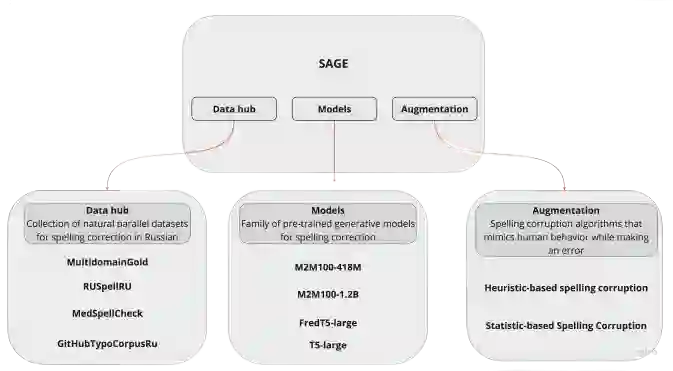
Modern large language models demonstrate impressive capabilities in text generation and generalization. However, they often struggle with solving text editing tasks, particularly when it comes to correcting spelling errors and mistypings. In this paper, we present a methodology for generative spelling correction (SC), which was tested on English and Russian languages and potentially can be extended to any language with minor changes. Our research mainly focuses on exploring natural spelling errors and mistypings in texts and studying the ways those errors can be emulated in correct sentences to effectively enrich generative models' pre-train procedure. We investigate the impact of such emulations and the models' abilities across different text domains. In this work, we investigate two spelling corruption techniques: 1) first one mimics human behavior when making a mistake through leveraging statistics of errors from particular dataset and 2) second adds the most common spelling errors, keyboard miss clicks, and some heuristics within the texts. We conducted experiments employing various corruption strategies, models' architectures and sizes on the pre-training and fine-tuning stages and evaluated the models using single-domain and multi-domain test sets. As a practical outcome of our work, we introduce SAGE(Spell checking via Augmentation and Generative distribution Emulation). It is a library for automatic generative SC that includes a family of pre-trained generative models and built-in augmentation algorithms.
翻译:现代大型语言模型在文本生成和泛化方面展现出令人瞩目的能力。然而,它们在处理文本编辑任务时往往存在困难,尤其是在纠正拼写错误和打字错误方面。本文提出了一种生成式拼写校正(SC)方法论,该方法已在英语和俄语上进行了测试,并可能通过少量修改扩展到任何语言。我们的研究主要聚焦于探索文本中的自然拼写错误和打字错误,并研究如何在正确句子中模拟这些错误,以有效丰富生成式模型的预训练过程。我们考察了此类模拟的影响以及模型在不同文本领域的能力。本研究探讨了两种拼写破坏技术:1)第一种通过利用特定数据集中的错误统计来模拟人类犯错行为;2)第二种则在文本中添加最常见的拼写错误、键盘误点击及一些启发式规则。我们采用不同的破坏策略、模型架构和规模,在预训练和微调阶段进行了实验,并使用单领域和多领域测试集对模型进行了评估。作为本研究的实践成果,我们推出了SAGE(基于增强与生成式分布模拟的拼写检查)——一个用于自动生成式SC的库,包含一系列预训练生成式模型和内置的增强算法。