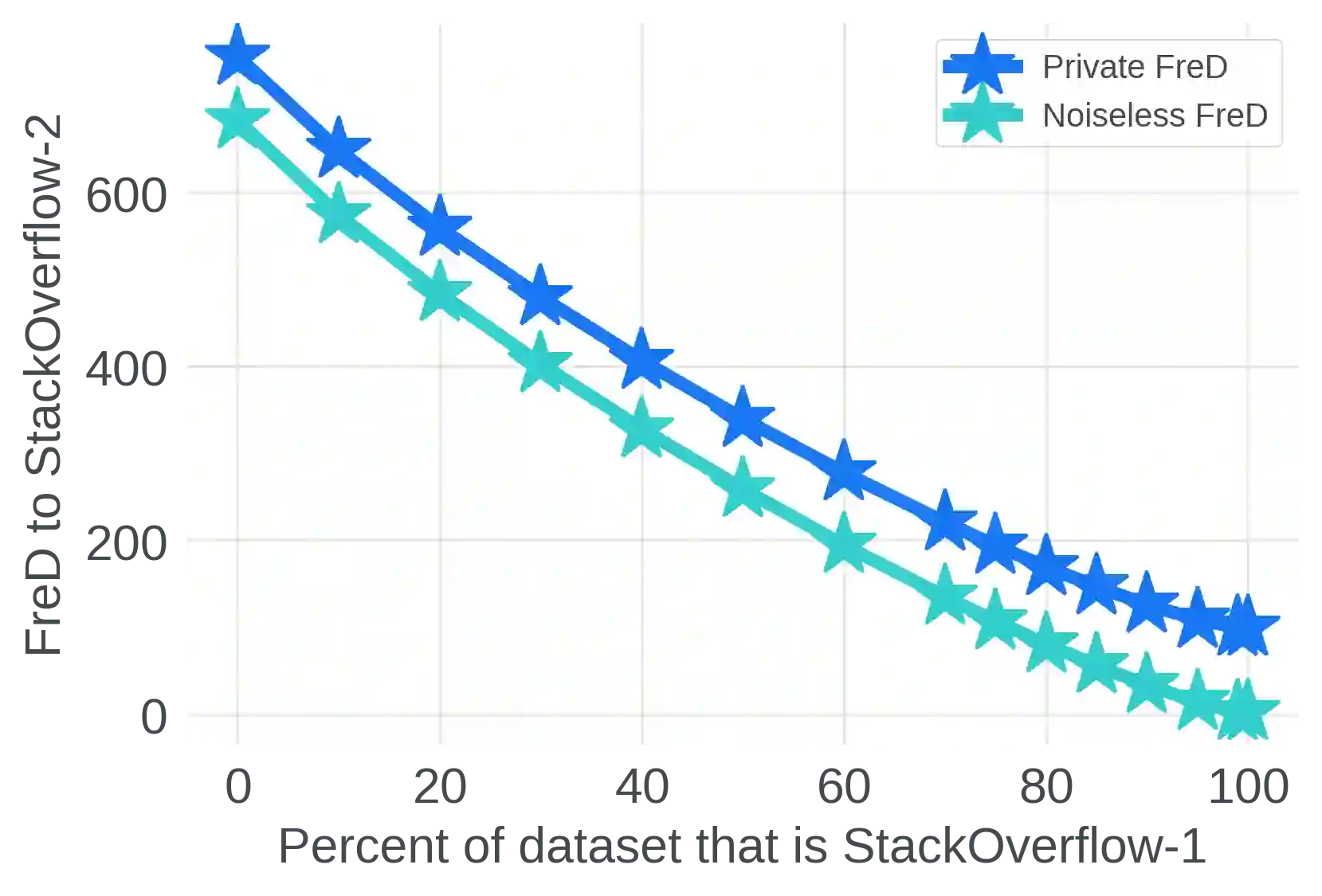
In Federated Learning (FL), accessing private client data incurs communication and privacy costs. As a result, FL deployments commonly prefinetune pretrained foundation models on a (large, possibly public) dataset that is held by the central server; they then FL-finetune the model on a private, federated dataset held by clients. Evaluating prefinetuning dataset quality reliably and privately is therefore of high importance. To this end, we propose FreD (Federated Private Fr\'echet Distance) -- a privately computed distance between a prefinetuning dataset and federated datasets. Intuitively, it privately computes and compares a Fr\'echet distance between embeddings generated by a large language model on both the central (public) dataset and the federated private client data. To make this computation privacy-preserving, we use distributed, differentially-private mean and covariance estimators. We show empirically that FreD accurately predicts the best prefinetuning dataset at minimal privacy cost. Altogether, using FreD we demonstrate a proof-of-concept for a new approach in private FL training: (1) customize a prefinetuning dataset to better match user data (2) prefinetune (3) perform FL-finetuning.
翻译:在联邦学习中,访问私有客户端数据会产生通信和隐私成本。因此,联邦学习部署通常会在中央服务器持有的(大规模、可能公开的)数据集上对预训练基础模型进行预训练微调,然后在客户端持有的私有联邦数据集上进行联邦微调。因此,可靠且隐私地评估预训练微调数据集的质量至关重要。为此,我们提出了FreD(联邦私有弗雷歇距离)——一种在预训练微调数据集与联邦数据集之间私有计算的距离度量。直观而言,该方法通过大型语言模型在中央(公开)数据集及联邦私有客户端数据上生成嵌入,继而私有计算并比较这些嵌入之间的弗雷歇距离。为了实现隐私保护计算,我们采用了分布式、差分隐私的均值和协方差估计器。实验表明,FreD能够在最小隐私成本下准确预测最佳预训练微调数据集。综合而言,我们通过FreD为私有联邦学习训练提出了一种新方法的概念验证:(1)定制预训练微调数据集以更好匹配用户数据,(2)进行预训练微调,(3)执行联邦微调。