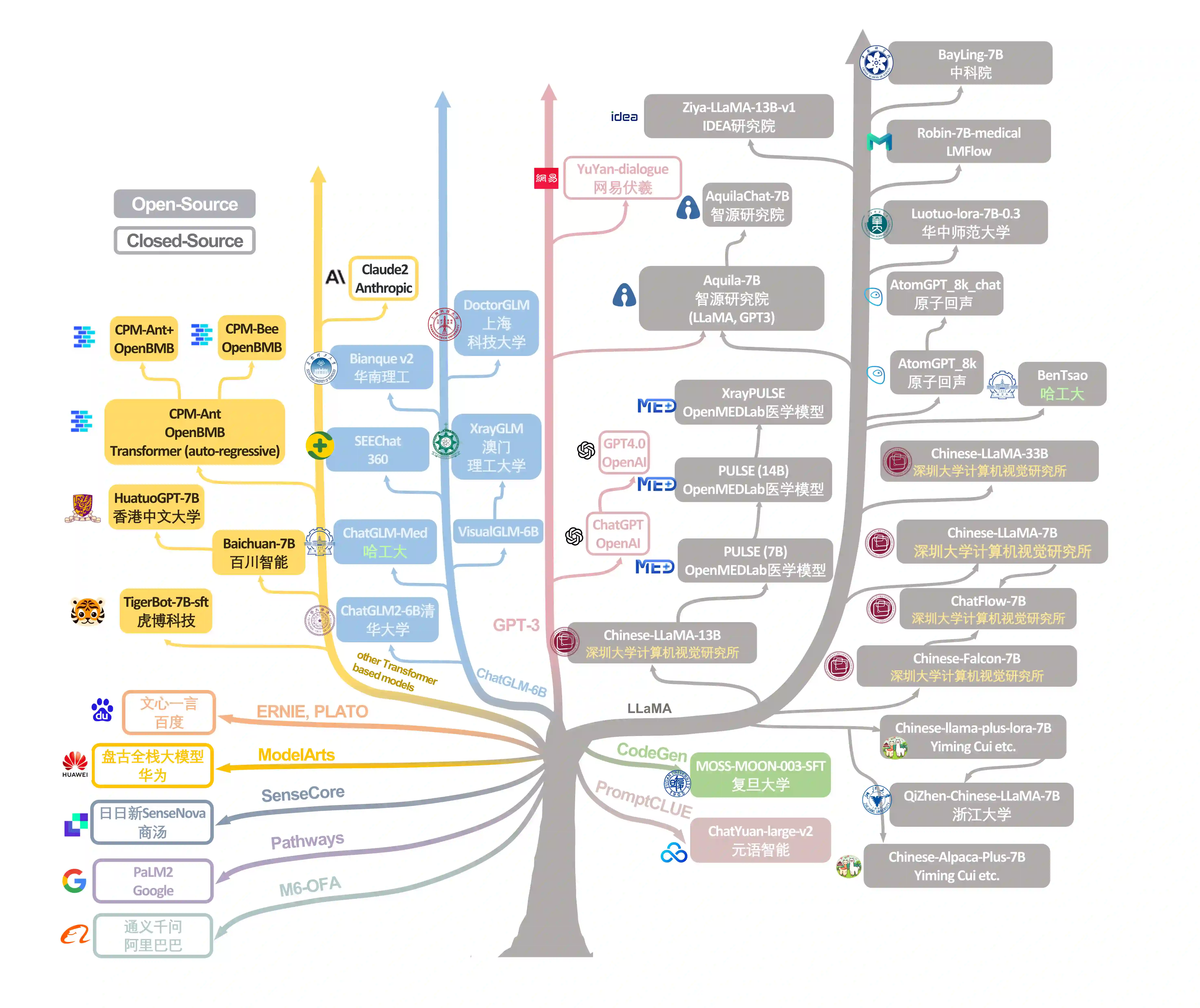
The rise of large language models (LLMs) has marked a pivotal shift in the field of natural language processing (NLP). LLMs have revolutionized a multitude of domains, and they have made a significant impact in the medical field. Large language models are now more abundant than ever, and many of these models exhibit bilingual capabilities, proficient in both English and Chinese. However, a comprehensive evaluation of these models remains to be conducted. This lack of assessment is especially apparent within the context of radiology NLP. This study seeks to bridge this gap by critically evaluating thirty two LLMs in interpreting radiology reports, a crucial component of radiology NLP. Specifically, the ability to derive impressions from radiologic findings is assessed. The outcomes of this evaluation provide key insights into the performance, strengths, and weaknesses of these LLMs, informing their practical applications within the medical domain.
翻译:大型语言模型(LLMs)的兴起标志着自然语言处理(NLP)领域的重大转变。LLMs已在多个领域引发变革,并在医学领域产生了深远影响。当前大型语言模型的种类比以往任何时候都更为丰富,其中许多模型具备双语能力,精通英语和中文。然而,对这类模型进行系统性评估的工作尚不充分,这种评估缺失在放射学NLP的背景下尤为明显。本研究旨在通过严格评估32种LLMs在解读放射学报告(放射学NLP的核心任务)中的表现来填补这一空白。具体而言,我们评估了模型从放射学发现中推导诊断印象的能力。评估结果揭示了这些LLMs的性能、优势与不足,为其在医学领域的实际应用提供了关键见解。