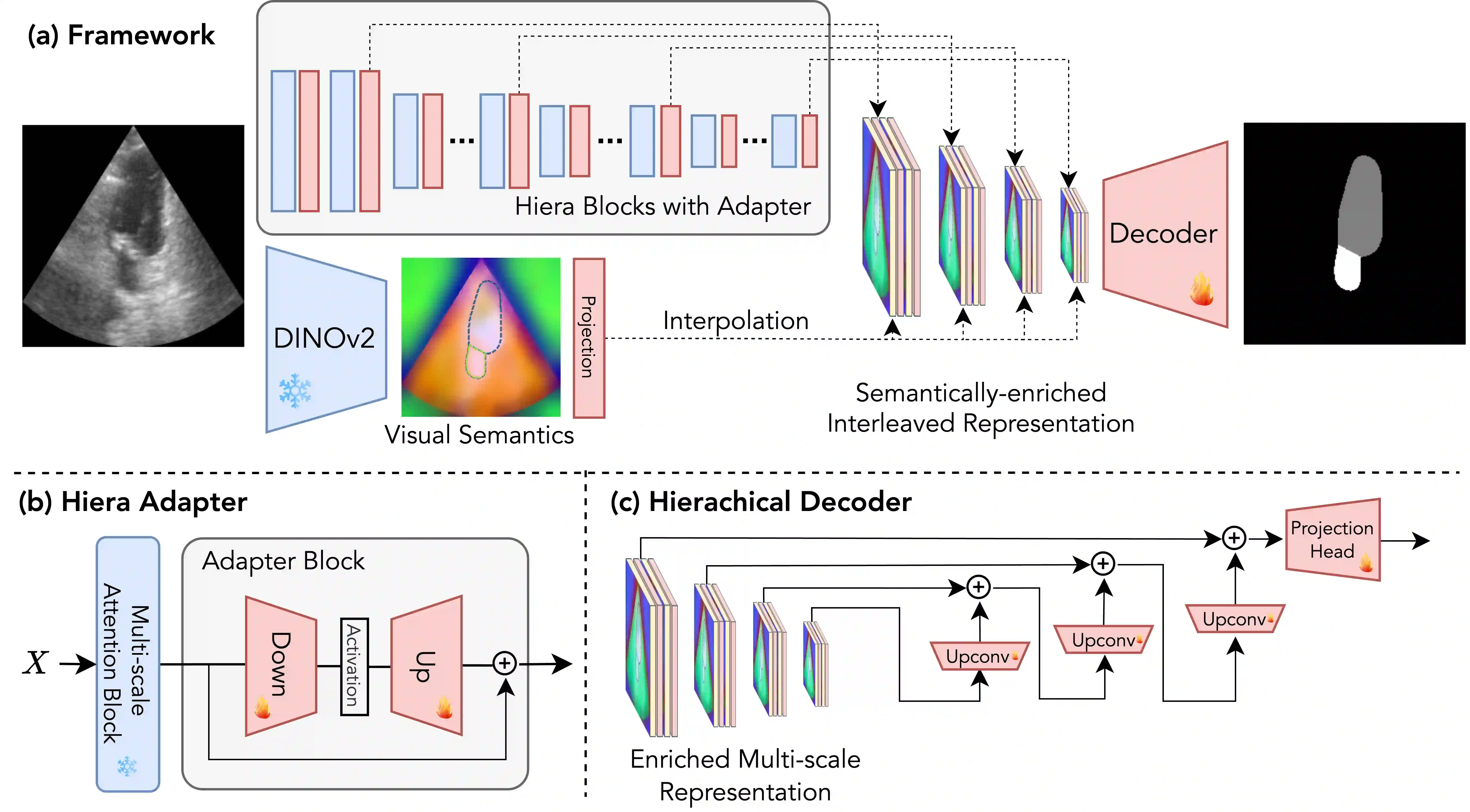
We propose a novel approach that adapts hierarchical vision foundation models for real-time ultrasound image segmentation. Existing ultrasound segmentation methods often struggle with adaptability to new tasks, relying on costly manual annotations, while real-time approaches generally fail to match state-of-the-art performance. To overcome these limitations, we introduce an adaptive framework that leverages the vision foundation model Hiera to extract multi-scale features, interleaved with DINOv2 representations to enhance visual expressiveness. These enriched features are then decoded to produce precise and robust segmentation. We conduct extensive evaluations on six public datasets and one in-house dataset, covering both cardiac and thyroid ultrasound segmentation. Experiments show that our approach outperforms state-of-the-art methods across multiple datasets and excels with limited supervision, surpassing nnUNet by over 20\% on average in the 1\% and 10\% data settings. Our method achieves $\sim$77 FPS inference speed with TensorRT on a single GPU, enabling real-time clinical applications.
翻译:我们提出了一种新颖的方法,将分层视觉基础模型适配于实时超声图像分割任务。现有的超声分割方法通常难以适应新任务,且依赖成本高昂的人工标注,而实时方法则普遍无法达到最先进的性能。为克服这些局限性,我们引入了一个自适应框架,该框架利用视觉基础模型Hiera提取多尺度特征,并与DINOv2表征交错融合以增强视觉表达能力。这些增强后的特征随后被解码以生成精确且鲁棒的分割结果。我们在六个公共数据集和一个内部数据集上进行了广泛评估,涵盖心脏和甲状腺超声分割。实验表明,我们的方法在多个数据集上均优于最先进的方法,并在有限监督条件下表现优异,在1%和10%数据设置下平均超越nnUNet超过20%。我们的方法在单GPU上使用TensorRT实现了约77 FPS的推理速度,能够满足实时临床应用需求。