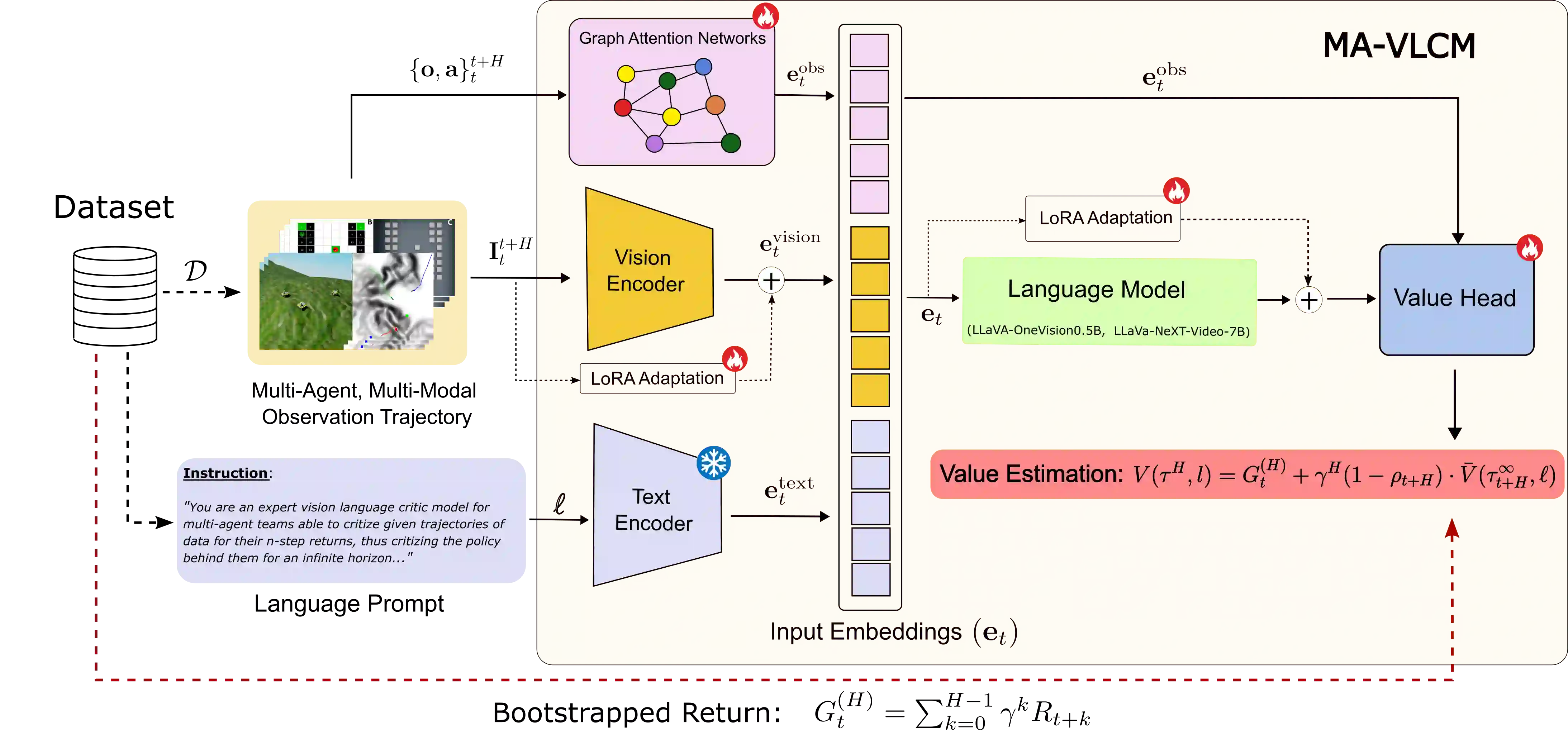
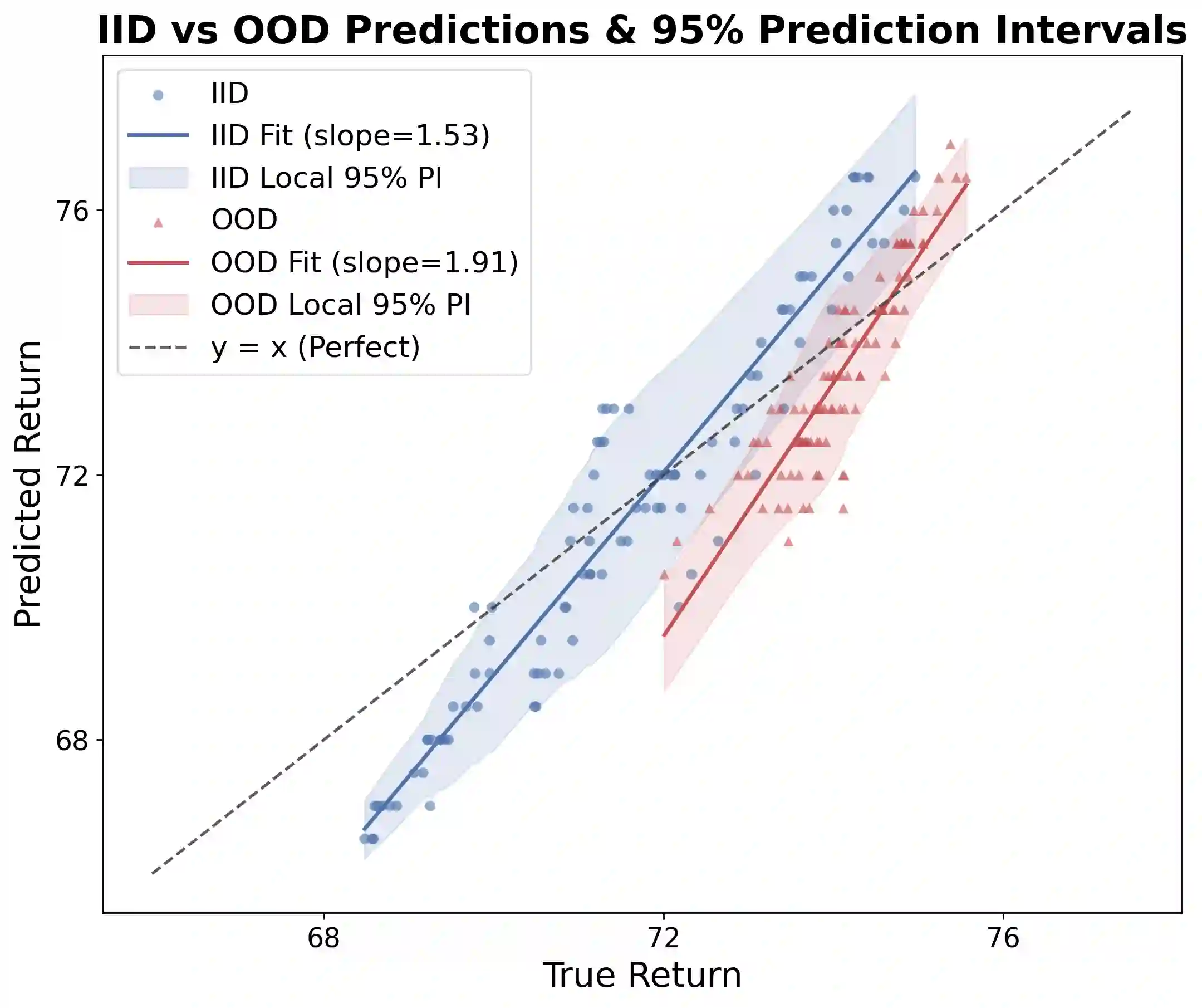
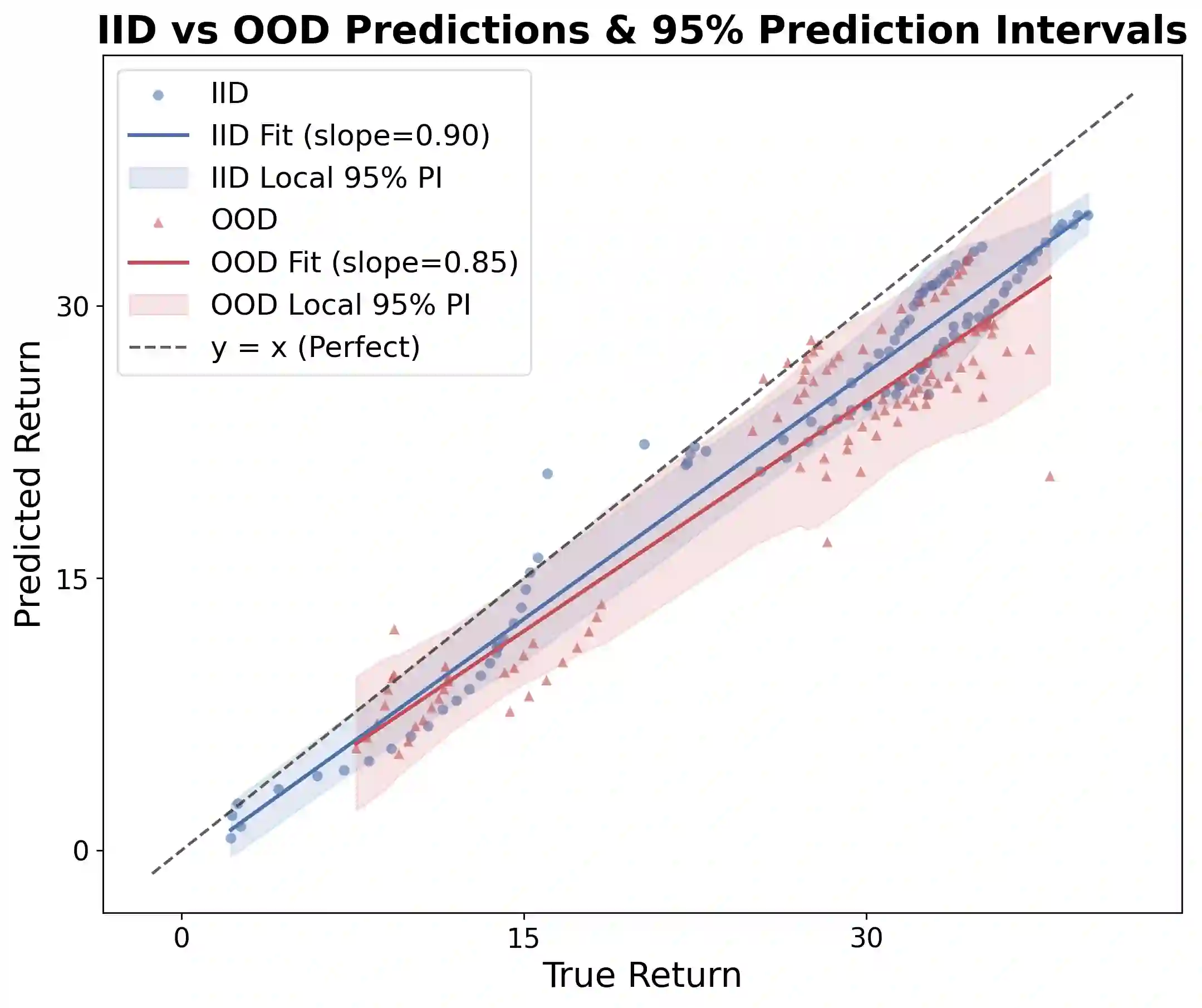
Multi-agent reinforcement learning (MARL) commonly relies on a centralized critic to estimate the value function. However, learning such a critic from scratch is highly sample-inefficient and often lacks generalization across environments. At the same time, large vision-language-action models (VLAs) trained on internet-scale data exhibit strong multimodal reasoning and zero-shot generalization capabilities, yet directly deploying them for robotic execution remains computationally prohibitive, particularly in heterogeneous