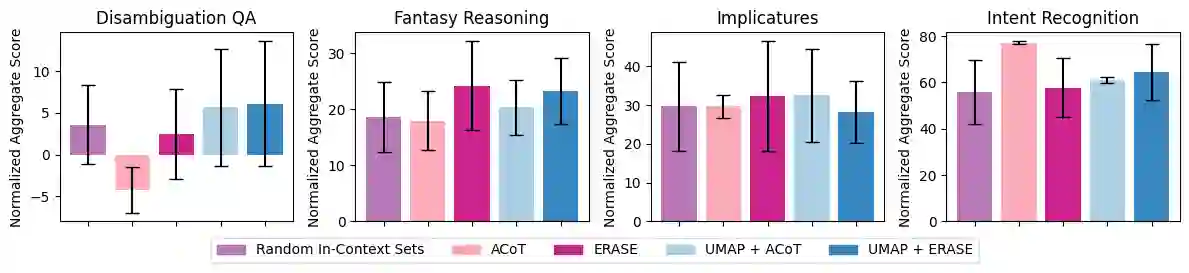
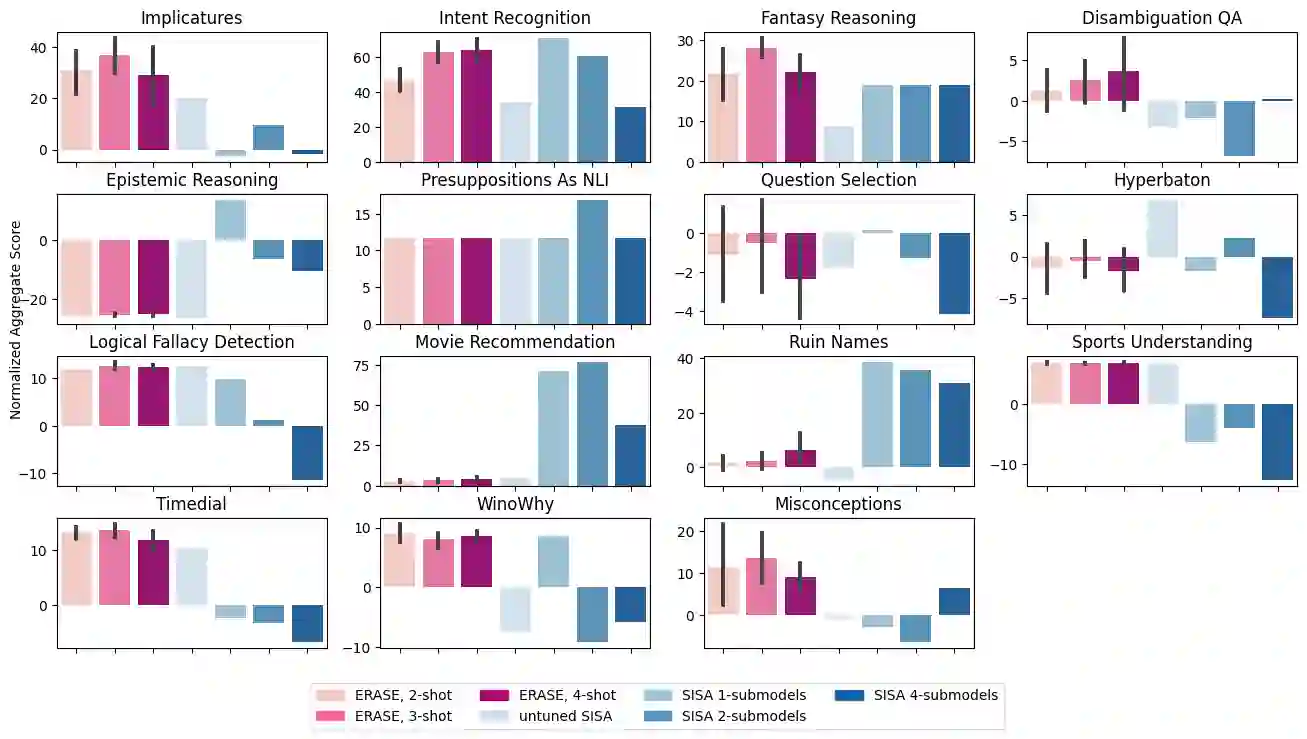
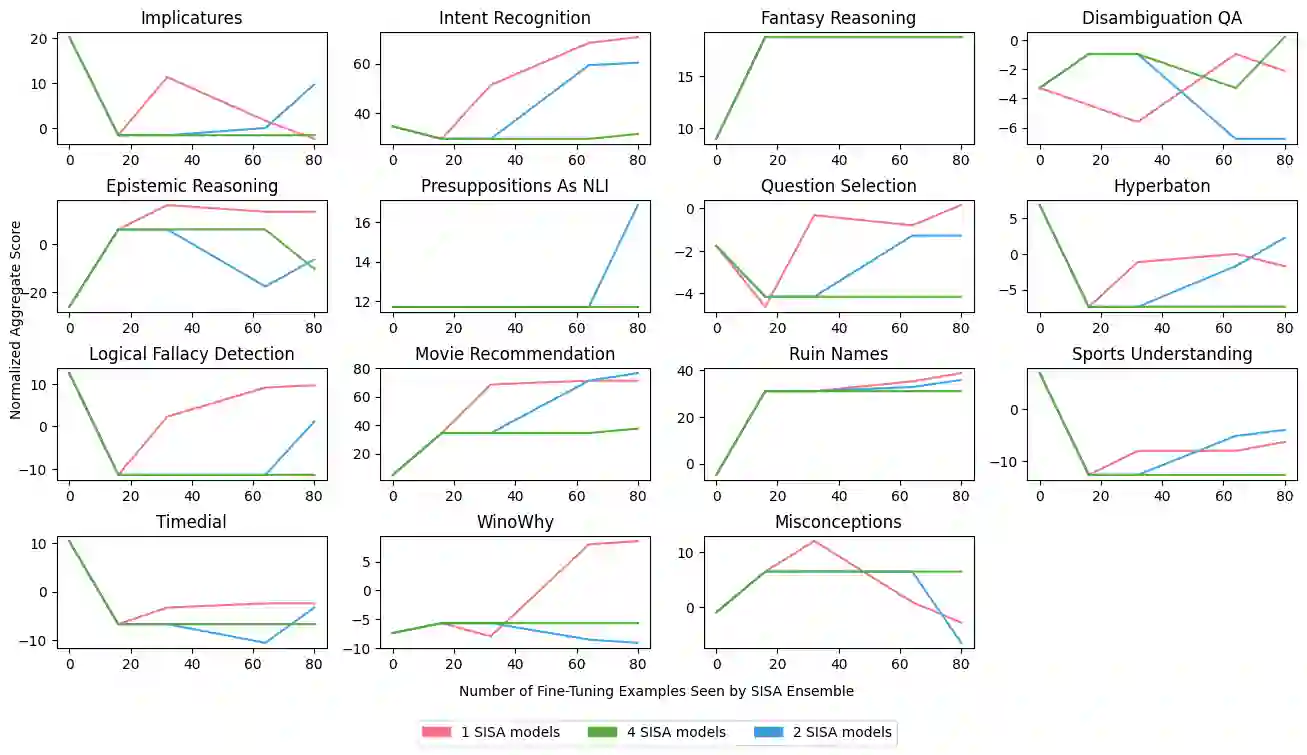
Machine unlearning is a desirable operation as models get increasingly deployed on data with unknown provenance. However, achieving exact unlearning -- obtaining a model that matches the model distribution when the data to be forgotten was never used -- is challenging or inefficient, often requiring significant retraining. In this paper, we focus on efficient unlearning methods for the task adaptation phase of a pretrained large language model (LLM). We observe that an LLM's ability to do in-context learning for task adaptation allows for efficient exact unlearning of task adaptation training data. We provide an algorithm for selecting few-shot training examples to prepend to the prompt given to an LLM (for task