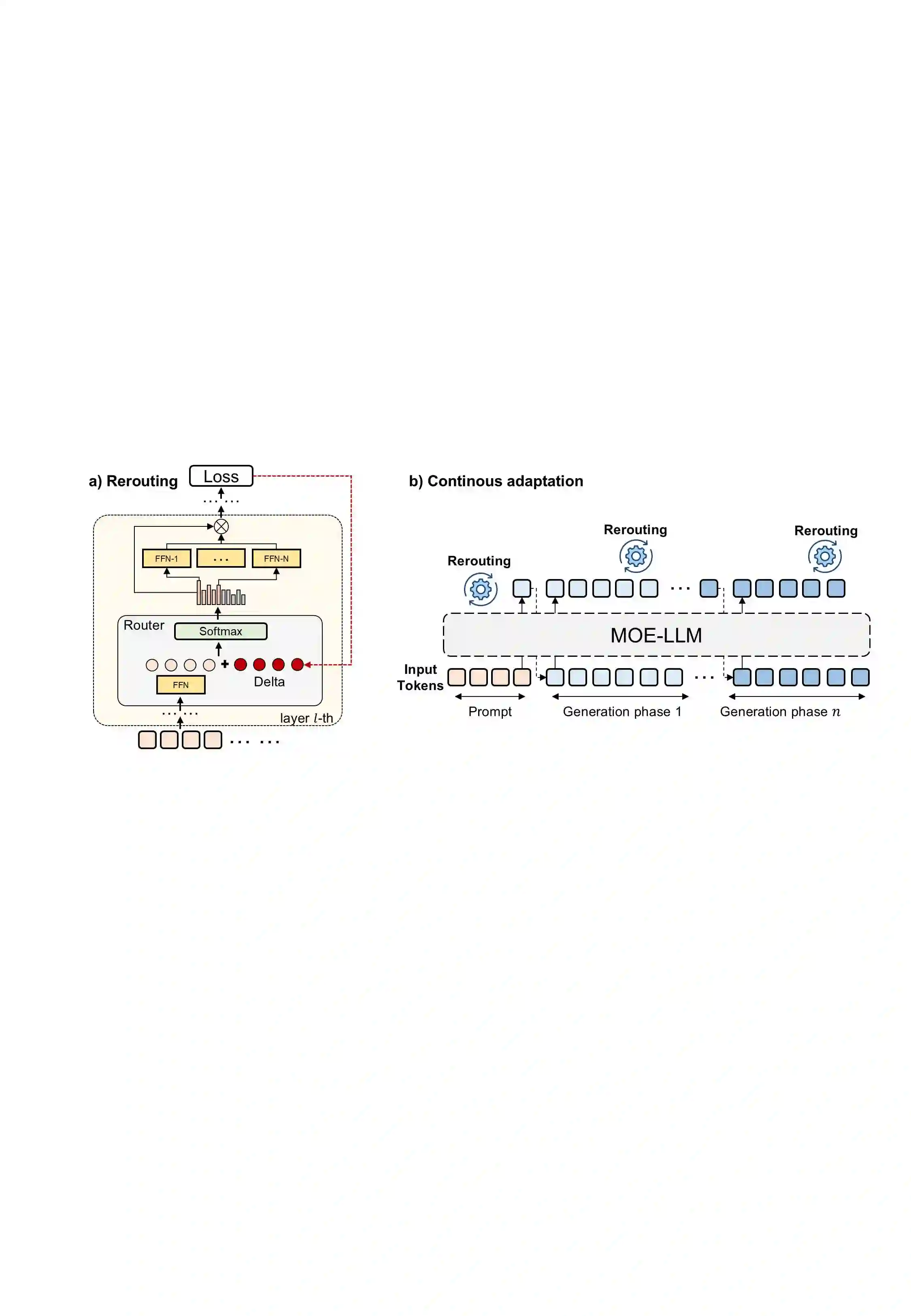
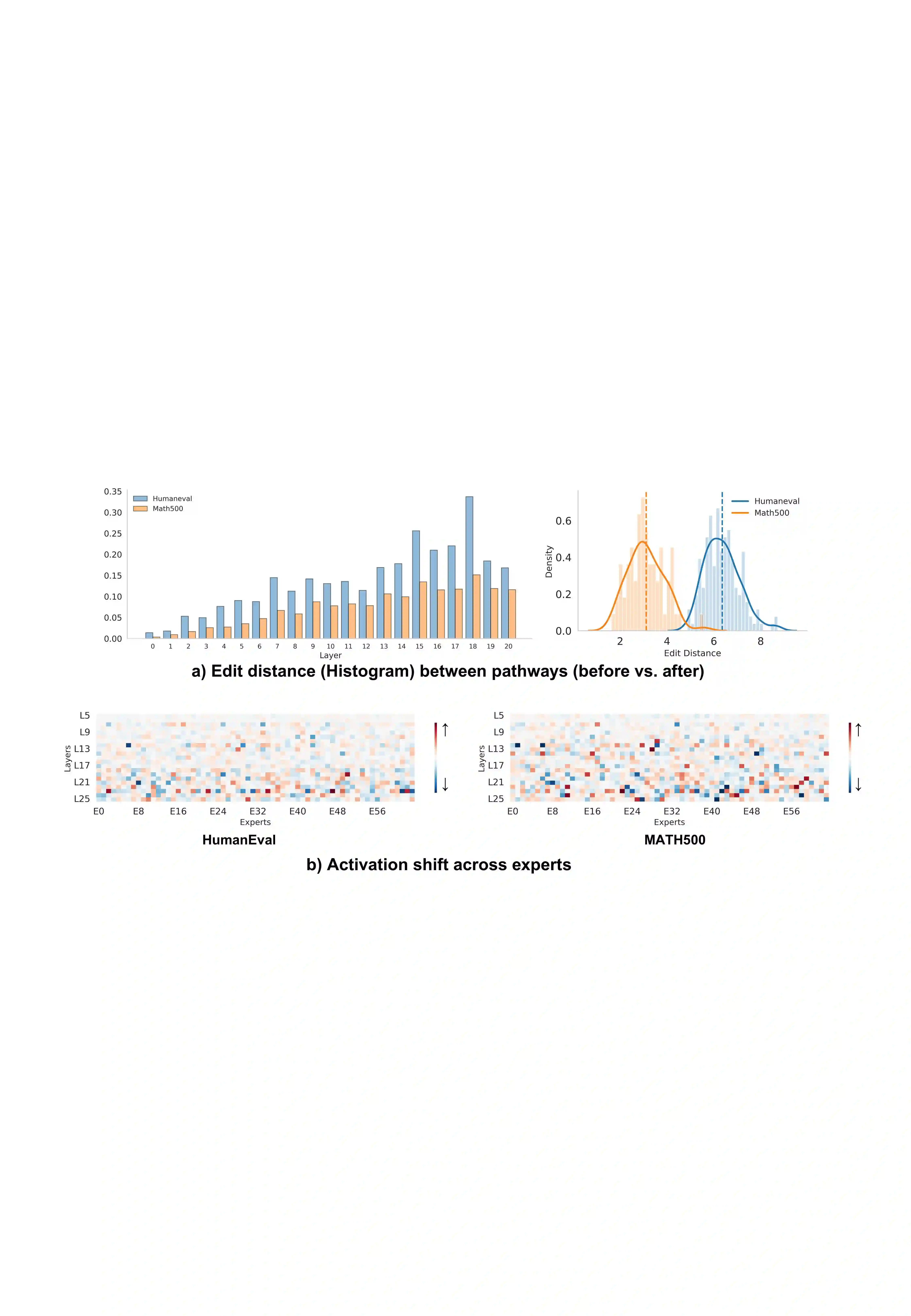
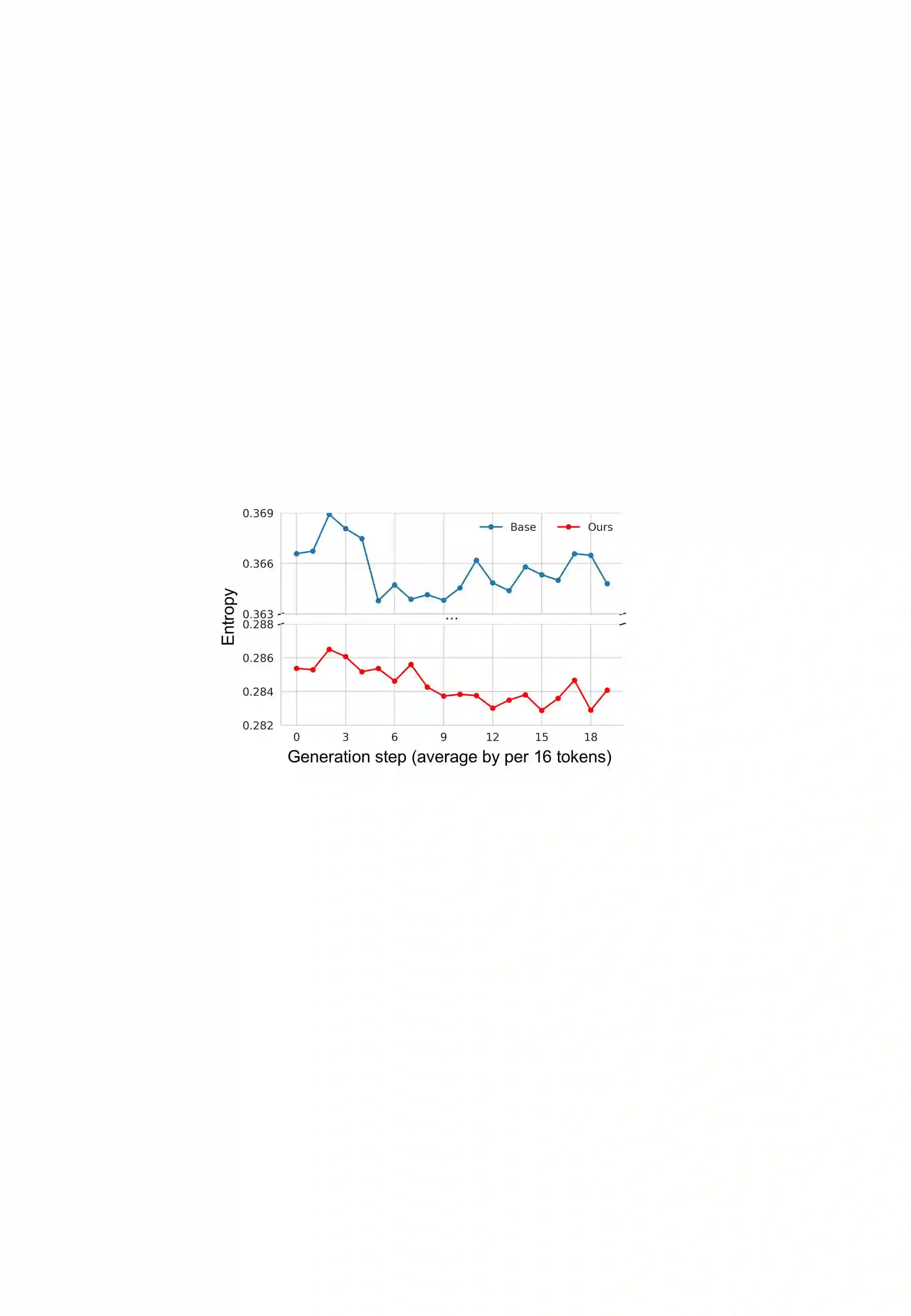
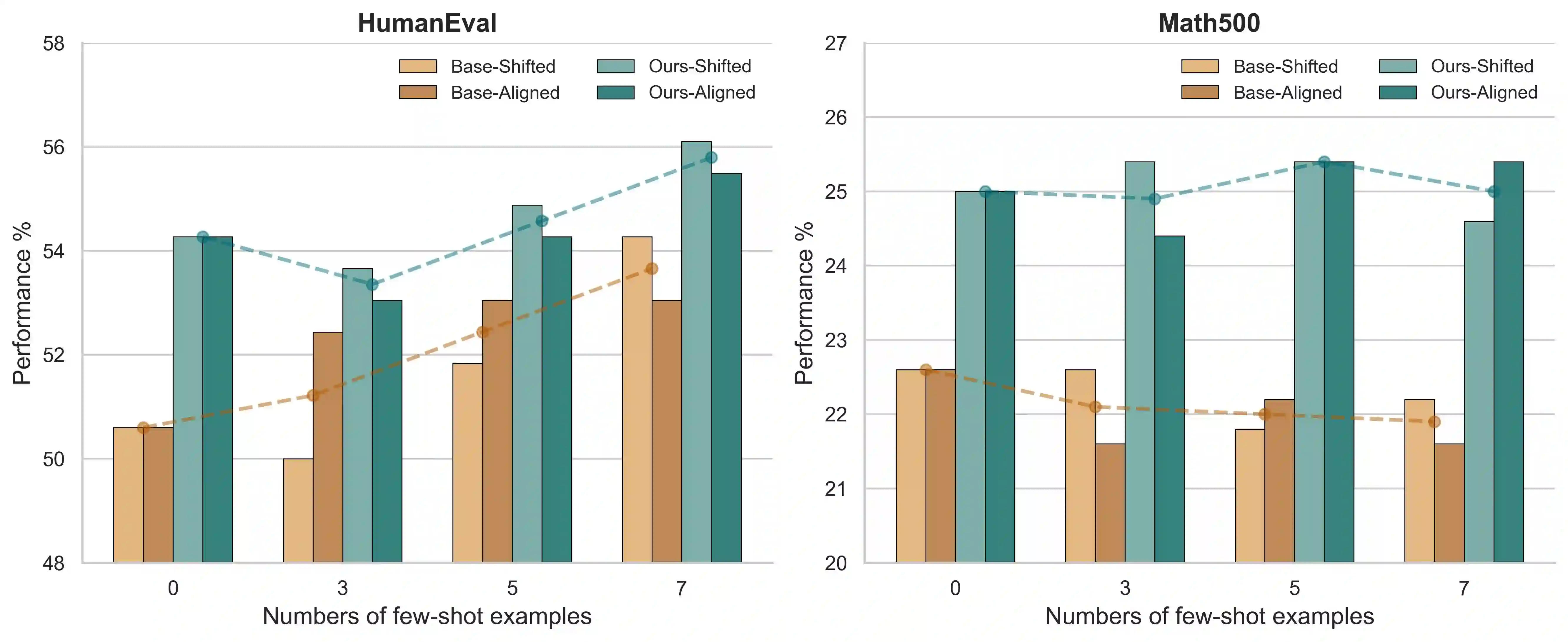
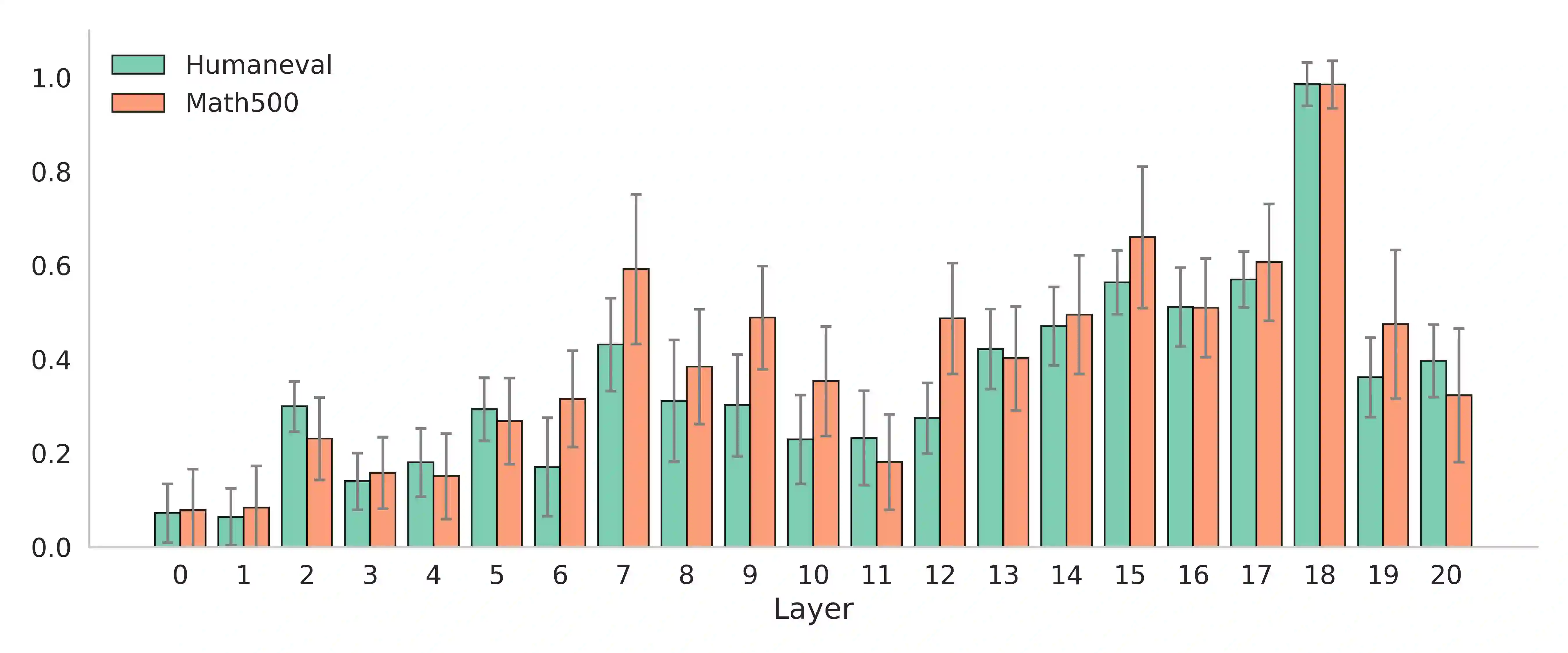
Mixture-of-Experts (MoE) models achieve efficient scaling through sparse expert activation, but often suffer from suboptimal routing decisions due to distribution shifts in deployment. While existing test-time adaptation methods could potentially address these