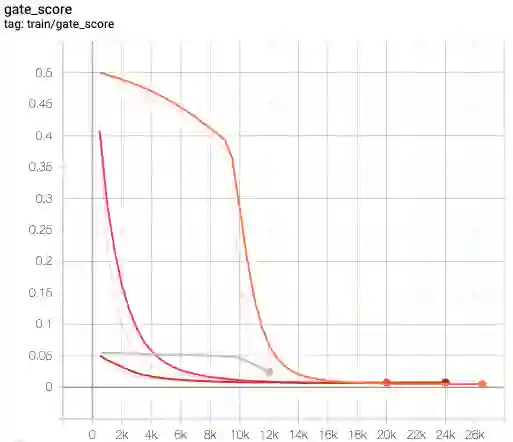
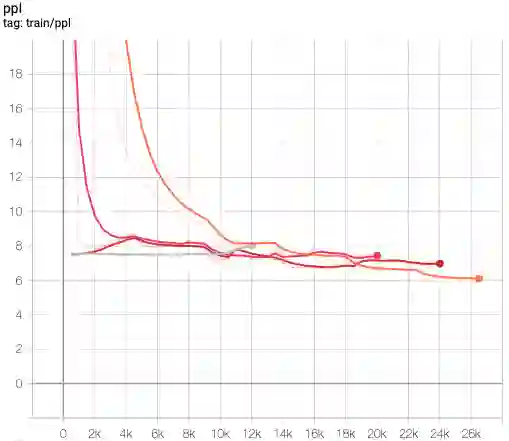
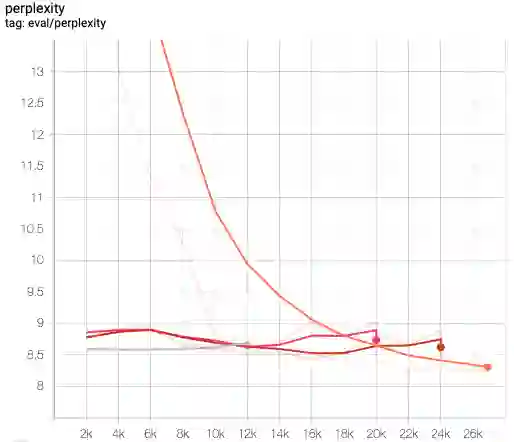
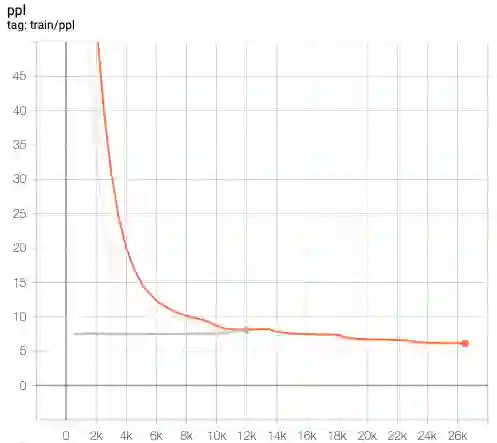
This paper presents FlowSUM, a normalizing flows-based variational encoder-decoder framework for Transformer-based summarization. Our approach tackles two primary challenges in variational summarization: insufficient semantic information in latent representations and posterior collapse during training. To address these challenges, we employ normalizing flows to enable flexible latent posterior modeling, and we propose a controlled alternate aggressive training (CAAT) strategy with an improved gate mechanism. Experimental results show that FlowSUM significantly enhances the quality of generated summaries and unleashes the potential for knowledge distillation with minimal impact on inference time. Furthermore, we investigate the issue of posterior collapse in normalizing flows and analyze how the summary quality is affected by the training strategy, gate initialization, and the type and number of normalizing flows used, offering valuable insights for future research.
翻译:本文提出FlowSUM,一种基于归一化流的变分编码器-解码器框架,用于Transformer架构的摘要生成任务。该方法针对变分摘要生成中的两个核心挑战:潜在表示中的语义信息不足以及训练过程中的后验坍缩问题。为应对这些挑战,我们采用归一化流实现灵活的后验建模,并提出一种改进门控机制的受控交替式激进训练策略。实验结果表明,FlowSUM在显著提升生成摘要质量的同时,能以最小推理时间代价释放知识蒸馏潜能。此外,我们深入探究了归一化流中的后验坍缩现象,并分析了训练策略、门控初始化方式以及归一化流类型与数量对摘要质量的影响,为后续研究提供重要启示。