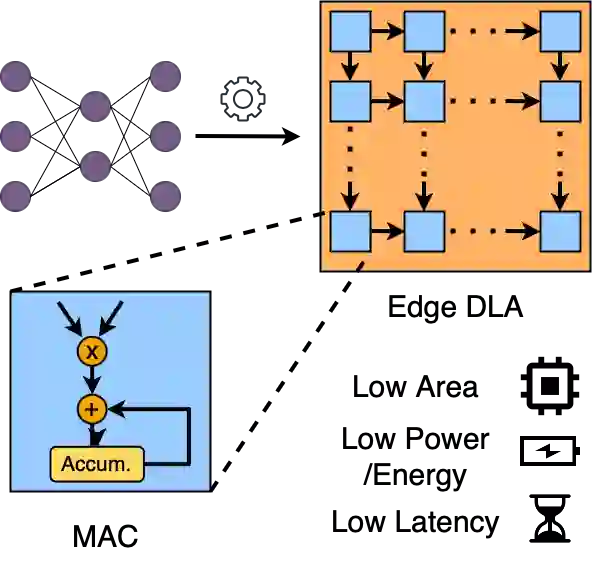
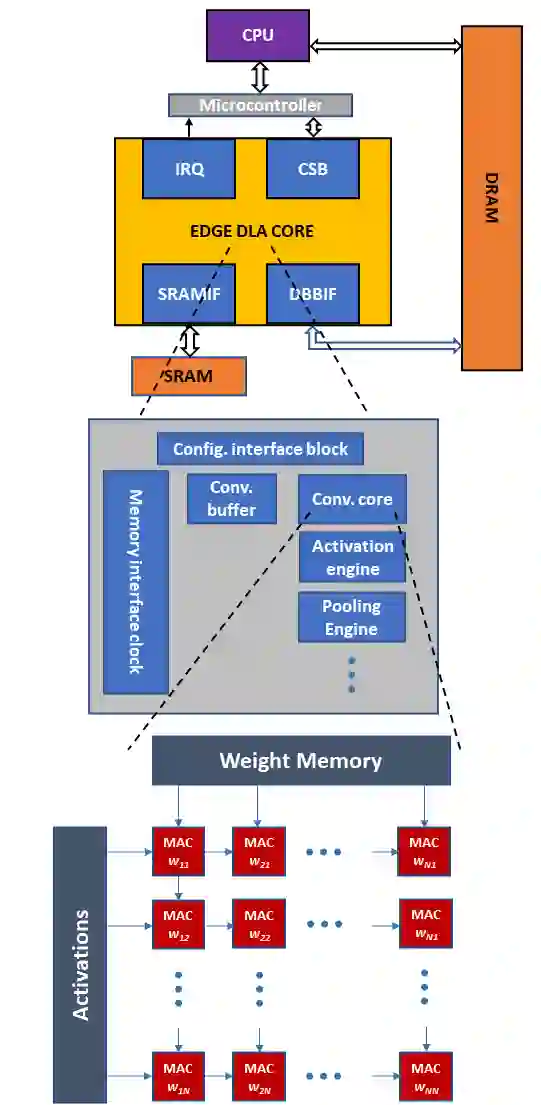
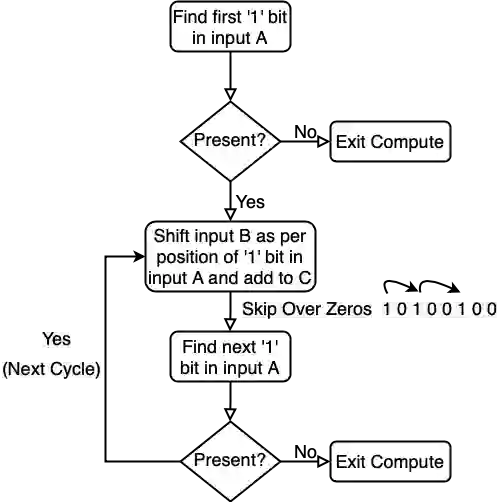
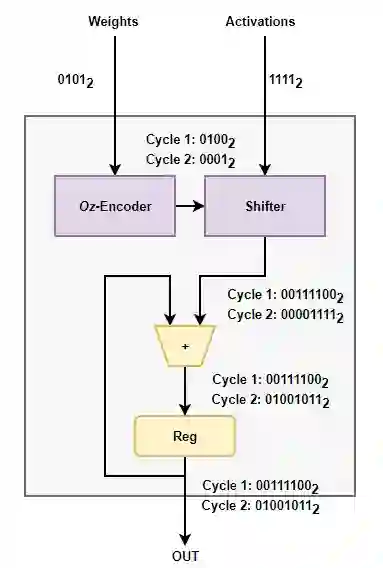
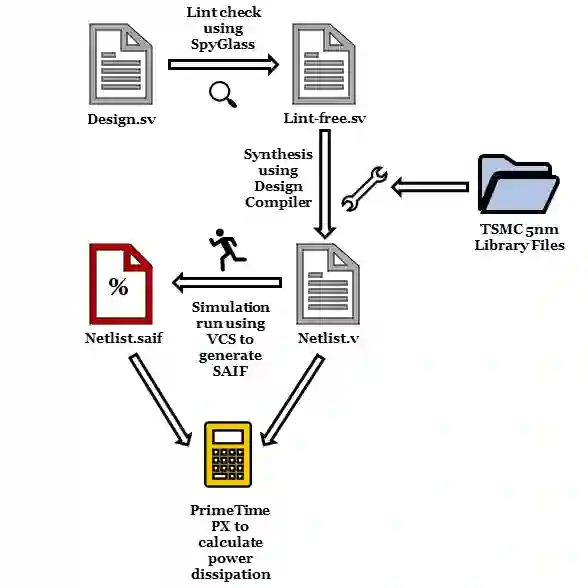
General Matrix Multiply (GEMM) hardware, employing large arrays of multiply-accumulate (MAC) units, perform bulk of the computation in deep learning (DL). Recent trends have established 8-bit integer (INT8) as the most widely used precision for DL inference. This paper proposes a novel MAC design capable of dynamically exploiting bit sparsity (i.e., number of `0' bits within a binary value) in input data to achieve significant improvements on area, power and energy. The proposed architecture, called OzMAC (Omit-zero-MAC), skips over zeros within a binary input value and performs simple shift-and-add-based compute in place of expensive multipliers. We implement OzMAC in SystemVerilog and present post-synthesis performance-power-area (PPA) results using commercial TSMC N5 (5nm) process node. Using eight pretrained