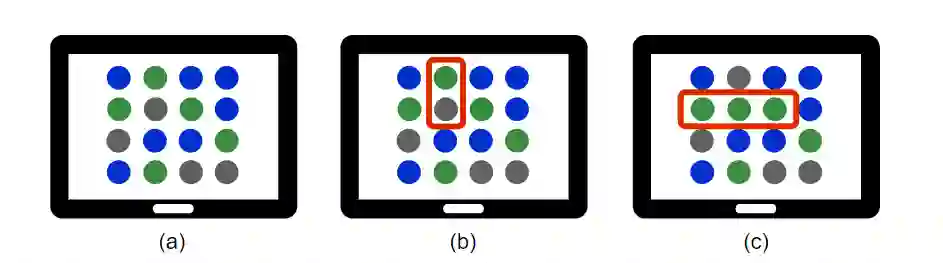
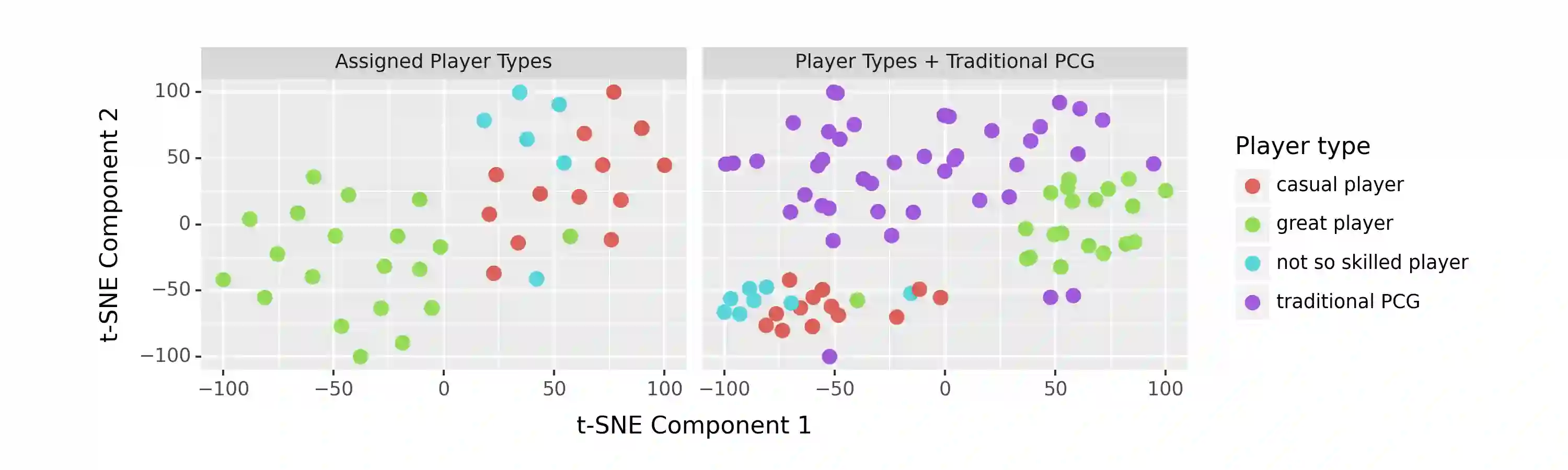
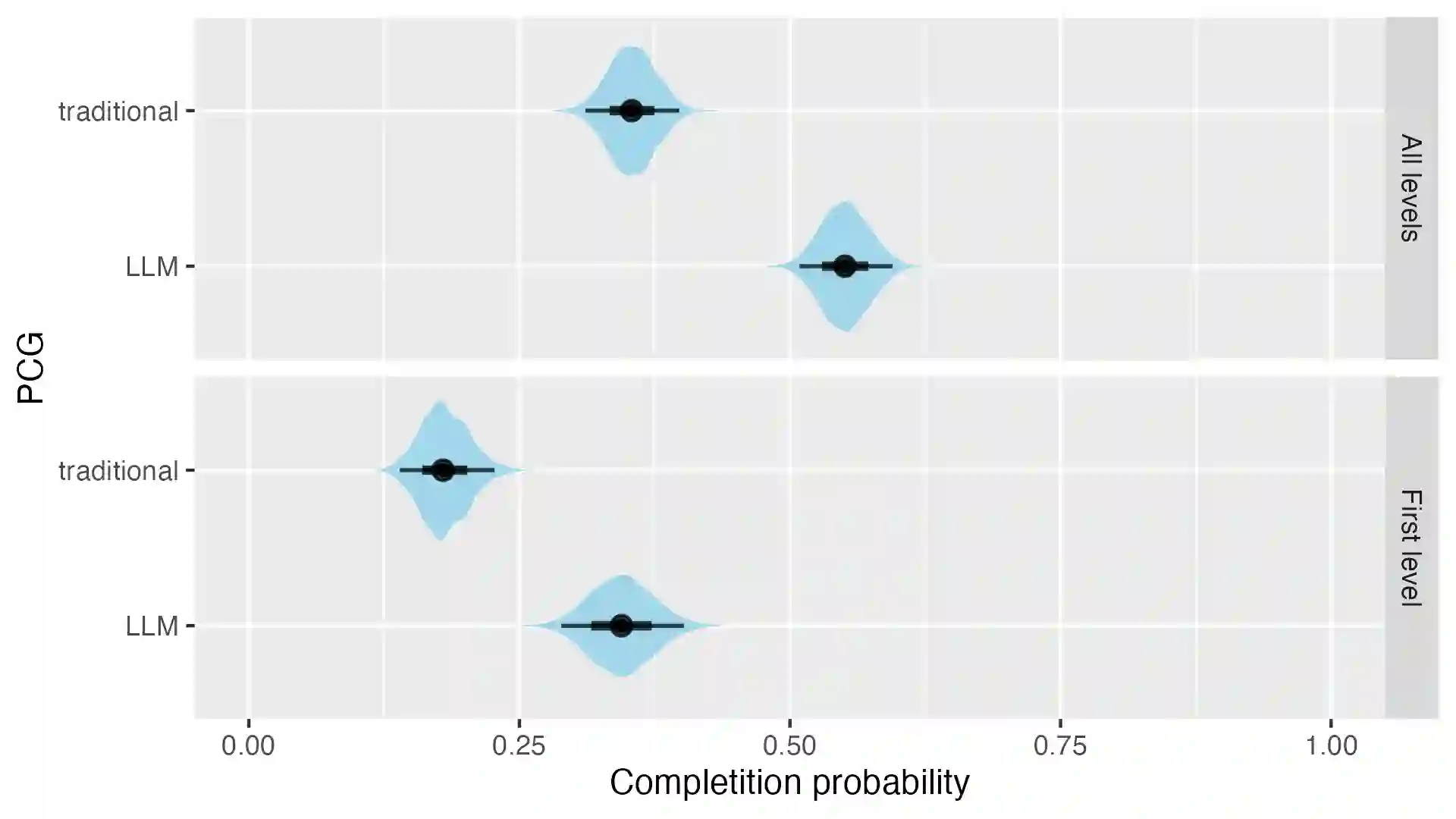
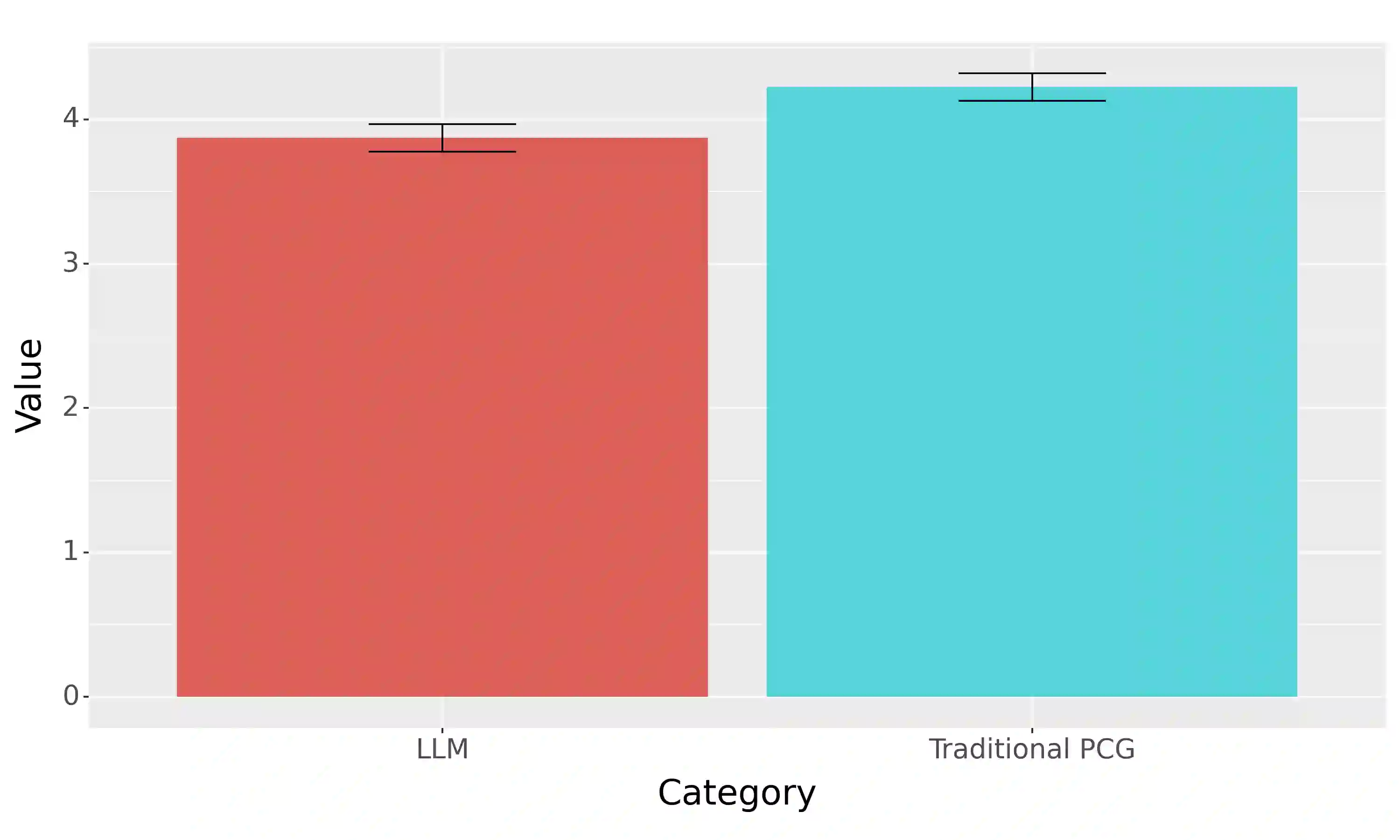
Procedural content generation uses algorithmic techniques to create large amounts of new content for games at much lower production costs. In newer approaches, procedural content generation utilizes machine learning. However, these methods usually require expensive collection of large amounts of data, as well as the development and training of fairly complex learning models, which can be both extremely time-consuming and expensive. The core of our research is to