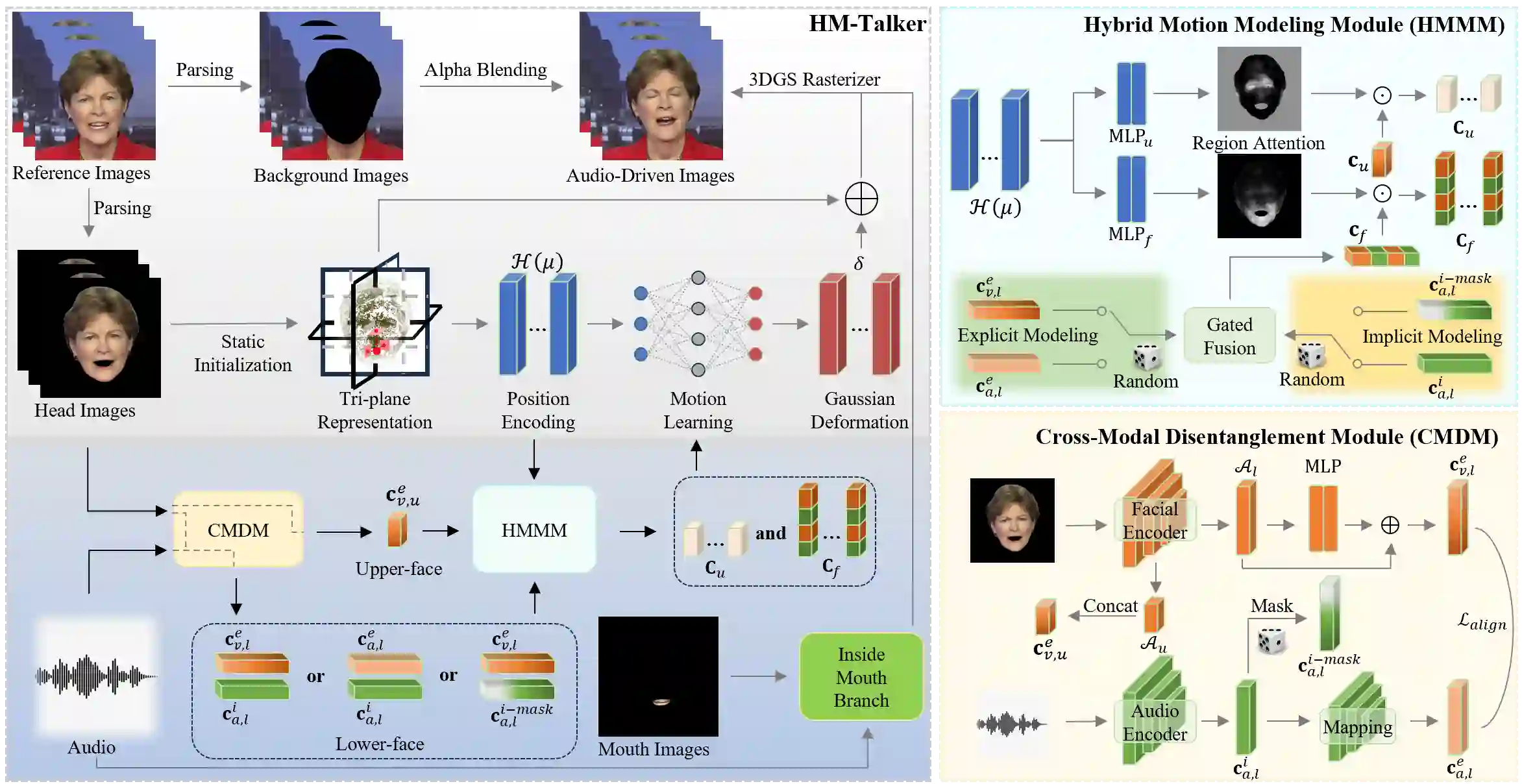
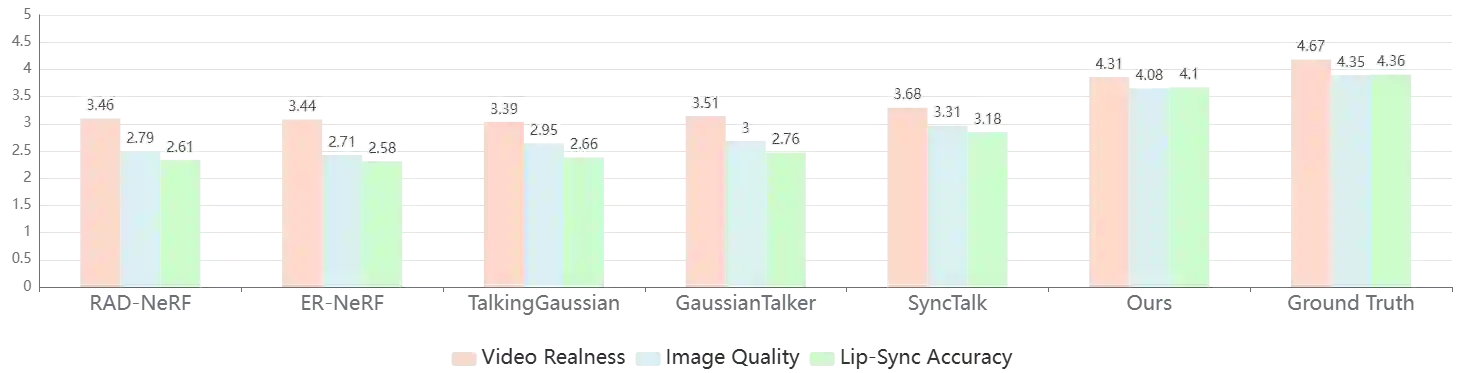
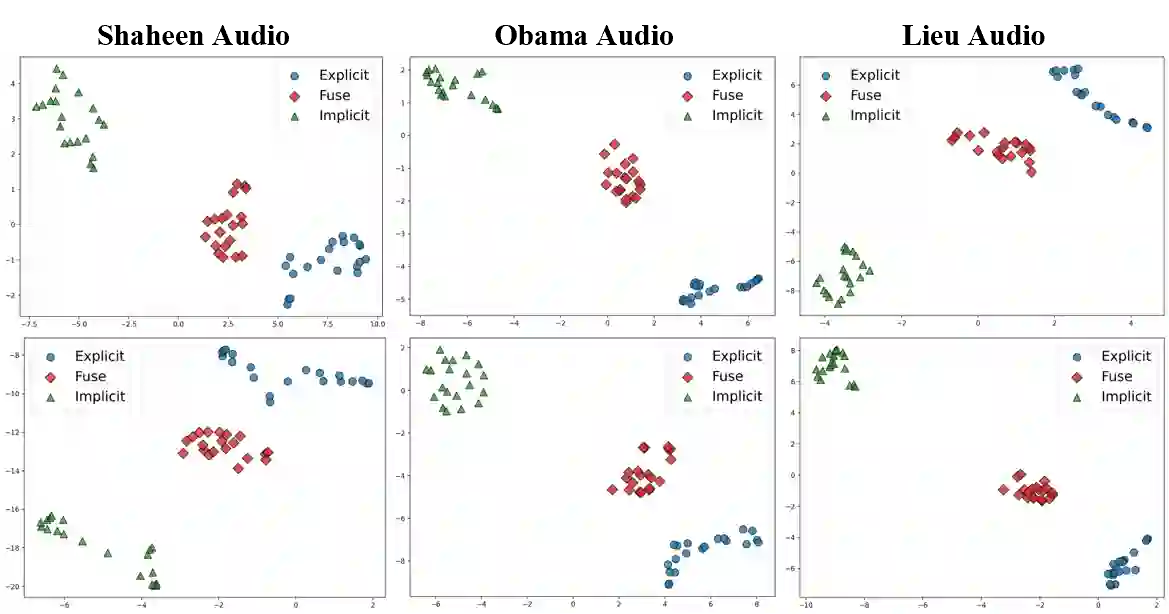
Audio-driven talking head video generation enhances user engagement in human-computer interaction. However, current methods frequently produce videos with motion blur and lip jitter, primarily due to their reliance on implicit modeling of audio-facial motion correlations--an approach lacking explicit articulatory priors (i.e., anatomical guidance for speech-related facial movements). To overcome this limitation, we propose HM-Talker, a novel framework for generating high-fidelity, temporally coherent talking heads. HM-Talker leverages a hybrid motion representation combining both implicit and explicit motion cues. Explicit cues use Action Units (AUs), anatomically defined facial muscle movements, alongside implicit features to minimize phoneme-viseme misalignment. Specifically, our Cross-Modal Disentanglement Module (CMDM) extracts complementary implicit/explicit motion features while