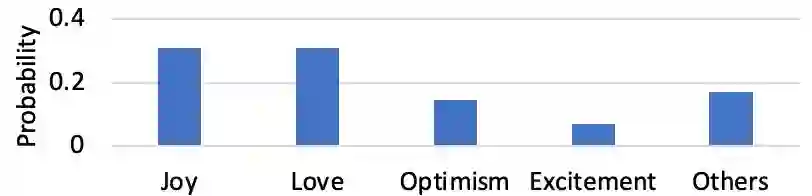
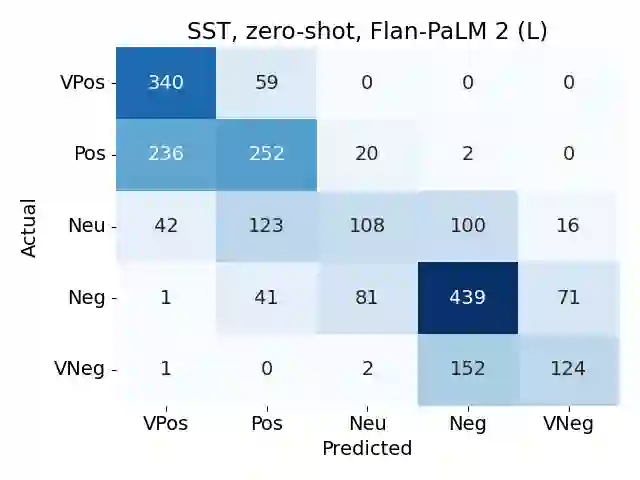
In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic similarity between the ICL demonstrations and test inputs by using a text retriever, which however is sub-optimal as that does not consider the LLM's existing knowledge about that task. From prior work (Lyu et al., 2023), we already know that labels paired with the demonstrations bias the model predictions. This leads us to our hypothesis whether considering LLM's existing knowledge about the task, especially with respect to the output label space can help in a better demonstration selection strategy. Through extensive experimentation on three text classification tasks, we find that it is beneficial to not only choose semantically similar ICL demonstrations but also to choose those demonstrations that help resolve the inherent label ambiguity surrounding the test example. Interestingly, we find that including demonstrations that the LLM previously mis-classified and also fall on the test example's decision boundary, brings the most performance gain.
翻译:上下文学习(ICL)——即仅向大语言模型展示少量任务特定示范——已在下游任务中取得性能提升,且无需进行任务特定的微调。然而,大语言模型对提示词的选择高度敏感,因此关键研究问题在于如何为ICL选取优质示范。一种有效策略是通过文本检索器利用ICL示范与测试输入之间的语义相似性,但这种做法未考虑模型对该任务的现有知识,因此并非最优方案。基于先前研究(Lyu等人,2023),我们已经知道示范标签会偏置模型预测结果。这启发我们提出假设:将大语言模型对任务的现有知识(特别是输出标签空间维度)纳入考量,能否优化示范选取策略?通过在三个文本分类任务上的大量实验,我们发现不仅应选择语义相似的ICL示范,更应选取那些有助于消解测试样本固有标签歧义的示范。有趣的是,研究发现纳入曾被大语言模型误分类且处于测试样本决策边界上的示范,能带来最大的性能提升。