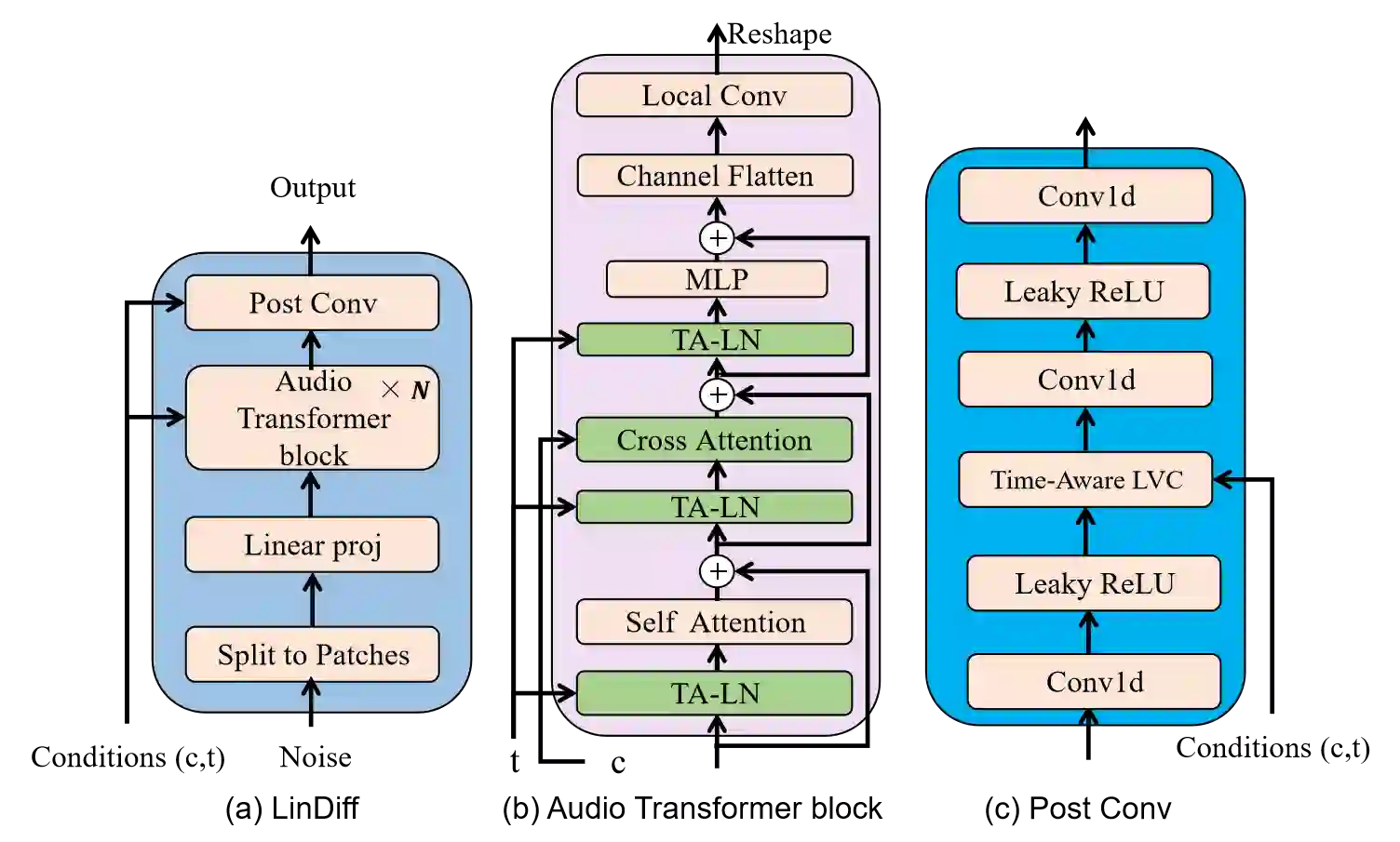
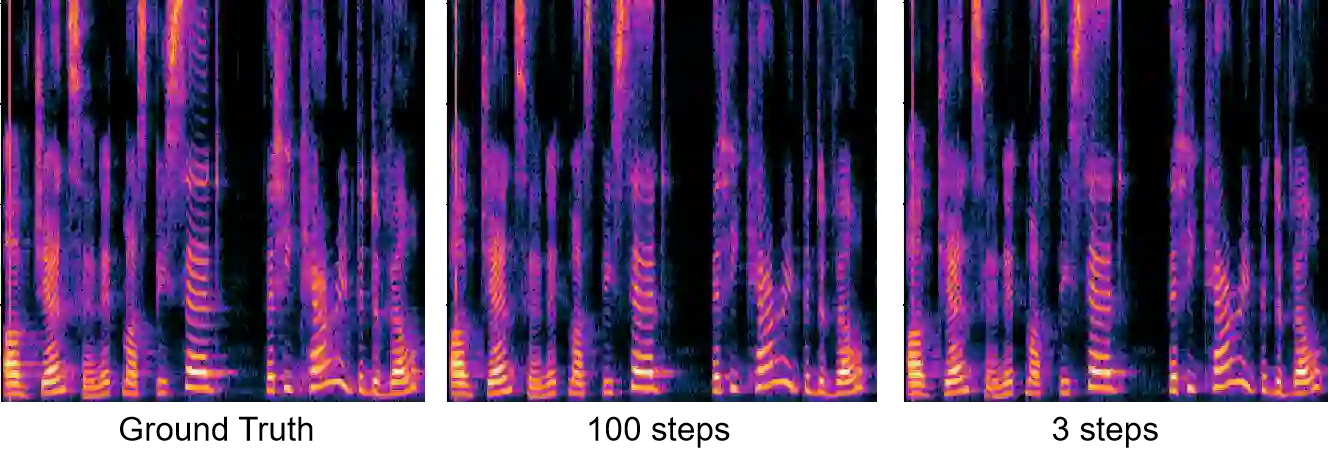
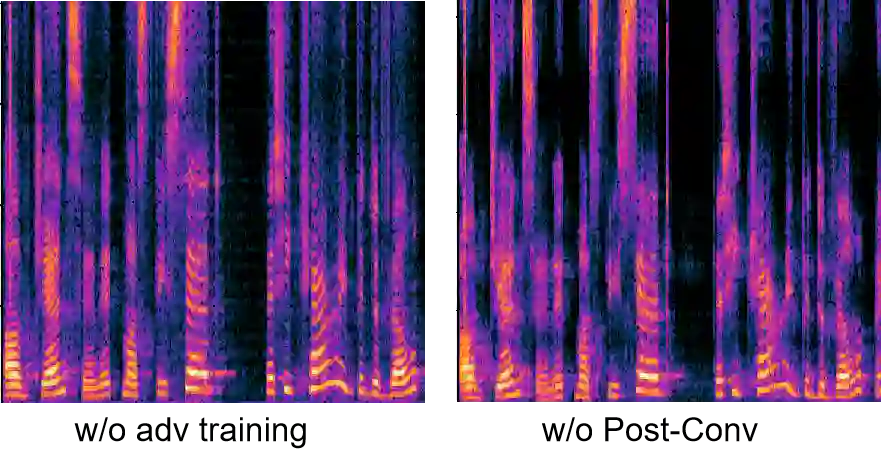
Denoising Diffusion Probabilistic Models have shown extraordinary ability on various generative tasks. However, their slow inference speed renders them impractical in speech synthesis. This paper proposes a linear diffusion model (LinDiff) based on an ordinary differential equation to simultaneously reach fast inference and high sample quality. Firstly, we employ linear interpolation between the target and noise to design a diffusion sequence for training, while previously the diffusion path that links the noise and target is a curved segment. When decreasing the number of sampling steps (i.e., the number of line segments used to fit the path), the ease of fitting straight lines compared to curves allows us to generate higher quality samples from a random noise with fewer iterations. Secondly, to reduce computational complexity and achieve effective global modeling of noisy speech, LinDiff employs a patch-based processing approach that partitions the