predicting AUs directly from audio input aligned to visual cues. To mitigate identity-dependent biases in explicit features and enhance cross-subject generalization, we introduce the Hybrid Motion Modeling Module (HMMM). This module dynamically merges randomly paired implicit/explicit features, enforcing identity-agnostic learning. Together, these components enable robust lip synchronization across diverse identities, advancing personalized talking head synthesis. Extensive experiments demonstrate HM-Talker's superiority over state-of-the-art methods in visual quality and lip-sync accuracy.
翻译:音频驱动的说话头视频生成增强了人机交互中的用户参与度。然而,现有方法常因依赖音频-面部运动关联的隐式建模——一种缺乏明确发音先验(即语音相关面部运动的解剖学指导)的方法——而产生运动模糊和唇部抖动的视频。为克服此局限,我们提出了HM-Talker,一种生成高保真、时序连贯说话头的新框架。HM-Talker利用结合隐式与显式运动线索的混合运动表征:显式线索采用解剖学定义的面部肌肉运动单元(AUs),与隐式特征协同以减少音素-视位错位。具体而言,我们的跨模态解缠模块(CMDM)从对齐视觉线索的音频输入中提取互补的隐式/显式运动特征并直接预测AUs。为降低显式特征中的身份依赖性偏差并增强跨主体泛化能力,我们引入了混合运动建模模块(HMMM)。该模块动态融合随机配对的隐式/显式特征,强制进行身份无关学习。这些组件共同实现了跨多样身份的鲁棒唇部同步,推动了个性化说话头合成的发展。大量实验证明,HM-Talker在视觉质量与唇部同步准确性上均优于当前最先进方法。