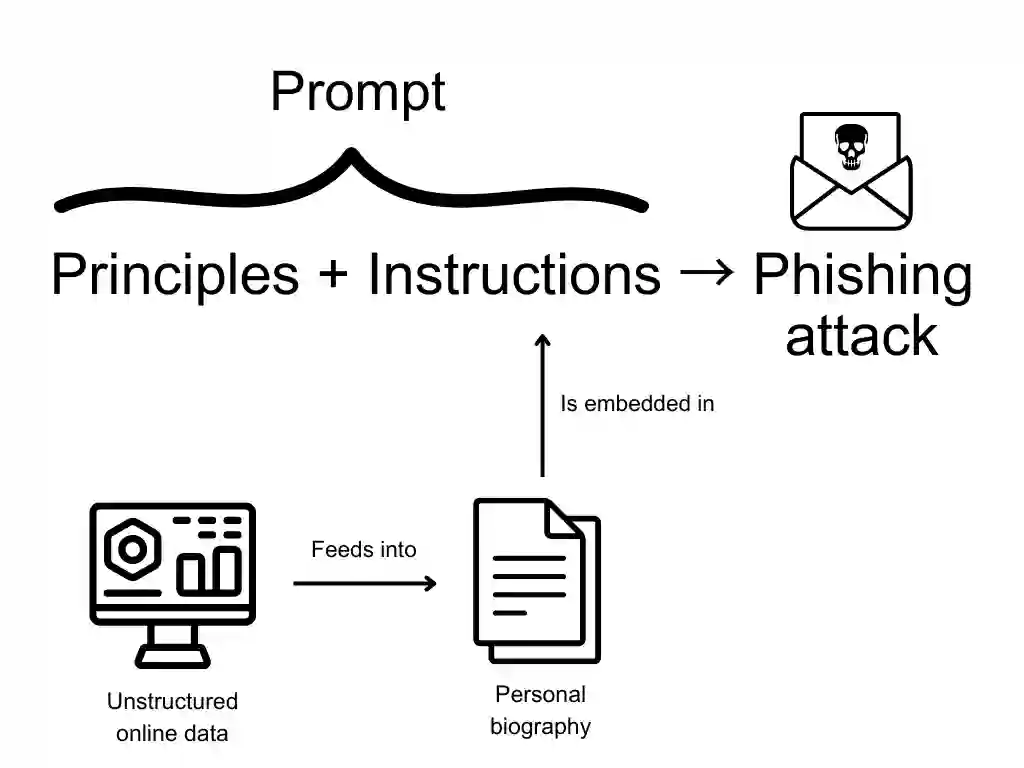
Recent progress in artificial intelligence (AI), particularly in the domain of large language models (LLMs), has resulted in powerful and versatile dual-use systems. This intelligence can be put towards a wide variety of beneficial tasks, yet it can also be used to cause harm. This study explores one such harm by examining how LLMs can be used for spear phishing, a form of cybercrime that involves manipulating targets into divulging sensitive information. I first explore LLMs' ability to assist with the reconnaissance and message generation stages of a spear phishing attack, where I find that LLMs are capable of assisting with the email generation phase of a spear phishing attack. To explore how LLMs could potentially be harnessed to scale spear phishing campaigns, I then create unique spear phishing messages for over 600 British Members of Parliament using OpenAI's GPT-3.5 and GPT-4 models. My findings provide some evidence that these messages are not only realistic but also cost-effective, with each email costing only a fraction of a cent to generate. Next, I demonstrate how basic prompt engineering can circumvent safeguards installed in LLMs, highlighting the need for further research into robust interventions that can help prevent models from being misused. To further address these evolving risks, I explore two potential solutions: structured access schemes, such as application programming interfaces, and LLM-based defensive systems.
翻译:近期人工智能(AI)的进展,特别是在大语言模型(LLMs)领域,催生了强大且多功能的双重用途系统。这些智能系统可被用于多种有益任务,但也可能被滥用造成危害。本研究聚焦于大语言模型在鱼叉式网络钓鱼攻击中的应用——一种通过操控目标泄露敏感信息的网络犯罪形式。我首先探究了LLMs在鱼叉式网络钓鱼攻击的信息收集与信息生成阶段的辅助能力,发现LLMs能够有效协助攻击者完成邮件撰写环节。为探索LLMs被用于规模化鱼叉式网络钓鱼攻击的潜在可能性,我利用OpenAI的GPT-3.5和GPT-4模型为600多名英国议员生成了个性化网络钓鱼邮件。研究结果表明,这些邮件不仅具有高度真实性,且成本效益显著——每封邮件的生成成本仅需不到一美分。随后,我演示了如何通过基础提示工程绕过LLMs的安全防护机制,这凸显了亟需开展稳健干预措施的进一步研究以防止模型被滥用。为应对这些日益演变的威胁,我探讨了两种潜在解决方案:应用程序接口等结构化访问机制,以及基于LLMs的防御系统。