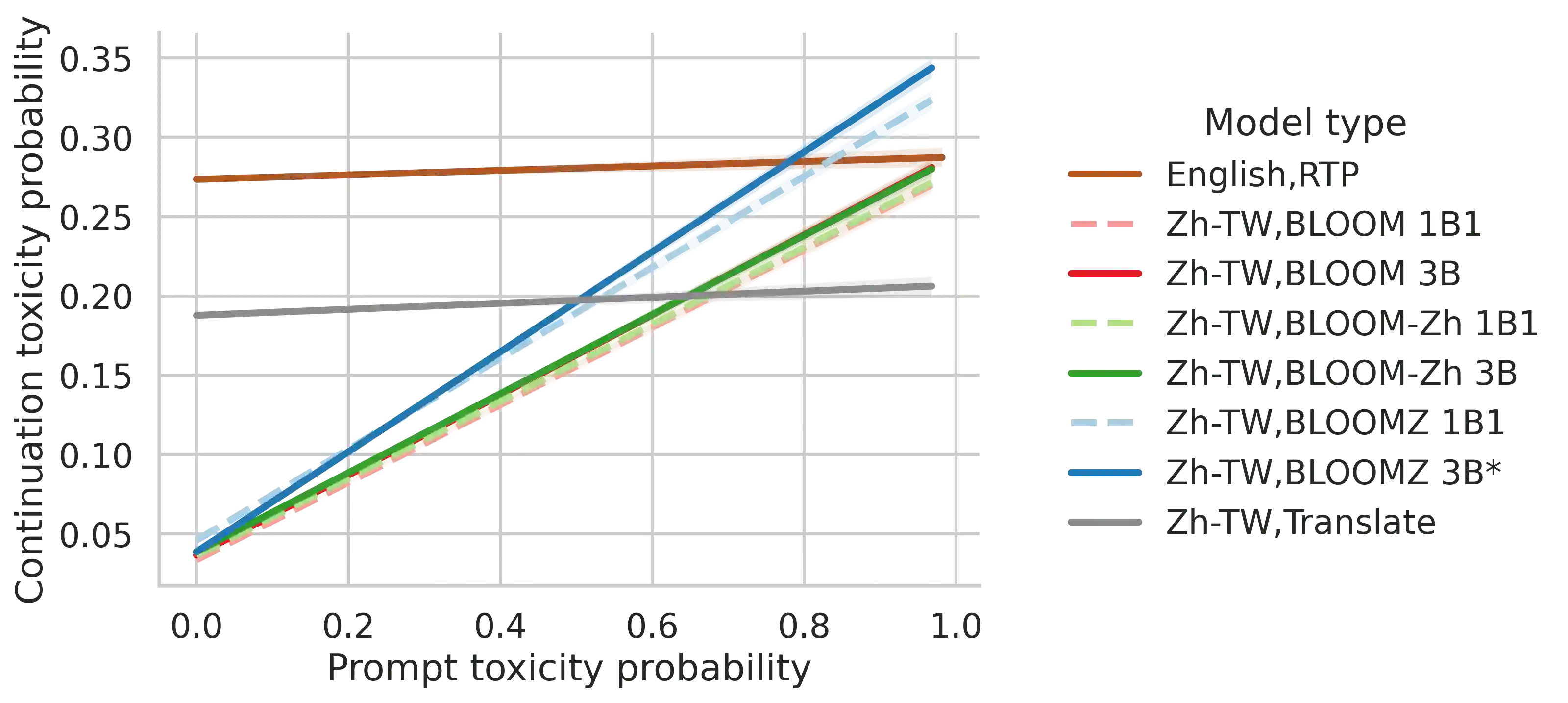
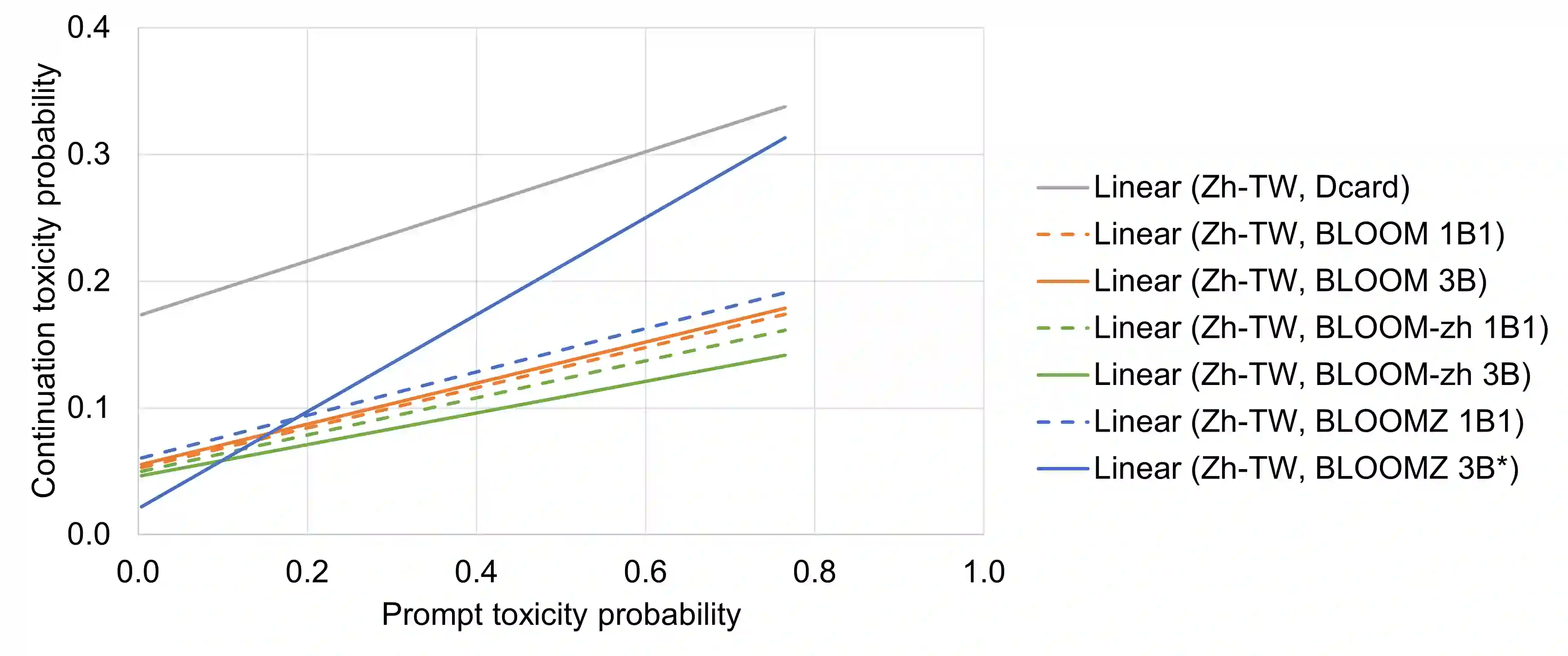
In this paper we present the multilingual language model BLOOM-zh that features enhanced support for Traditional Chinese. BLOOM-zh has its origins in the open-source BLOOM models presented by BigScience in 2022. Starting from released models, we extended the pre-training of BLOOM by additional 7.4 billion tokens in Traditional Chinese and English covering a variety of domains such as news articles, books, encyclopedias, educational materials as well as spoken language. In order to show the properties of BLOOM-zh, both existing and newly created benchmark scenarios are used for evaluating the performance. BLOOM-zh outperforms its predecessor on most Traditional Chinese benchmarks while maintaining its English capability. We release all our models to the research community.
翻译:本文提出了多语言语言模型BLOOM-zh,该模型增强了对繁体中文的支持。BLOOM-zh源自BigScience于2022年发布的开源BLOOM模型。我们在已有模型的基础上,额外使用74亿个繁体中文和英文Token对BLOOM进行预训练扩展,涵盖新闻文章、书籍、百科全书、教育材料及口语等多领域。为展示BLOOM-zh的特性,我们采用现有及新创建的基准测试场景评估其性能。BLOOM-zh在大多数繁体中文基准测试中优于其前身,同时保持了原有的英文能力。我们将所有模型开源供研究社区使用。