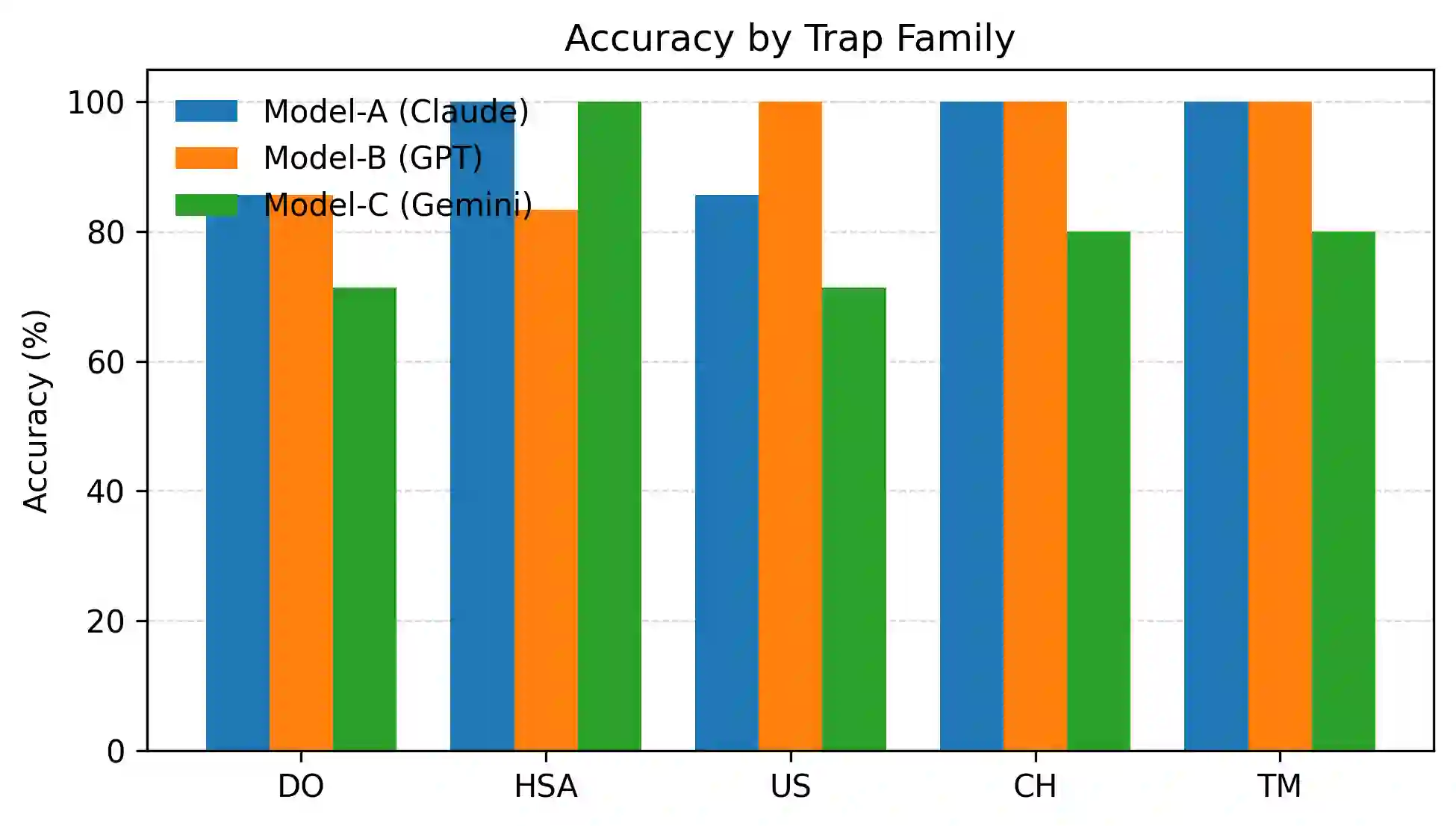
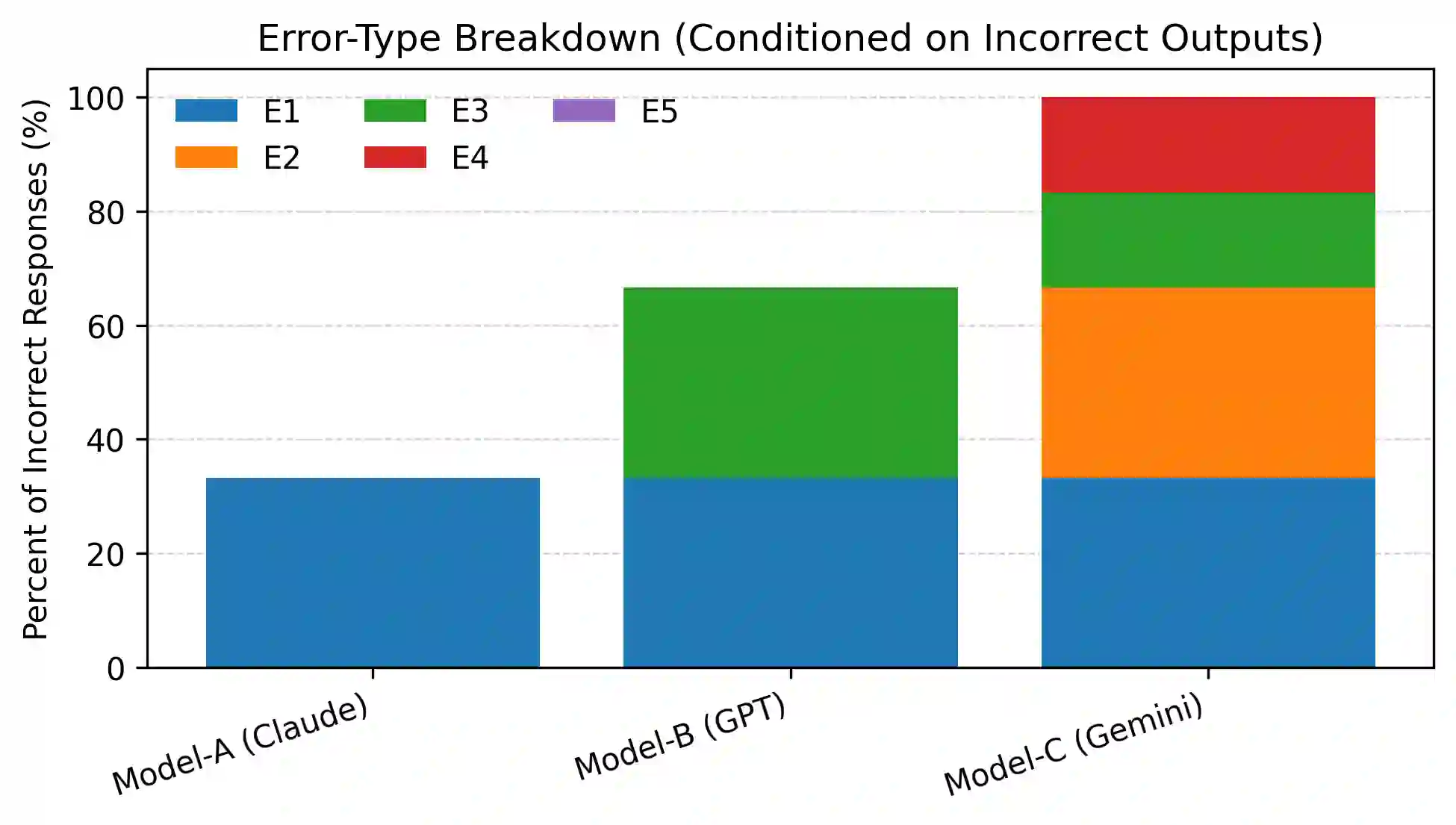
Large language models (LLMs) demonstrate strong performance on standard digital logic and Boolean reasoning tasks, yet their reliability under locally redefined semantics remains poorly understood. In many formal settings, such as circuit specifications, examinations, and hardware documentation, operators and components are explicitly redefined within narrow scope. Correct reasoning in these contexts requires models to temporarily suppress globally learned conventions in favor of prompt-local definitions. In this work, we study a systematic failure mode we term semantic override, in which an LLM reverts to its pretrained default interpretation of operators or gate behavior despite explicit redefinition in the prompt. We also identify a related class of errors, assumption injection, where models commit to unstated hardware semantics when critical details are underspecified, rather than requesting clarification. We introduce a compact