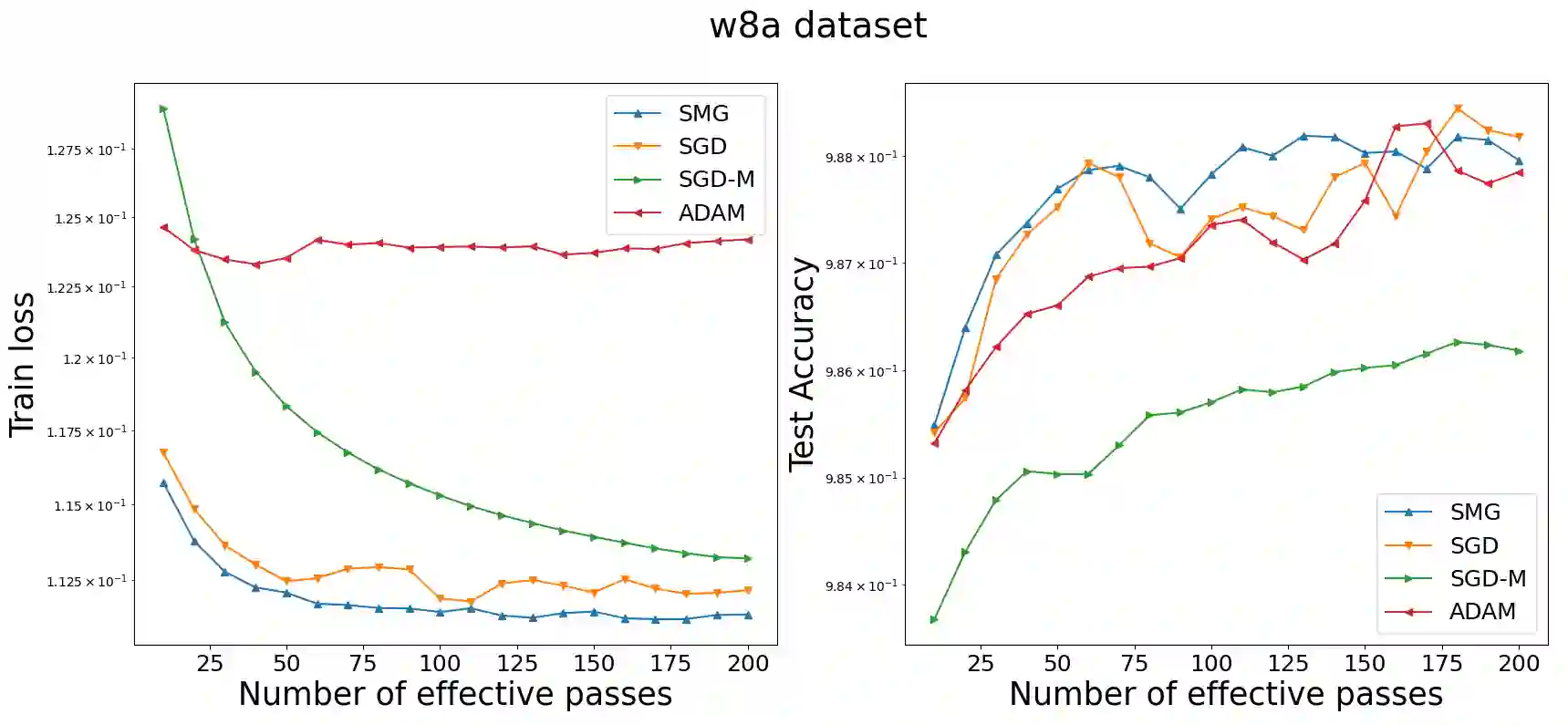
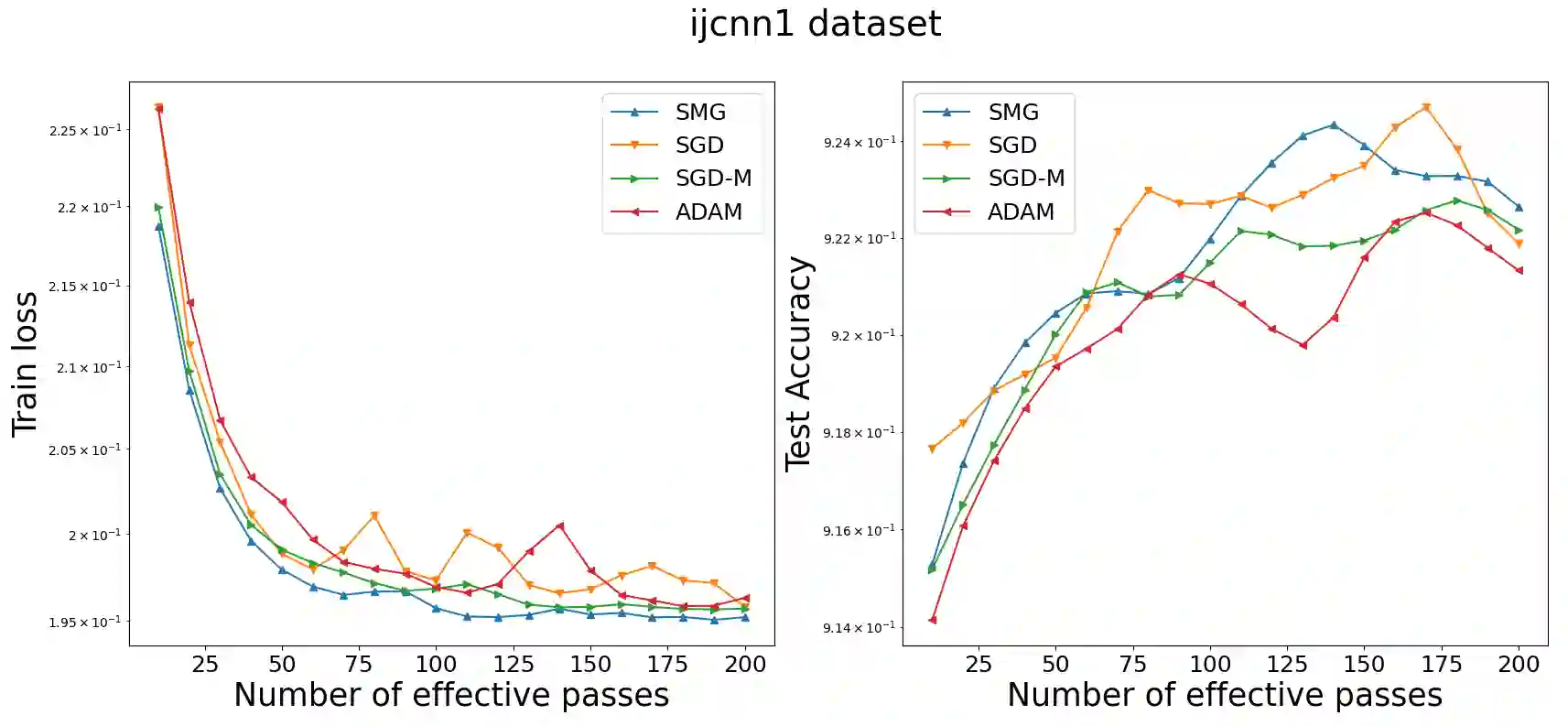
The Stochastic Gradient Descent method (SGD) and its stochastic variants have become methods of choice for solving finite-sum optimization problems arising from machine learning and data science thanks to their ability to handle large-scale applications and big datasets. In the last decades, researchers have made substantial effort to study the theoretical performance of SGD and its shuffling variants. However, only limited work has investigated its shuffling momentum variants, including shuffling heavy-ball momentum schemes for non-convex problems and Nesterov's momentum for convex settings. In this work, we extend the analysis of the shuffling momentum gradient method developed in [Tran et al (2021)] to both finite-sum convex and strongly convex optimization problems. We provide the first analysis of shuffling momentum-based methods for the strongly convex setting, attaining a convergence rate of $O(1/nT^2)$, where $n$ is the number of samples and $T$ is the number of training epochs. Our analysis is a state-of-the-art, matching the best rates of existing shuffling stochastic gradient algorithms in the literature.
翻译:随机梯度下降法(SGD)及其随机变体凭借其处理大规模应用和海量数据集的能力,已成为解决机器学习和数据科学中有限和优化问题的首选方法。近几十年来,研究人员为研究SGD及其混洗变体的理论性能付出了大量努力。然而,对于其混推动量变体的研究较为有限,包括针对非凸问题的混洗heavy-ball动量方案和针对凸设置的Nesterov动量。本文将[Tran等(2021)]提出的混推动量梯度方法的分析扩展到有限和凸优化和强凸优化问题。我们首次对强凸设置下的混推动量方法进行了分析,实现了$O(1/nT^2)$的收敛速率,其中$n$为样本数,$T$为训练轮数。我们的分析处于当前最前沿水平,与文献中现有混洗随机梯度算法的最优速率相匹配。