input signal into small patches. The patch-wise token leverages Transformer architecture for effective modeling of global information. Adversarial training is used to further improve the sample quality with decreased sampling steps. We test proposed method with speech synthesis conditioned on acoustic feature (Mel-spectrograms). Experimental results verify that our model can synthesize high-quality speech even with only one diffusion step. Both subjective and objective evaluations demonstrate that our model can synthesize speech of a quality comparable to that of autoregressive models with faster synthesis speed (3 diffusion steps).
翻译:去噪扩散概率模型在各种生成任务中展现出非凡的能力,但其缓慢的推理速度限制了其在语音合成中的实际应用。本文提出一种基于常微分方程的线性扩散模型(LinDiff),以实现快速推理与高样本质量的兼顾。首先,我们在目标与噪声之间采用线性插值来设计训练用的扩散序列,而此前连接噪声与目标的扩散路径为曲线段。当减少采样步数(即用于拟合路径的线段数量)时,直线相较于曲线更易拟合的特性使得我们能够以更少的迭代次数从随机噪声生成更高质量的样本。其次,为降低计算复杂度并实现对含噪语音的有效全局建模,LinDiff采用基于分块的处理方法,将输入信号划分为小块。基于分块标记的方法利用Transformer架构实现全局信息的有效建模。对抗训练被用于在减少采样步数的情况下进一步提升样本质量。我们以声学特征(梅尔频谱图)为条件对语音合成方法进行测试。实验结果表明,即使仅使用一个扩散步,我们的模型也能合成高质量语音。主观与客观评测均证实,我们的模型能够以更快的合成速度(3个扩散步)合成与自回归模型质量相当的语音。