explore whether we can lower the barrier to the use of personalized procedural content generation through a more practical and generalizable approach with large language models. Matching game content with player preferences benefits both players, who enjoy the game more, and developers, who increasingly depend on players enjoying the game before being able to monetize it. Therefore, this paper presents a novel approach to achieving personalization by using large language models to propose levels based on the gameplay data continuously collected from individual players. We compared the levels generated using our approach with levels generated with more traditional procedural generation techniques. Our easily reproducible method has proven viable in a production setting and outperformed levels generated by traditional methods in the probability that a player will not quit the game mid-level.
翻译:程序化内容生成利用算法技术,以远低于传统方式的成本为游戏生成大量新内容。在较新的方法中,程序化内容生成借助机器学习实现。然而,这些方法通常需要耗费大量资源收集海量数据,同时开发和训练相当复杂的学习模型,这一过程既极其耗时又成本高昂。我们研究的核心在于探索能否通过更实用且更具泛化性的方法,利用大型语言模型降低个性化程序化内容生成的应用门槛。将游戏内容与玩家偏好相匹配,既能提升玩家的游戏体验,也有益于开发者——开发者的盈利愈发依赖玩家在游戏过程中获得良好体验。为此,本文提出一种新颖的个性化实现方法:基于持续从单个玩家收集的游戏数据,使用大型语言模型生成关卡。我们将该方法生成的关卡与传统程序化内容生成技术产生的关卡进行了对比。这一易于复现的方法在生产环境中被证实具有可行性,并且在降低玩家中途退出关卡概率方面优于传统方法生成的关卡。