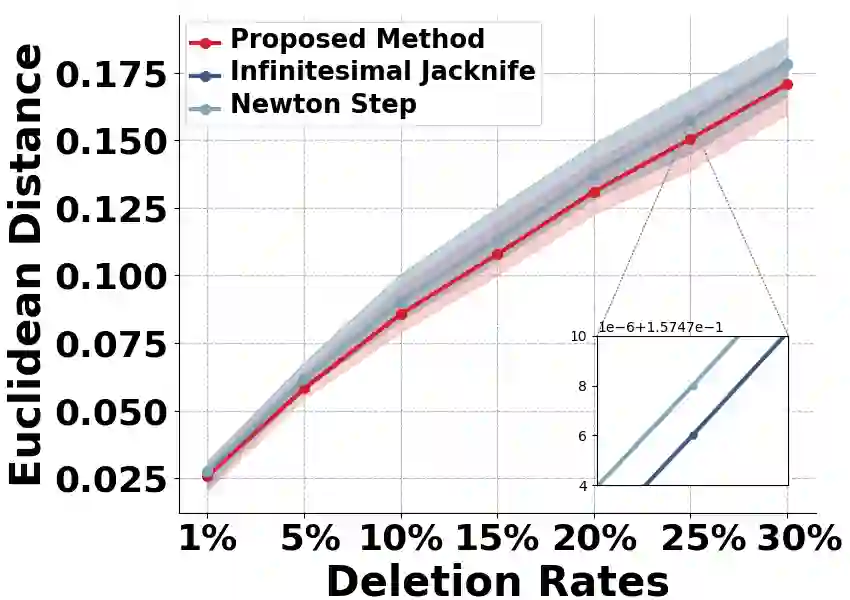
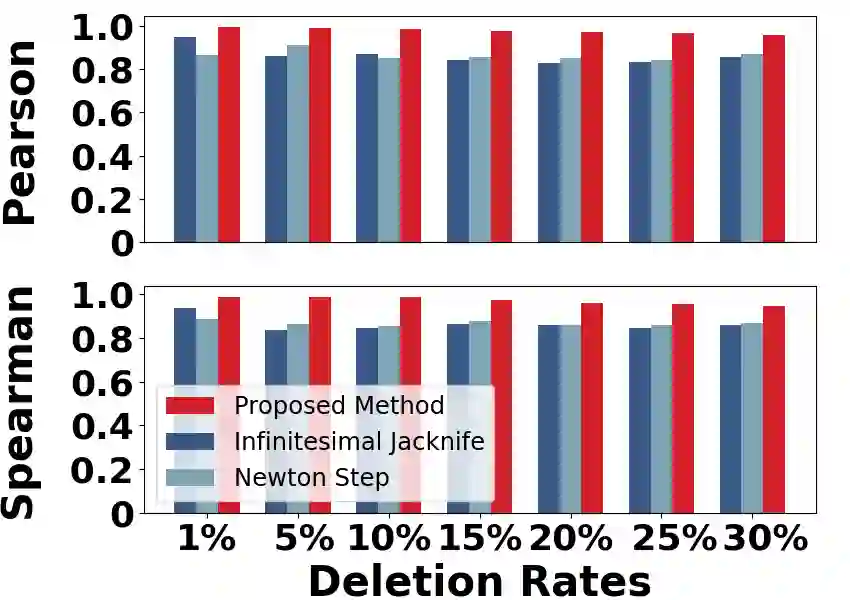
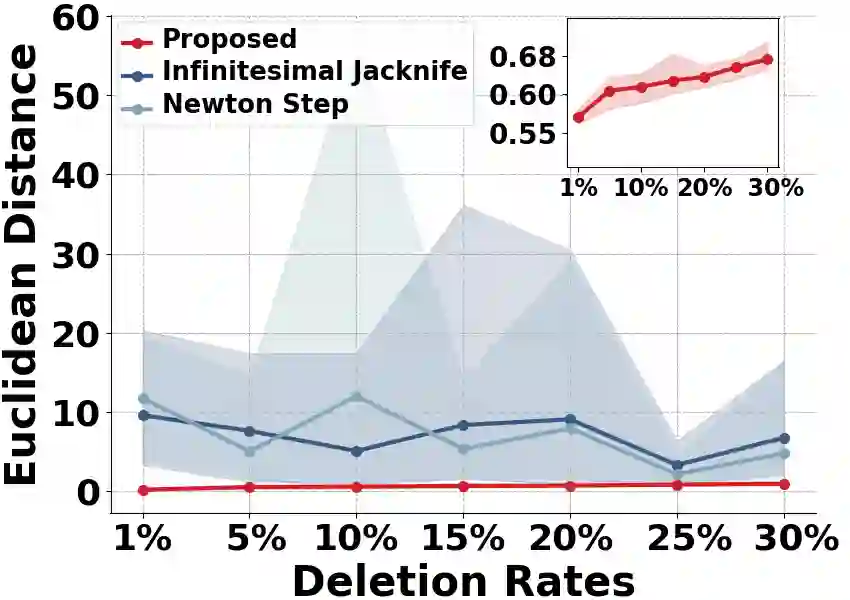
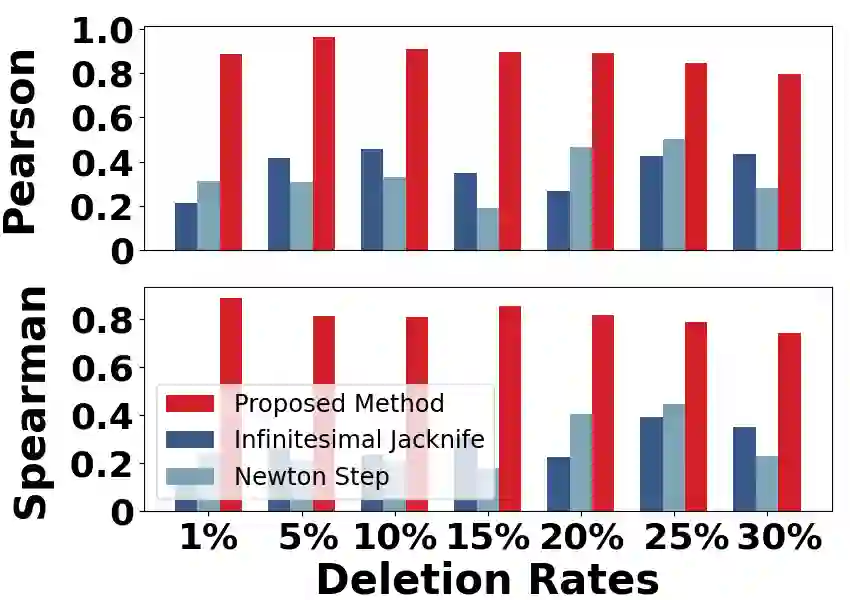
Machine unlearning strives to uphold the data owners' right to be forgotten by enabling models to selectively forget specific data. Recent advances suggest precomputing and storing statistics extracted from second-order information and implementing unlearning through Newton-style updates. However, the theoretical analysis of these works often depends on restrictive assumptions of convexity and smoothness, and those mentioned operations on Hessian matrix are extremely costly. As a result, applying these works to high-dimensional models becomes challenging. In this paper, we propose an efficient Hessian-free certified unlearning. We propose to maintain a statistical vector for each data, computed through affine stochastic recursion approximation of the difference between retrained and learned models. Our analysis does not involve inverting Hessian and thus can be extended to non-convex non-smooth objectives. Under same