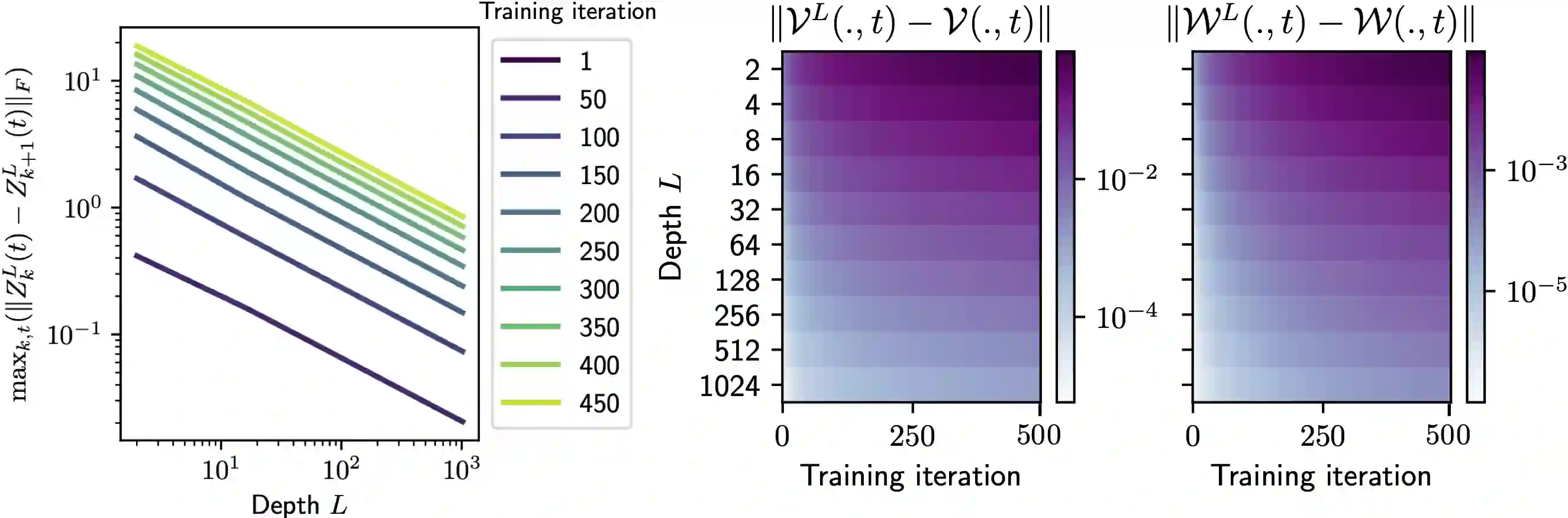
Residual neural networks are state-of-the-art deep learning models. Their continuous-depth analog, neural ordinary differential equations (ODEs), are also widely used. Despite their success, the link between the discrete and continuous models still lacks a solid mathematical foundation. In this article, we take a step in this direction by establishing an implicit regularization of deep residual networks towards neural ODEs, for nonlinear networks trained with gradient flow. We prove that if the network is initialized as a discretization of a neural ODE, then such a discretization holds throughout training. Our results are valid for a finite training time, and also as the training time tends to infinity provided that the network satisfies a Polyak-Lojasiewicz condition. Importantly, this condition holds for a family of residual networks where the residuals are two-layer perceptrons with an overparameterization in width that is only linear, and implies the convergence of gradient flow to a global minimum. Numerical experiments illustrate our results.
翻译:残差神经网络是当前最优的深度学习模型,其连续深度对应的神经常微分方程(ODE)亦被广泛使用。尽管这些模型取得了成功,但离散模型与连续模型之间的数学基础仍缺乏严格的理论支撑。本文通过建立深度残差网络向神经ODE的隐式正则化机制,为非线性网络在梯度流训练下的行为研究迈出关键一步。我们证明:若网络初始化为神经ODE的离散化形式,则该离散化性质将在整个训练过程中保持。该结论在有限训练时间内成立,且当网络满足Polyak-Lojasiewicz条件时,训练时间趋于无穷时同样成立。重要的是,该条件对于一类残差网络成立——其残差模块为双层感知机,且宽度超参数化仅需线性增长——并确保梯度流收敛至全局最小值。数值实验验证了我们的理论结果。