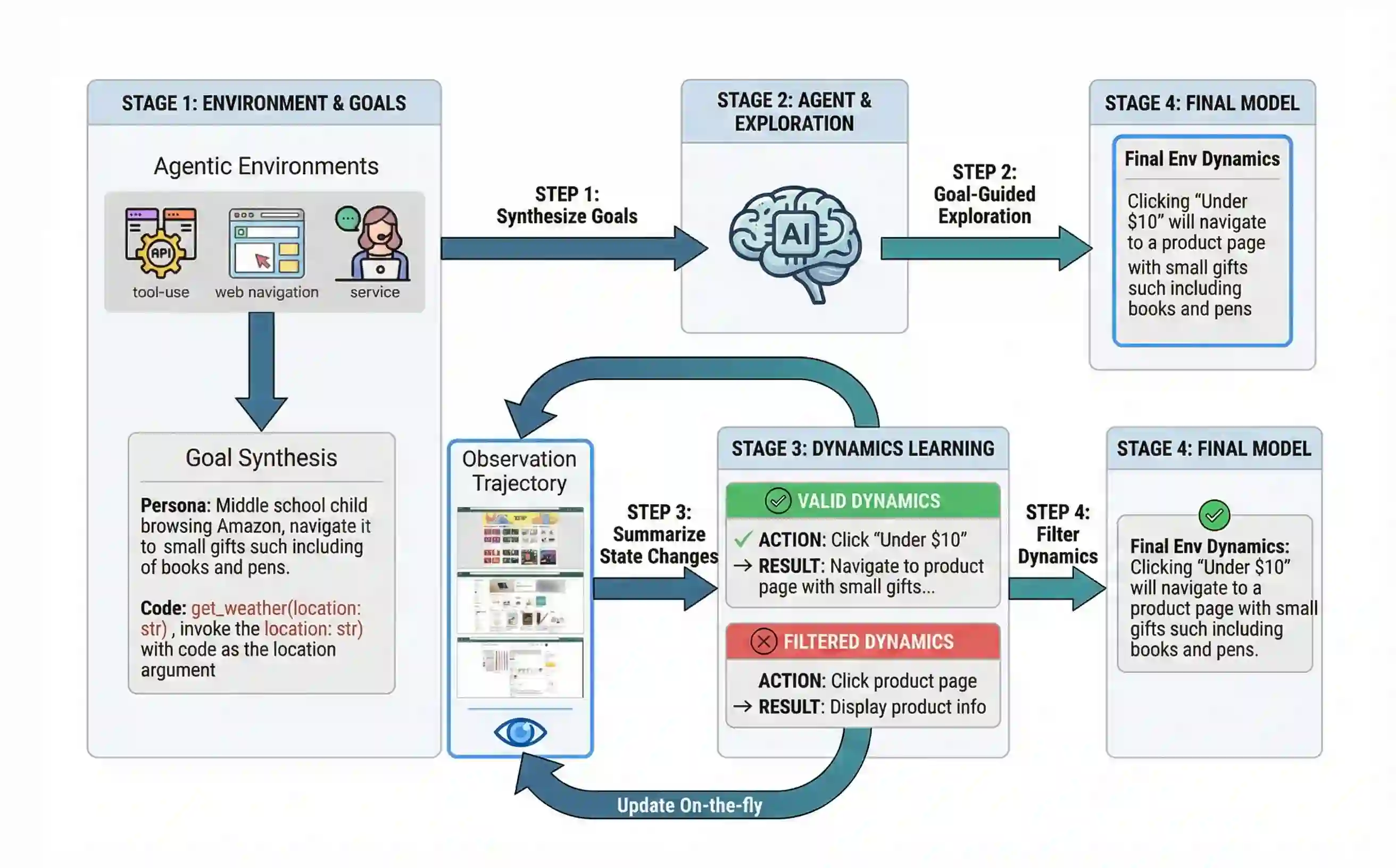
Large language model (LLM)-based agents struggle to generalize to novel and complex environments, such as unseen websites or new sets of functions, due to a fundamental mismatch between their pre-training and test-time conditions. This challenge stems from two distinct failure modes: a syntactic misunderstanding of environment-specific components like observation formats, and a semantic misunderstanding of state-transition dynamics, which are only revealed at test time. To address these issues, we propose two distinct and complementary strategies for adapting LLM agents by leveraging environment-specific information available during deployment. First, an online distributional adaptation method parameterizes environmental nuances by learning a lightweight adaptation vector that biases the model's output distribution, enabling rapid alignment with an environment response format. Second, a deployment-time dynamics grounding method employs a persona-driven exploration phase to systematically probe and learn the environment's causal dynamics before task execution, equipping the agent with a nonparametric world model. We evaluate these strategies across diverse agentic benchmarks, including function calling and web navigation. Our empirical results show the effectiveness of both strategies across all benchmarks with minimal computational cost. We find that dynamics grounding is particularly effective in complex environments where unpredictable dynamics pose a major obstacle, demonstrating a robust path toward more generalizable and capable LLM-based agents. For example, on the WebArena multi-site split, this method increases the agent's success rate from 2% to 23%.
翻译:基于大语言模型(LLM)的智能体难以泛化到新颖且复杂的环境(例如未见过的网站或新的功能集),这源于其预训练条件与测试条件之间的根本性不匹配。这一挑战源自两种不同的失效模式:一是对环境特定组件(如观察格式)的句法误解;二是对仅在测试时显现的状态转移动态的语义误解。为解决这些问题,我们提出了两种不同且互补的策略,利用部署时可获得的环境特定信息来适配LLM智能体。首先,一种在线分布适配方法通过学习一个轻量级的适配向量来参数化环境细微差别,该向量偏置模型的输出分布,从而使其能快速与环境响应格式对齐。其次,一种部署时动态基础方法在执行任务前,采用角色驱动的探索阶段来系统性地探测和学习环境的因果动态,为智能体配备一个非参数化的世界模型。我们在多种智能体基准测试(包括函数调用和网络导航)中评估了这些策略。实证结果表明,这两种策略在所有基准测试中均以极小的计算成本展现出有效性。我们发现,在动态不可预测构成主要障碍的复杂环境中,动态基础方法尤其有效,这为开发更具泛化能力和更强性能的LLM智能体指明了一条稳健的路径。例如,在WebArena多站点分割测试中,该方法将智能体的成功率从2%提升至23%。