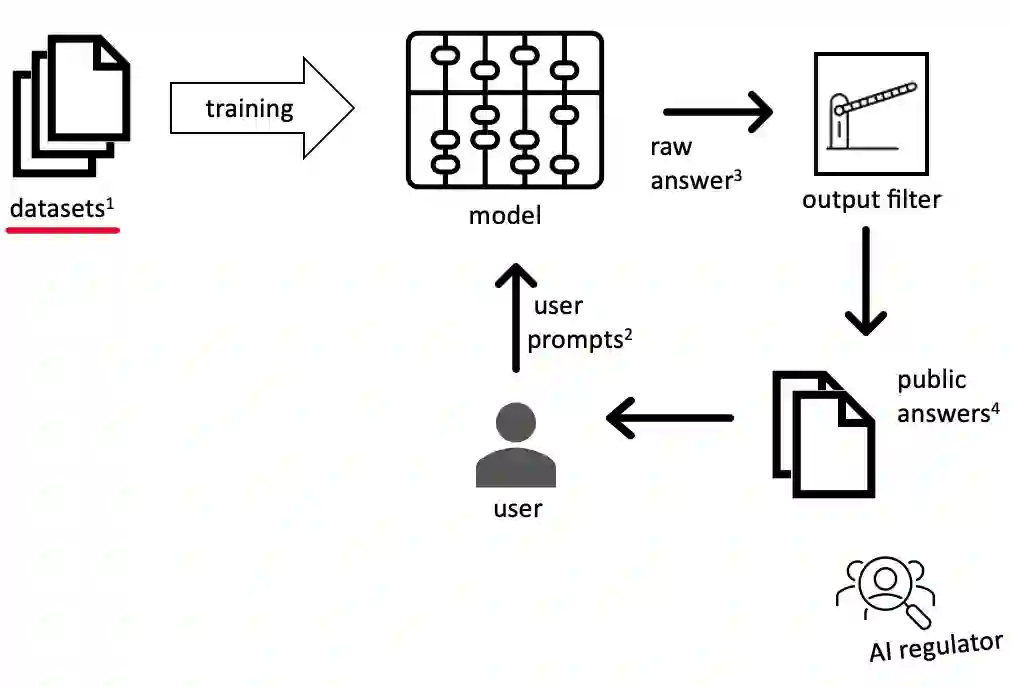
This paper explores how AI-owners can develop safeguards for AI-generated content by drawing from established codes of conduct and ethical standards in other content-creation industries. It delves into the current state of ethical awareness on Large Language Models (LLMs). By dissecting the mechanism of content generation by LLMs, four key areas (upstream/downstream and at user prompt/answer), where safeguards could be effectively applied, are identified. A comparative analysis of these four areas follows and includes an evaluation of the existing ethical safeguards in terms of cost, effectiveness, and alignment with established industry practices. The paper's key argument is that existing IT-related ethical codes, while adequate for traditional IT engineering, are inadequate for the challenges posed by LLM-based content generation. Drawing from established practices within journalism, we propose potential standards for businesses involved in distributing and selling LLM-generated content. Finally, potential conflicts of interest between dataset curation at upstream and ethical benchmarking downstream are highlighted to underscore the need for a broader evaluation beyond mere output. This study prompts a nuanced conversation around ethical implications in this rapidly evolving field of content generation.
翻译:本文探讨了AI所有者如何借鉴其他内容创作行业中既有的行为准则和伦理标准,为AI生成内容开发保障措施。它深入分析了大型语言模型(LLM)的伦理意识现状。通过剖析LLM的内容生成机制,确定了四个关键领域(上游/下游及用户提示/回答),在这些领域中可以有效应用保障措施。随后对这四大领域进行了比较分析,包括从成本、有效性以及与行业惯例的一致性角度评估现有的伦理保障措施。本文的核心论点是,现有的IT相关伦理准则虽然对传统IT工程足够,但不足以应对基于LLM的内容生成所带来的挑战。借鉴新闻业的既有实践,我们为参与分发和销售LLM生成内容的企业提出了潜在标准。最后,强调了上游数据集策展与下游伦理基准测试之间的潜在利益冲突,以突显超越单纯输出评估的更广泛评估的必要性。这项研究促进了关于这个快速发展的内容生成领域中伦理影响的细致讨论。