adaptation), ERASE, whose unlearning operation cost is independent of model and dataset size, meaning it scales to large models and datasets. We additionally compare our approach to fine-tuning approaches and discuss the trade-offs between the two approaches. This leads us to propose a new holistic measure of unlearning cost which accounts for varying inference costs, and conclude that in-context learning can often be more favourable than fine-tuning for deployments involving unlearning requests.
翻译:机器遗忘是一项理想的操作,因为模型越来越多地部署在来源不明数据上。然而,实现精确遗忘——即获得一个与从未使用待遗忘数据时模型分布相匹配的模型——是困难或低效的,通常需要大量重新训练。本文聚焦于预训练大语言模型(LLM)任务适应阶段的高效遗忘方法。我们观察到,LLM通过上下文学习实现任务适应的能力,能够高效实现任务适应训练数据的精确遗忘。我们提出了一种算法ERASE,用于选择少量训练示例并将其附加到LLM提示中(用于任务适应),其遗忘操作成本与模型和数据集规模无关,这意味着它可扩展至大型模型和数据集。此外,我们将我们的方法与微调方法进行比较,并讨论两种方法之间的权衡。这促使我们提出一种新的遗忘成本整体衡量指标,该指标考虑了不同的推理成本,并得出结论:在涉及遗忘需求的部署场景中,上下文学习通常比微调更具优势。