issues, they primarily focus on dense models and require access to external data, limiting their practical applicability to MoE architectures. However, we find that, instead of relying on reference data, we can optimize MoE expert selection on-the-fly based only on input context. As such, we propose \textit{a data-free, online test-time framework} that continuously adapts MoE routing decisions during text generation without external supervision or data. Our method cycles between two phases: During the prefill stage, and later in regular intervals, we optimize the routing decisions of the model using self-supervision based on the already generated sequence. Then, we generate text as normal, maintaining the modified router until the next adaption. We implement this through lightweight additive vectors that only update router logits in selected layers, maintaining computational efficiency while preventing over-adaptation. The experimental results show consistent performance gains on challenging reasoning tasks while maintaining robustness to context shifts. For example, our method achieves a 5.5\% improvement on HumanEval with OLMoE. Furthermore, owing to its plug-and-play property, our method naturally complements existing test-time scaling techniques, e.g., achieving 6\% average gains when incorporated with self-consistency on DeepSeek-V2-Lite.
翻译:混合专家(MoE)模型通过稀疏专家激活实现高效扩展,但在部署过程中常因分布偏移而面临路由决策次优的问题。虽然现有的测试时适应方法可能解决这些问题,但它们主要针对稠密模型且需要外部数据支持,限制了其在MoE架构中的实际应用。然而我们发现,无需依赖参考数据,仅基于输入上下文即可动态优化MoE专家选择。为此,我们提出一种无需外部数据、在线的测试时适应框架,该框架能够在文本生成过程中持续优化MoE路由决策,且无需外部监督或数据。我们的方法在两个阶段间循环执行:在预填充阶段及后续的固定间隔中,基于已生成序列通过自监督方式优化模型的路由决策;随后正常生成文本,并保持修改后的路由参数直至下一次适应。我们通过轻量级加性向量实现该机制,该向量仅更新选定层的路由逻辑值,在维持计算效率的同时防止过度适应。实验结果表明,该方法在具有挑战性的推理任务上持续提升性能,同时保持对上下文偏移的鲁棒性。例如,我们的方法在OLMoE模型上实现HumanEval任务5.5%的性能提升。此外,得益于即插即用特性,该方法自然兼容现有测试时扩展技术,例如与自一致性方法结合后在DeepSeek-V2-Lite模型上实现平均6%的性能增益。