INT8 deep neural networks (DNNs) as benchmarks, we demonstrate the existence of high bit sparsity in real DNN workloads and show that 8-bit OzMAC improves all three metrics of area, power, and energy significantly by 21%, 70%, and 28%, respectively. Similar improvements are achieved when scaling data precisions (4, 8, 16 bits) and clock frequencies (0.5 GHz, 1 GHz, 1.5 GHz). For the 8-bit OzMAC, scaling its frequency to normalize the throughput relative to conventional MAC, it still achieves 30% improvement on both power and energy.
翻译:通用矩阵乘法(GEMM)硬件采用大规模乘累加(MAC)单元阵列,承担了深度学习(DL)中的主要计算任务。近期趋势已将8位整数(INT8)确立为深度学习推理中最广泛使用的精度。本文提出一种新颖的乘累加设计,能够动态利用输入数据中的位稀疏性(即二进制值中“0”位的数量),从而在面积、功耗和能量方面实现显著改进。所提出的架构称为OzMAC(省略零乘累加),它跳过二进制输入值中的零位,并执行简单的移位相加计算以替代昂贵的乘法器。我们使用SystemVerilog实现了OzMAC,并展示了采用商用台积电N5(5nm)工艺节点后的综合性能-功耗-面积(PPA)结果。以八个预训练的INT8深度神经网络(DNN)作为基准测试,我们证明了实际DNN工作负载中存在高位稀疏性,并表明8位OzMAC在面积、功耗和能量三个指标上分别显著提升了21%、70%和28%。当扩展数据精度(4、8、16位)和时钟频率(0.5 GHz、1 GHz、1.5 GHz)时,同样获得了类似的改进。对于8位OzMAC,将其频率归一化至与传统MAC相同的吞吐量后,其功耗和能量仍实现了30%的改进。