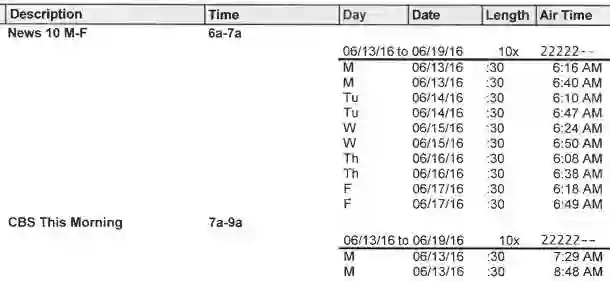
We introduce RealKIE, a benchmark of five challenging datasets aimed at advancing key information extraction methods, with an emphasis on enterprise applications. The datasets include a diverse range of documents including SEC S1 Filings, US Non-disclosure Agreements, UK Charity Reports, FCC Invoices, and Resource Contracts. Each presents unique challenges: poor text serialization, sparse annotations in long documents, and complex tabular layouts. These datasets provide a realistic testing ground for key information extraction tasks like investment analysis and contract analysis. In addition to presenting these datasets, we offer an in-depth description of the annotation process, document processing techniques, and baseline modeling approaches. This contribution facilitates the development of NLP models capable of handling practical challenges and supports further research into information extraction technologies applicable to industry-specific problems. The annotated data, OCR outputs, and code to reproduce baselines are available to download at https://indicodatasolutions.github.io/RealKIE/.
翻译:我们介绍了RealKIE,一个包含五个具有挑战性的数据集的基准,旨在推进关键信息抽取方法的发展,并侧重于企业应用。这些数据集涵盖了多样化的文档类型,包括美国证券交易委员会S1申报文件、美国保密协议、英国慈善报告、联邦通信委员会发票以及资源合同。每个数据集都呈现出独特的挑战:文本序列化质量差、长文档中标注稀疏以及复杂的表格布局。这些数据集为投资分析和合同分析等关键信息抽取任务提供了一个现实的测试平台。除了介绍这些数据集,我们还详细描述了标注流程、文档处理技术以及基线建模方法。这一贡献有助于开发能够应对实际挑战的自然语言处理模型,并支持针对适用于行业特定问题的信息抽取技术的进一步研究。标注数据、OCR输出以及复现基线的代码可通过 https://indicodatasolutions.github.io/RealKIE/ 下载。