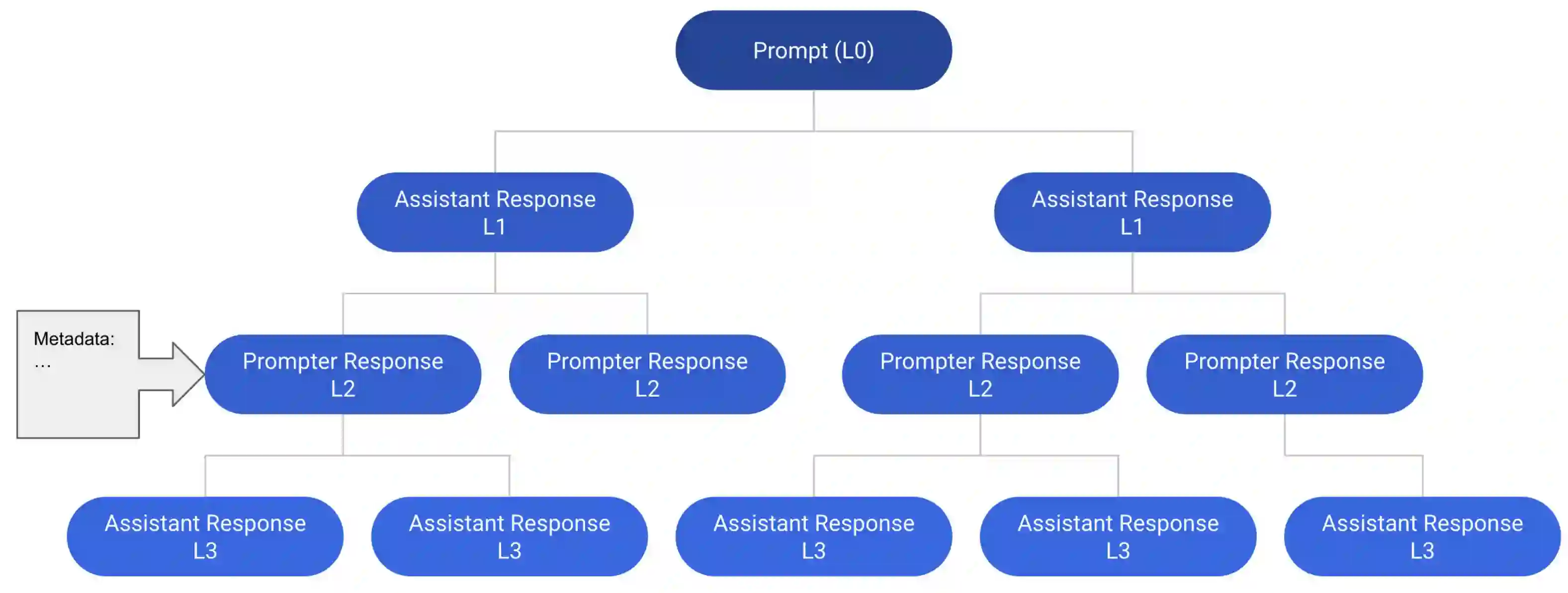
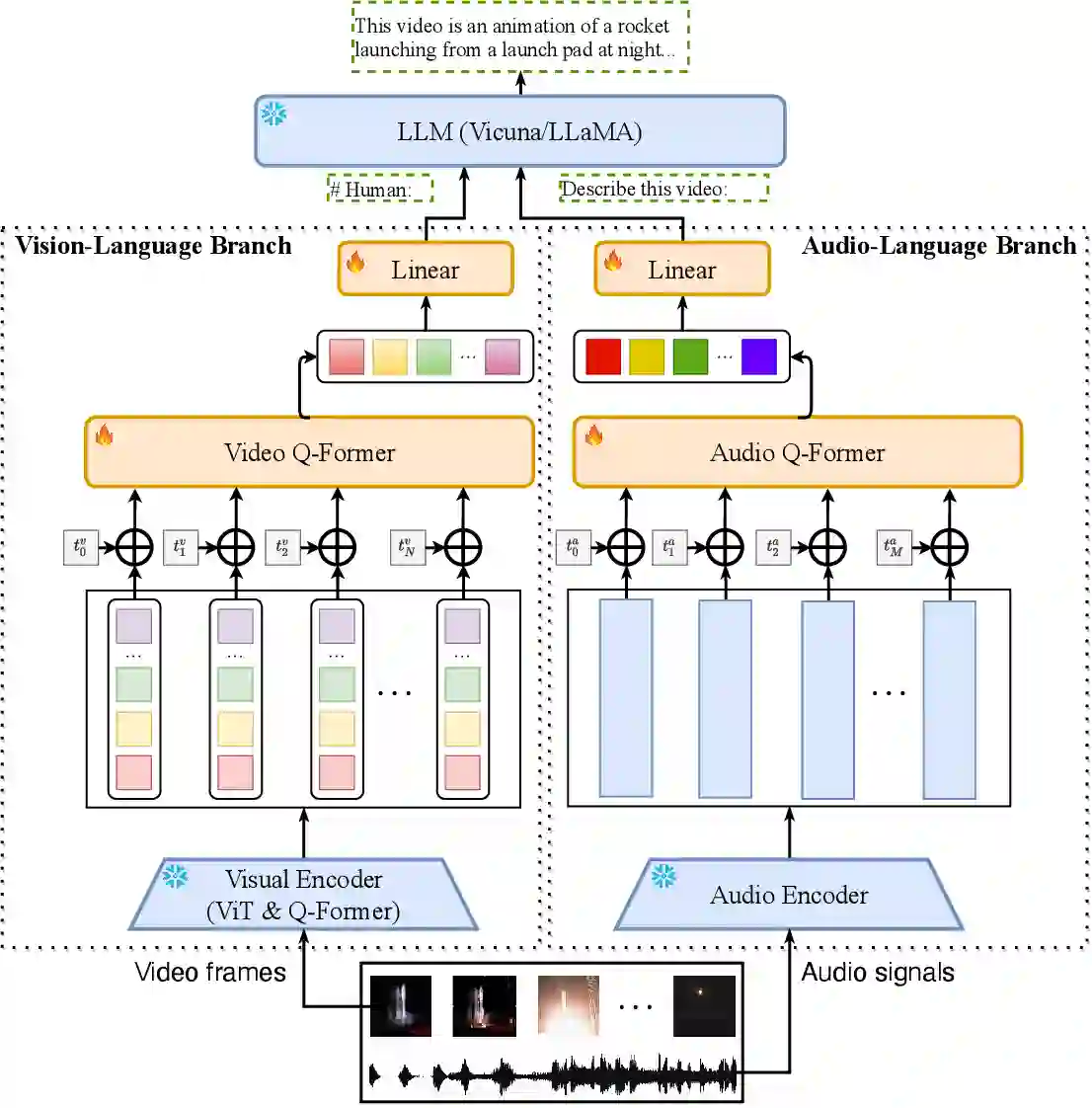
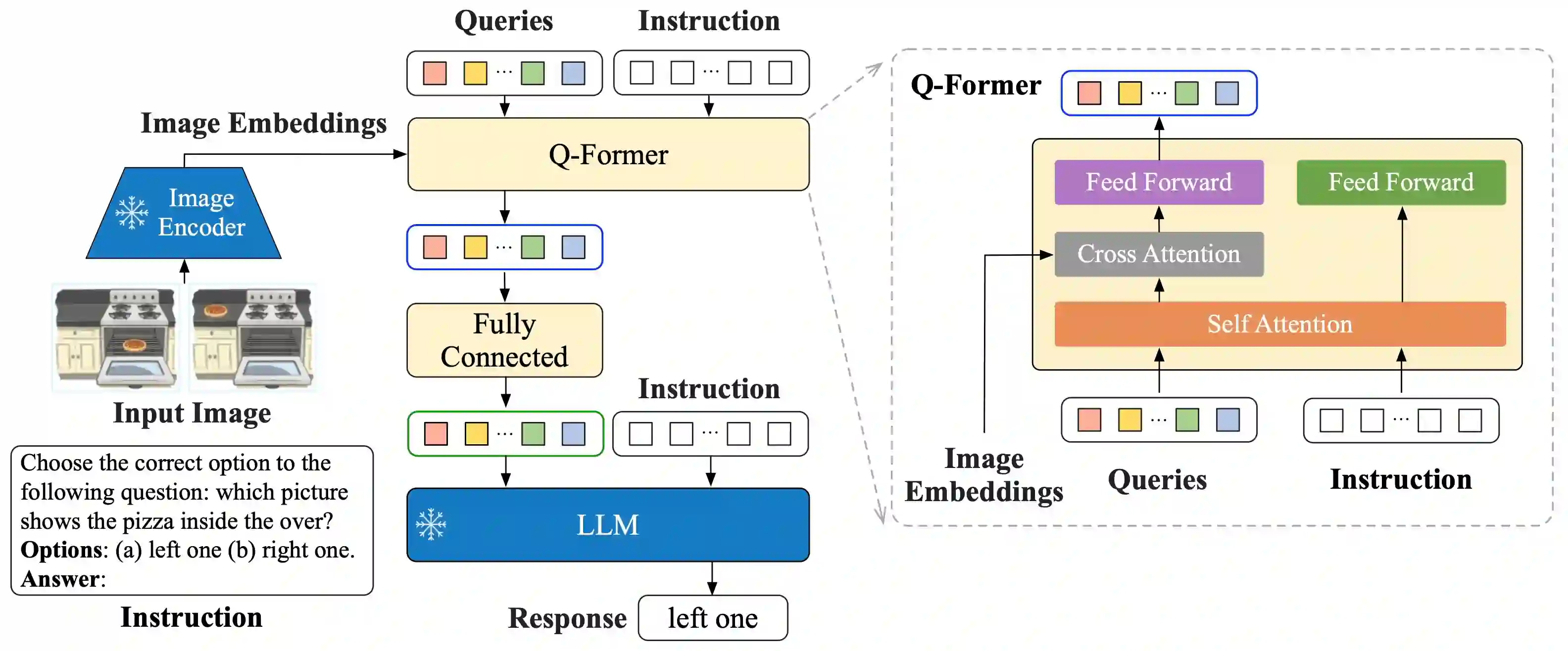
This paper surveys research works in the quickly advancing field of instruction tuning (IT), a crucial technique to enhance the capabilities and controllability of large language models (LLMs). Instruction tuning refers to the process of further training LLMs on a dataset consisting of \textsc{(instruction, output)} pairs in a supervised fashion, which bridges the gap between the next-word