assumptions, we demonstrate advancements of proposed method beyond the state-of-the-art theoretical studies, in terms of generalization, unlearning guarantee, deletion capacity, and computation/storage complexity, and we show that the unlearned model of our proposed approach is close to or same as the retrained model. Based on the strategy of recollecting statistics for forgetting data, we develop an algorithm that achieves near-instantaneous unlearning as it only requires a vector addition operation. Experiments demonstrate that the proposed scheme surpasses existing results by orders of magnitude in terms of time/storage costs, while also enhancing accuracy.
翻译:机器遗忘旨在通过使模型能够选择性地遗忘特定数据,从而维护数据所有者被遗忘的权利。近期研究进展提出预计算并存储从二阶信息中提取的统计量,并通过牛顿式更新实现遗忘。然而,这些工作的理论分析通常依赖于凸性和光滑性的严格假设,且涉及Hessian矩阵的上述操作计算成本极高。因此,将这些方法应用于高维模型具有挑战性。本文提出一种高效的无Hessian认证遗忘方法。我们建议为每个数据维护一个统计向量,该向量通过重训练模型与已学习模型之间差异的仿射随机递归近似计算得到。我们的分析不涉及Hessian矩阵求逆,因此可扩展至非凸非光滑目标函数。在相同假设下,我们证明了所提方法在泛化性、遗忘保证、删除容量及计算/存储复杂度方面超越现有最先进理论研究的进展,并表明该方法得到的遗忘模型与重训练模型接近或相同。基于为待遗忘数据回溯统计量的策略,我们开发了一种算法,仅需向量加法操作即可实现近瞬时遗忘。实验表明,所提方案在时间/存储成本方面超越现有结果数个数量级,同时提升了准确性。