micro-benchmark of 30 logic and digital-circuit reasoning tasks designed as verifier-style traps, spanning Boolean algebra, operator overloading, redefined gates, and circuit-level semantics. Evaluating three frontier LLMs, we observe persistent noncompliance with local specifications, confident but incompatible assumptions, and dropped constraints even in elementary settings. Our findings highlight a gap between surface-level correctness and specification-faithful reasoning, motivating evaluation protocols that explicitly test local unlearning and semantic compliance in formal domains.
翻译:大型语言模型(LLM)在标准数字逻辑与布尔推理任务上展现出强大性能,但其在局部重定义语义下的可靠性仍鲜为人知。在许多形式化场景中(如电路规范、考试题目和硬件文档),运算符与组件常在有限范围内被显式重定义。在这些语境中进行正确推理要求模型暂时抑制全局习得的惯例,转而遵循提示中的局部定义。本研究系统性地考察了一种我们称为语义覆盖的失效模式:尽管提示中已明确定义,LLM仍恢复至其预训练默认的运算符或逻辑门行为解释。我们还识别了一类相关错误——假设注入,即当关键细节未明确说明时,模型会自行承诺未声明的硬件语义,而非请求澄清。我们构建了一个包含30项逻辑与数字电路推理任务的微型基准测试集,其设计采用验证器式陷阱,涵盖布尔代数、运算符重载、重定义逻辑门及电路级语义。通过对三个前沿LLM的评估,我们观察到模型持续违背局部规范、自信但矛盾地注入假设,甚至在基础场景中遗漏约束条件。我们的研究揭示了表层正确性与忠实于规范推理之间的差距,这促使我们建立能显式测试形式化领域中局部遗忘与语义遵从性的评估框架。