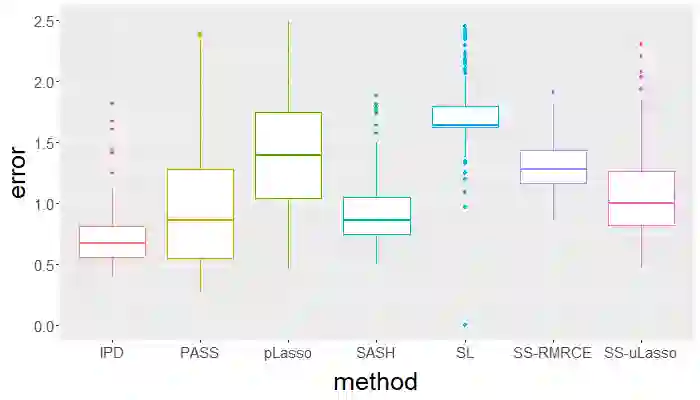
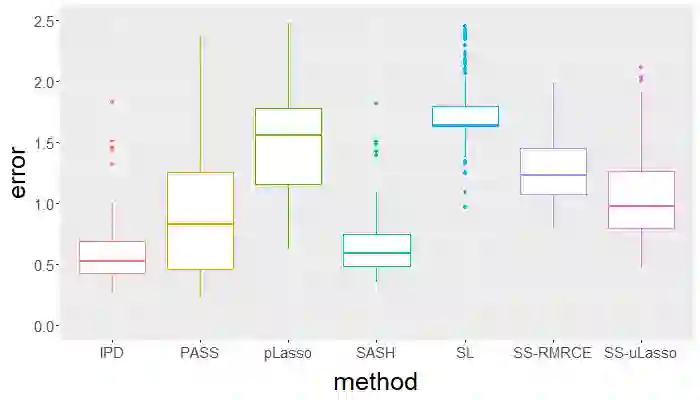
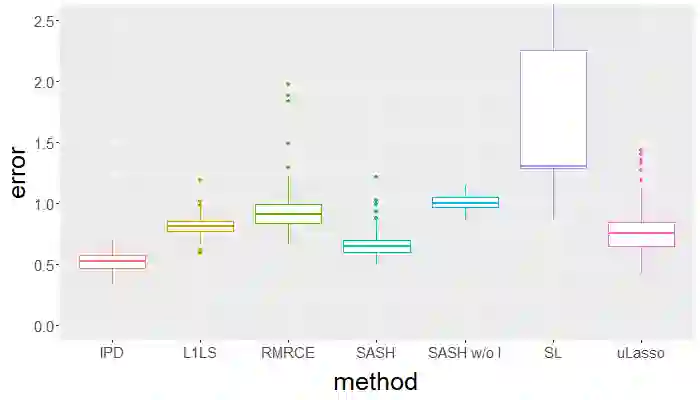
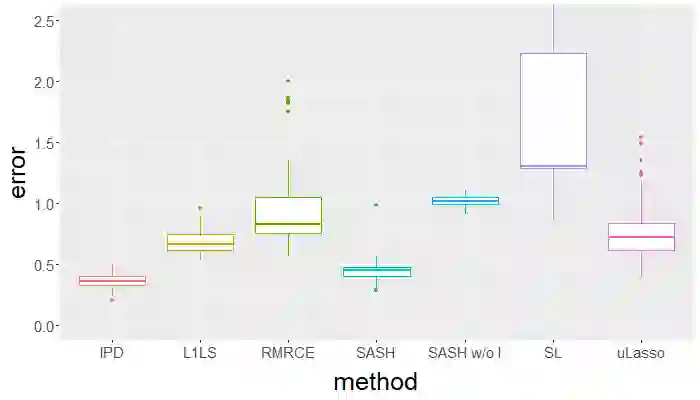
Surrogate variables in electronic health records (EHR) and biobank data play an important role in biomedical studies due to the scarcity or absence of chart-reviewed gold standard labels. We develop a novel approach named SASH for {\bf S}urrogate-{\bf A}ssisted and data-{\bf S}hielding {\bf H}igh-dimensional integrative regression. It is a semi-supervised approach that efficiently leverages sizable unlabeled samples with error-prone EHR surrogate outcomes from multiple local sites, to improve the learning accuracy of the small gold-labeled data. {To facilitate stable and efficient knowledge extraction from the surrogates, our method first obtains a preliminary supervised estimator, and then uses it to assist training a regularized single index model (SIM) for the surrogates. Interestingly, through a chain of convex and properly penalized sparse regressions that approximate the SIM loss with bias-correction, our method avoids the local minima issue of the SIM training, and fully eliminates the impact of the preliminary estimator's large error. In addition, it protects individual-level information through summary-statistics-based data aggregation across the local sites, leveraging a similar idea of bias-corrected approximation for SIM.} Through simulation studies, we demonstrate that our method outperforms existing approaches on finite samples. Finally, we apply our method to develop a high dimensional genetic risk model for type II diabetes using large-scale data sets from UK and Mass General Brigham biobanks, where only a small fraction of subjects in one site has been labeled via chart reviewing.
翻译:电子健康记录(EHR)和生物库数据中的替代变量,由于图表审查金标准标签的稀缺或缺失,在生物医学研究中发挥着重要作用。我们开发了一种名为SASH的新方法,用于替代变量辅助与数据屏蔽的高维集成回归。这是一种半监督方法,能够高效利用来自多个本地站点的大量带有误差的EHR替代变量未标记样本,以提升少量金标准标签数据的学习精度。为促进从替代变量中稳定且高效地提取知识,该方法首先获取初步监督估计量,随后利用其辅助训练一个正则化的单指标模型(SIM)以拟合替代变量。有趣的是,通过一系列凸性且适当惩罚的稀疏回归(这些回归以偏差校正方式近似SIM损失),该方法避免了SIM训练的局部最小值问题,并完全消除了初步估计量较大误差的影响。此外,它通过基于汇总统计的跨局部站点数据聚合来保护个体层面信息,借鉴了类似SIM的偏差校正近似思想。通过模拟研究,我们证明该方法在有限样本下优于现有方法。最后,我们将该方法应用于利用英国和马萨诸塞州总布里格姆生物库的大规模数据集构建II型糖尿病高维遗传风险模型,其中仅一个站点的少部分受试者通过图表审查进行了标签标注。