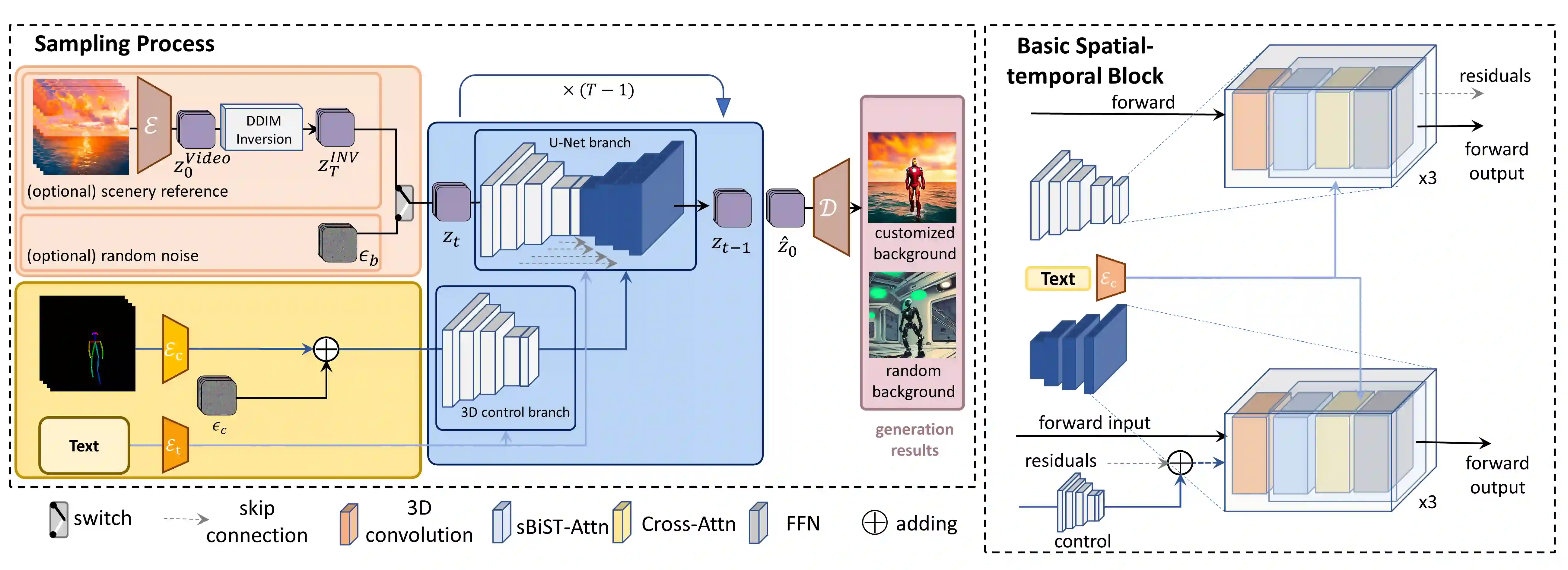
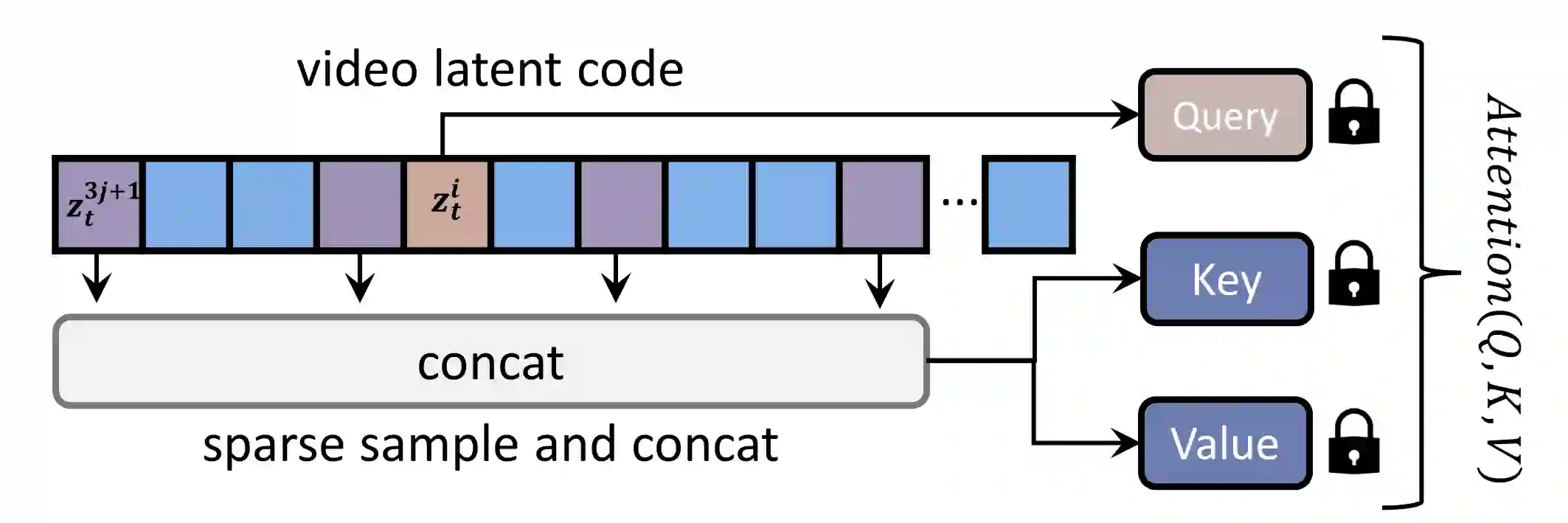
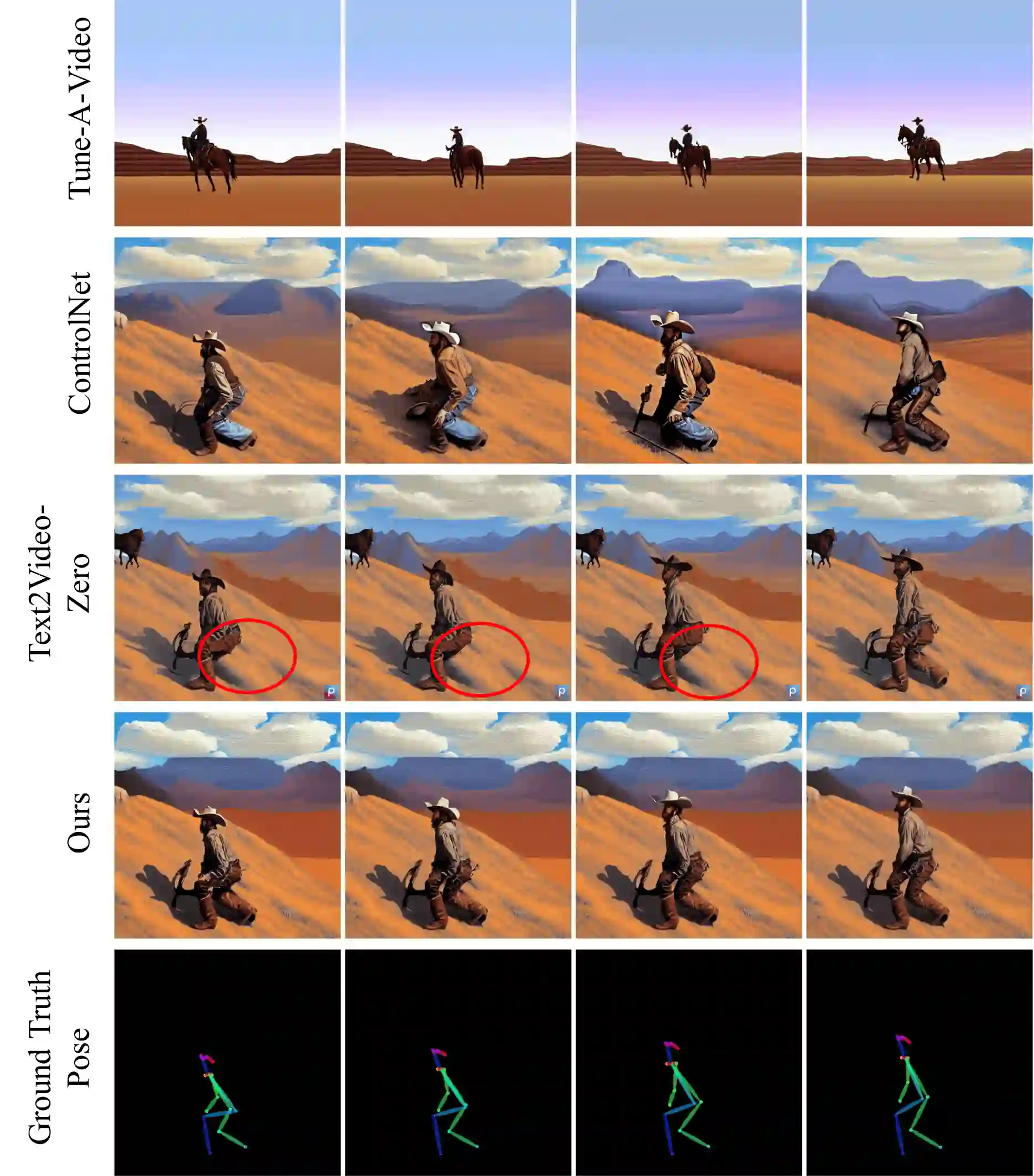
Recent works have successfully extended large-scale text-to-image models to the video domain, producing promising results but at a high computational cost and requiring a large amount of video data. In this work, we introduce ConditionVideo, a training-free approach to text-to-video generation based on the provided condition, video, and input text, by leveraging the power of off-the-shelf text-to-image generation methods (e.g., Stable Diffusion). ConditionVideo generates realistic dynamic videos from random noise or given scene videos. Our method explicitly disentangles the motion representation into condition-guided and scenery motion components. To this end, the ConditionVideo model is designed with a UNet branch and a control branch. To improve temporal coherence, we introduce sparse bi-directional spatial-temporal attention (sBiST-Attn). The 3D control network extends the conventional 2D controlnet model, aiming to strengthen conditional generation accuracy by additionally leveraging the bi-directional frames in the temporal domain. Our method exhibits superior performance in terms of frame consistency, clip score, and conditional accuracy, outperforming other compared methods.
翻译:近期研究成功地将大规模文本到图像模型扩展到视频领域,取得了令人瞩目的成果,但计算成本高昂且需要大量视频数据。本文提出ConditionVideo——一种基于给定条件、视频和输入文本的无训练文本到视频生成方法,通过利用现成文本到图像生成模型(如Stable Diffusion)的能力,从随机噪声或给定场景视频生成逼真的动态视频。该方法将运动表示显式解耦为条件引导分量和场景运动分量。为此,ConditionVideo模型设计了UNet分支和控制分支。为提升时序连贯性,我们引入了稀疏双向时空注意力机制(sBiST-Attn)。3D控制网络扩展了传统2D控制网络模型,通过额外利用时域中的双向帧来增强条件生成精度。该方法在帧一致性、视频片段得分和条件准确度方面均优于其他对比方法,展现出卓越性能。