prediction objective of LLMs and the users' objective of having LLMs adhere to human instructions. In this work, we make a systematic review of the literature, including the general methodology of IT, the construction of IT datasets, the training of IT models, and applications to different modalities, domains and applications, along with an analysis on aspects that influence the outcome of IT (e.g., generation of instruction outputs, size of the instruction dataset, etc). We also review the potential pitfalls of IT along with criticism against it, along with efforts pointing out current deficiencies of existing strategies and suggest some avenues for fruitful research.
翻译:本文系统综述了快速发展的指令微调(Instruction Tuning, IT)领域的研究工作,该技术是提升大语言模型(Large Language Models, LLMs)能力与可控性的关键技术。指令微调是指通过监督学习方式,在包含 \textsc{(指令, 输出)} 对的数据集上进一步训练LLM的过程,从而弥合LLM的下一词预测目标与用户期望LLM遵循人类指令之间的差距。本文对相关文献进行了系统性梳理,涵盖指令微调的一般方法论、指令数据集的构建、指令模型的训练,以及在不同模态、领域和应用场景中的实践,同时分析了影响指令微调效果的因素(如指令输出生成、指令数据集规模等)。我们还探讨了指令微调的潜在缺陷及对其的批评意见,指出了现有策略存在的不足,并提出了未来富有前景的研究方向。