multi-robot systems with diverse embodiments and resource constraints. To address these challenges, we propose Multi-Agent Vision-Language-Critic Models (MA-VLCM), a framework that replaces the learned centralized critic in MARL with a pretrained vision-language model fine-tuned to evaluate multi-agent behavior. MA-VLCM acts as a centralized critic conditioned on natural language task descriptions, visual trajectory observations, and structured multi-agent state information. By eliminating critic learning during policy optimization, our approach significantly improves sample efficiency while producing compact execution policies suitable for deployment on resource-constrained robots. Results show good zero-shot return estimation on models with differing VLM backbones on in-distribution and out-of-distribution scenarios in multi-agent team settings
翻译:多智能体强化学习(MARL)通常依赖一个中心化的评判器来估计价值函数。然而,从零开始学习这样的评判器样本效率极低,并且往往缺乏跨环境的泛化能力。与此同时,在互联网规模数据上训练的大型视觉-语言-动作模型(VLA)展现出强大的多模态推理和零样本泛化能力,但直接将其部署于机器人执行在计算上仍然代价高昂,尤其是在具有异构形态和资源约束的异质多机器人系统中。为应对这些挑战,我们提出了多智能体视觉语言评判模型(MA-VLCM),该框架用经过微调以评估多智能体行为的预训练视觉语言模型,取代了MARL中需要学习的中心化评判器。MA-VLCM作为一个中心化评判器,其条件输入包括自然语言任务描述、视觉轨迹观测以及结构化的多智能体状态信息。通过在策略优化过程中消除评判器的学习环节,我们的方法显著提高了样本效率,同时生成适用于资源受限机器人部署的紧凑执行策略。实验结果表明,在多智能体团队场景的分布内和分布外任务上,采用不同VLM骨干的模型均能实现良好的零样本回报估计。